Java 全栈知识点问题汇总(下)
提示
Java 全栈知识点问题汇总(下), Java 全栈知识点问题汇总(上)。@pdai
- Java 全栈知识点问题汇总(下)
- 9 开发基础
- 10 开发框架和中间件
- 10.1 Spring
- 什么是Spring框架?
- 列举一些重要的Spring模块?
- 什么是IOC? 如何实现的?
- 什么是AOP? 有哪些AOP的概念?
- AOP 有哪些应用场景?
- 有哪些AOP Advice通知的类型?
- AOP 有哪些实现方式?
- 谈谈你对CGLib的理解?
- Spring AOP和AspectJ AOP有什么区别?
- Spring中的bean的作用域有哪些?
- Spring中的单例bean的线程安全问题了解吗?
- Spring中的bean生命周期?
- 说说自己对于Spring MVC的了解?
- Spring MVC的工作原理了解嘛?
- Spring框架中用到了哪些设计模式?
- @Component和@Bean的区别是什么?
- 将一个类声明为Spring的bean的注解有哪些?
- Spring事务管理的方式有几种?
- Spring事务中的隔离级别有哪几种?
- Spring事务中有哪几种事务传播行为?
- Bean Factory和ApplicationContext有什么区别?
- 如何定义bean的范围?
- 可以通过多少种方式完成依赖注入?
- 10.2 Spring Boot
- 什么是SpringBoot?
- 为什么使用SpringBoot?
- Spring、Spring MVC和SpringBoot有什么区别?
- SpringBoot自动配置的原理?
- Spring Boot的核心注解是哪些?他主由哪几个注解组成的?
- SpringBoot的核心配置文件有哪几个?他们的区别是什么?
- 什么是Spring Boot Starter?有哪些常用的?
- spring-boot-starter-parent有什么作用?
- 如何自定义Spring Boot Starter?
- 为什么需要spring-boot-maven-plugin?
- SpringBoot 打成jar和普通的jar有什么区别?
- 如何使用Spring Boot实现异常处理?
- SpringBoot 实现热部署有哪几种方式?
- Spring Boot中的监视器是什么?
- Spring Boot 可以兼容老 Spring 项目吗?
- 10.3 Spring Security
- 10.4 MyBatis
- 10.5 JPA
- 10.6 日志框架
- 10.7 Tomcat
- 10.1 Spring
- 11 开发工具
- 12 架构
- 13 分布式
- 14 微服务
- 14.1 Spring Cloud
- 什么是微服务?谈谈你对微服务的理解?
- 什么是Spring Cloud?
- springcloud中的组件有那些?
- 具体说说SpringCloud主要项目?
- Spring Cloud项目部署架构?
- Spring Cloud 和dubbo区别?
- 服务注册和发现是什么意思?Spring Cloud 如何实现?
- 什么是Eureka?
- Eureka怎么实现高可用?
- 什么是Eureka的自我保护模式?
- DiscoveryClient的作用?
- Eureka和ZooKeeper都可以提供服务注册与发现的功能,请说说两个的区别?
- 什么是网关?
- 网关的作用是什么?
- 什么是Spring Cloud Zuul(服务网关)?
- 网关与过滤器有什么区别?
- 常用网关框架有那些?
- Zuul与Nginx有什么区别?
- 既然Nginx可以实现网关?为什么还需要使用Zuul框架?
- ZuulFilter常用有那些方法?
- 如何实现动态Zuul网关路由转发?
- Zuul网关如何搭建集群?
- Ribbon是什么?
- Nginx与Ribbon的区别?
- Ribbon底层实现原理?
- @LoadBalanced注解的作用?
- 什么是断路器
- 什么是 Hystrix?
- 什么是Feign?
- SpringCloud有几种调用接口方式?
- Ribbon和Feign调用服务的区别?
- 什么是 Spring Cloud Bus?
- 什么是Spring Cloud Config?
- 分布式配置中心有那些框架?
- 分布式配置中心的作用?
- SpringCloud Config 可以实现实时刷新吗?
- 什么是Spring Cloud Gateway?
- 14.2 Kubernetes
- 什么是Kubernetes? Kubernetes与Docker有什么关系?
- Kubernetes的整体架构?
- Kubernetes中有哪些核心概念?
- 什么是Heapster?
- 什么是Minikube?
- 什么是Kubectl?
- kube-apiserver和kube-scheduler的作用是什么?
- 请你说一下kubenetes针对pod资源对象的健康监测机制?
- K8s中镜像的下载策略是什么?
- image的状态有哪些?
- 如何控制滚动更新过程?
- DaemonSet资源对象的特性?
- 说说你对Job这种资源对象的了解?
- pod的重启策略是什么?
- 描述一下pod的生命周期有哪些状态?
- 创建一个pod的流程是什么?
- 删除一个Pod会发生什么事情?
- K8s的Service是什么?
- k8s是怎么进行服务注册的?
- k8s集群外流量怎么访问Pod?
- k8s数据持久化的方式有哪些?
- Replica Set 和 Replication Controller 之间有什么区别?
- 其它
- 14.3 Service Mesh
- 14.1 Spring Cloud
- 15 DevOps
- 15.1 Linux
- 什么是Linux?
- UNIX和LINUX有什么区别?
- 什么是BASH?
- 什么是Linux内核?
- 什么是LILO?
- 什么是交换空间?
- Linux的基本组件是什么?
- Linux系统安装多个桌面环境有帮助吗?
- BASH和DOS之间的基本区别是什么?
- GNU项目的重要性是什么?
- 描述root帐户?
- 如何在发出命令时打开命令提示符?
- 如何知道Linux使用了多少内存?
- Linux系统下交换分区的典型大小是多少?
- 什么是符号链接?
- Ctrl + Alt + Del组合键是否适用于Linux?
- 如何引用连接打印机等设备的并行端口?
- 硬盘驱动器和软盘驱动器等驱动器是否用驱动器号表示?
- 如何在Linux下更改权限?
- 在Linux中,为不同的串口分配了哪些名称?
- 如何在Linux下访问分区?
- 什么是硬链接?
- Linux下文件名的最大长度是多少?
- 什么是以点开头的文件名?
- 解释虚拟桌面?
- 如何在Linux下跨不同的虚拟桌面共享程序?
- 无名(空)目录代表什么?
- 什么是pwd命令?
- 什么是守护进程?
- 如何从一个桌面环境切换到另一个桌面环境,例如从KDE切换到Gnome?
- Linux下的权限有哪些?
- 区分大小写如何影响命令的使用方式?
- 是否可以使用快捷方式获取长路径名?
- 什么是重定向?
- 什么是grep命令?
- 当发出的命令与上次使用时产生的结果不同时,会出现什么问题?
- / usr / local的内容是什么?
- 你如何终止正在进行的流程?
- 如何在命令行提示符中插入注释?
- 什么是命令分组以及它是如何工作的?
- 如何从单个命令行条目执行多个命令或程序?
- 编写一个命令,查找扩展名为“c”的文件,并在其中出现字符串“apple”?
- 编写一个显示所有.txt文件的命令,包括其个人权限。
- 解释如何为Git控制台着色?
- 如何在Linux中将一个文件附加到另一个文件?
- 解释如何使用终端找到文件?
- 解释如何使用终端创建文件夹?
- 解释如何使用终端查看文本文件?
- 解释如何在Ubuntu LAMP堆栈上启用curl?
- 解释如何在Ubuntu中启用root日志记录?
- 如何在启动Linux服务器的同时在后台运行Linux程序?
- 解释如何在Linux中卸载库?
- 15.2 Docker
- 15.3 CI/CD
- 15.4 监控体系
- 15.1 Linux
- 16 其它
9 开发基础
开发基础相关。
9.1 常用类库
平时常用的开发工具库有哪些?
Apache Common
- Apache Commons是对JDK的拓展,包含了很多开源的工具,用于解决平时编程经常会遇到的问题,减少重复劳动。
Google Guava
- Guava工程包含了若干被Google的 Java项目广泛依赖 的核心库,例如:集合 [collections] 、缓存 [caching] 、原生类型支持 [primitives support] 、并发库 [concurrency libraries] 、通用注解 [common annotations] 、字符串处理 [string processing] 、I/O 等等。 所有这些工具每天都在被Google的工程师应用在产品服务中。
Hutool
- 国产后起之秀,Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相关API的学习成本,提高工作效率
Spring常用工具类
- Spring作为常用的开发框架,在Spring框架应用中,排在ApacheCommon,Guava, Huool等通用库后,第二优先级可以考虑使用Spring-core-xxx.jar中的util包
Java常用的JSON库有哪些?有啥注意点?
- FastJSON(不推荐,漏洞太多)
- Jackson
- Gson
- 序列化
- 反序列化
- 自定义序列化和反序列化
Lombok工具库用来解决什么问题?
我们通常需要编写大量代码才能使类变得有用。如以下内容:
toString()方法hashCode()andequals()方法GetterandSetter方法- 构造函数
对于这种简单的类,这些方法通常是无聊的、重复的,而且是可以很容易地机械地生成的那种东西(ide通常提供这种功能)。
@Getter/@Setter示例
@Setter(AccessLevel.PUBLIC)
@Getter(AccessLevel.PROTECTED)
private int id;
private String shap;
@ToString示例
@ToString(exclude = "id", callSuper = true, includeFieldNames = true)
public class LombokDemo {
private int id;
private String name;
private int age;
public static void main(String[] args) {
//输出LombokDemo(super=LombokDemo@48524010, name=null, age=0)
System.out.println(new LombokDemo());
}
}
@EqualsAndHashCode示例
@EqualsAndHashCode(exclude = {"id", "shape"}, callSuper = false)
public class LombokDemo {
private int id;
private String shap;
}
为什么很多公司禁止使用lombok?
可以使用而且有着广泛的使用,但是需要理解部分注解的底层和潜在问题,否则会有坑:
@Data: 如果只使用了@Data,而不使用@EqualsAndHashCode(callSuper=true)的话,会默认是@EqualsAndHashCode(callSuper=false),这时候生成的equals()方法只会比较子类的属性,不会考虑从父类继承的属性,无论父类属性访问权限是否开放。代码可读性,可调试性低 在代码中使用了Lombok,确实可以帮忙减少很多代码,因为Lombok会帮忙自动生成很多代码。但是这些代码是要在编译阶段才会生成的,所以在开发的过程中,其实很多代码其实是缺失的。
Lombok有很强的侵入性
- 强J队友,如果项目组中有一个人使用了Lombok,那么其他人就必须也要安装IDE插件。
- 如果我们需要升级到某个新版本的JDK的时候,若其中的特性在Lombok中不支持的话就会受到影响
Lombok破坏了封装性
举个简单的例子,我们定义一个购物车类:
@Data
public class ShoppingCart {
//商品数目
private int itemsCount;
//总价格
private double totalPrice;
//商品明细
private List items = new ArrayList<>();
}
//例子来源于《极客时间-设计模式之美》
我们知道,购物车中商品数目、商品明细以及总价格三者之前其实是有关联关系的,如果需要修改的话是要一起修改的。
但是,我们使用了Lombok的@Data注解,对于itemsCount 和 totalPrice这两个属性。虽然我们将它们定义成 private 类型,但是提供了 public 的 getter、setter 方法。
外部可以通过 setter 方法随意地修改这两个属性的值。我们可以随意调用 setter 方法,来重新设置 itemsCount、totalPrice 属性的值,这也会导致其跟 items 属性的值不一致。
而面向对象封装的定义是:通过访问权限控制,隐藏内部数据,外部仅能通过类提供的有限的接口访问、修改内部数据。所以,暴露不应该暴露的 setter 方法,明显违反了面向对象的封装特性。
好的做法应该是不提供getter/setter,而是只提供一个public的addItem方法,同时去修改itemsCount、totalPrice以及items三个属性。(所以不能一股脑使用@Data注解)
- 此外,Java14 提供的record语法糖,来解决类似问题
public record Range(int min, int max) {}
MapStruct工具库用来解决什么问题?
MapStruct是一款非常实用Java工具,主要用于解决对象之间的拷贝问题,比如PO/DTO/VO/QueryParam之间的转换问题。区别于BeanUtils这种通过反射,它通过编译器编译生成常规方法,将可以很大程度上提升效率。
举例:
@Mapper
public interface UserConverter {
UserConverter INSTANCE = Mappers.getMapper(UserConverter.class);
@Mapping(target = "gender", source = "sex")
@Mapping(target = "createTime", dateFormat = "yyyy-MM-dd HH:mm:ss")
UserVo do2vo(User var1);
@Mapping(target = "sex", source = "gender")
@Mapping(target = "password", ignore = true)
@Mapping(target = "createTime", dateFormat = "yyyy-MM-dd HH:mm:ss")
User vo2Do(UserVo var1);
List<UserVo> do2voList(List<User> userList);
default List<UserVo.UserConfig> strConfigToListUserConfig(String config) {
return JSON.parseArray(config, UserVo.UserConfig.class);
}
default String listUserConfigToStrConfig(List<UserVo.UserConfig> list) {
return JSON.toJSONString(list);
}
}
Lombok和MapStruct工具库的原理?
会发现在Lombok使用的过程中,只需要添加相应的注解,无需再为此写任何代码。自动生成的代码到底是如何产生的呢?
核心之处就是对于注解的解析上。JDK5引入了注解的同时,也提供了两种解析方式。
- 运行时解析
运行时能够解析的注解,必须将@Retention设置为RUNTIME, 比如@Retention(RetentionPolicy.RUNTIME),这样就可以通过反射拿到该注解。java.lang,reflect反射包中提供了一个接口AnnotatedElement,该接口定义了获取注解信息的几个方法,Class、Constructor、Field、Method、Package等都实现了该接口,对反射熟悉的朋友应该都会很熟悉这种解析方式。
- 编译时解析
编译时解析有两种机制,分别简单描述下:
1)Annotation Processing Tool
apt自JDK5产生,JDK7已标记为过期,不推荐使用,JDK8中已彻底删除,自JDK6开始,可以使用Pluggable Annotation Processing API来替换它,apt被替换主要有2点原因:
- api都在com.sun.mirror非标准包下
- 没有集成到javac中,需要额外运行
2)Pluggable Annotation Processing API
JSR 269: Pluggable Annotation Processing API自JDK6加入,作为apt的替代方案,它解决了apt的两个问题,javac在执行的时候会调用实现了该API的程序,这样我们就可以对编译器做一些增强,这时javac执行的过程如下:

Lombok本质上就是一个实现了“JSR 269 API”的程序。在使用javac的过程中,它产生作用的具体流程如下:
- javac对源代码进行分析,生成了一棵抽象语法树(AST)
- 运行过程中调用实现了“JSR 269 API”的Lombok程序
- 此时Lombok就对第一步骤得到的AST进行处理,找到@Data注解所在类对应的语法树(AST),然后修改该语法树(AST),增加getter和setter方法定义的相应树节点
- javac使用修改后的抽象语法树(AST)生成字节码文件,即给class增加新的节点(代码块)
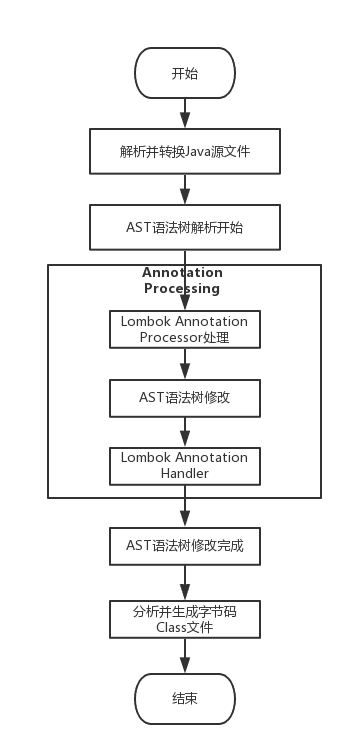
从上面的Lombok执行的流程图中可以看出,在Javac 解析成AST抽象语法树之后, Lombok 根据自己编写的注解处理器,动态地修改 AST,增加新的节点(即Lombok自定义注解所需要生成的代码),最终通过分析生成JVM可执行的字节码Class文件。使用Annotation Processing自定义注解是在编译阶段进行修改,而JDK的反射技术是在运行时动态修改,两者相比,反射虽然更加灵活一些但是带来的性能损耗更加大。
9.2 网络协议和工具
什么是754层网络模型?
全局上理解 7层协议,4层,5层的对应关系。

OSI依层次结构来划分:应用层(Application)、表示层(Presentation)、会话层(Session)、传输层(Transport)、网络层(Network)、数据链路层(Data Link)、物理层(Physical)
TCP建立连接过程的三次握手?
TCP有6种标识:SYN(建立联机) ACK(确认) PSH(传送) FIN(结束) RST(重置) URG(紧急); 然后我们来看三次握手
- 什么是三次握手?
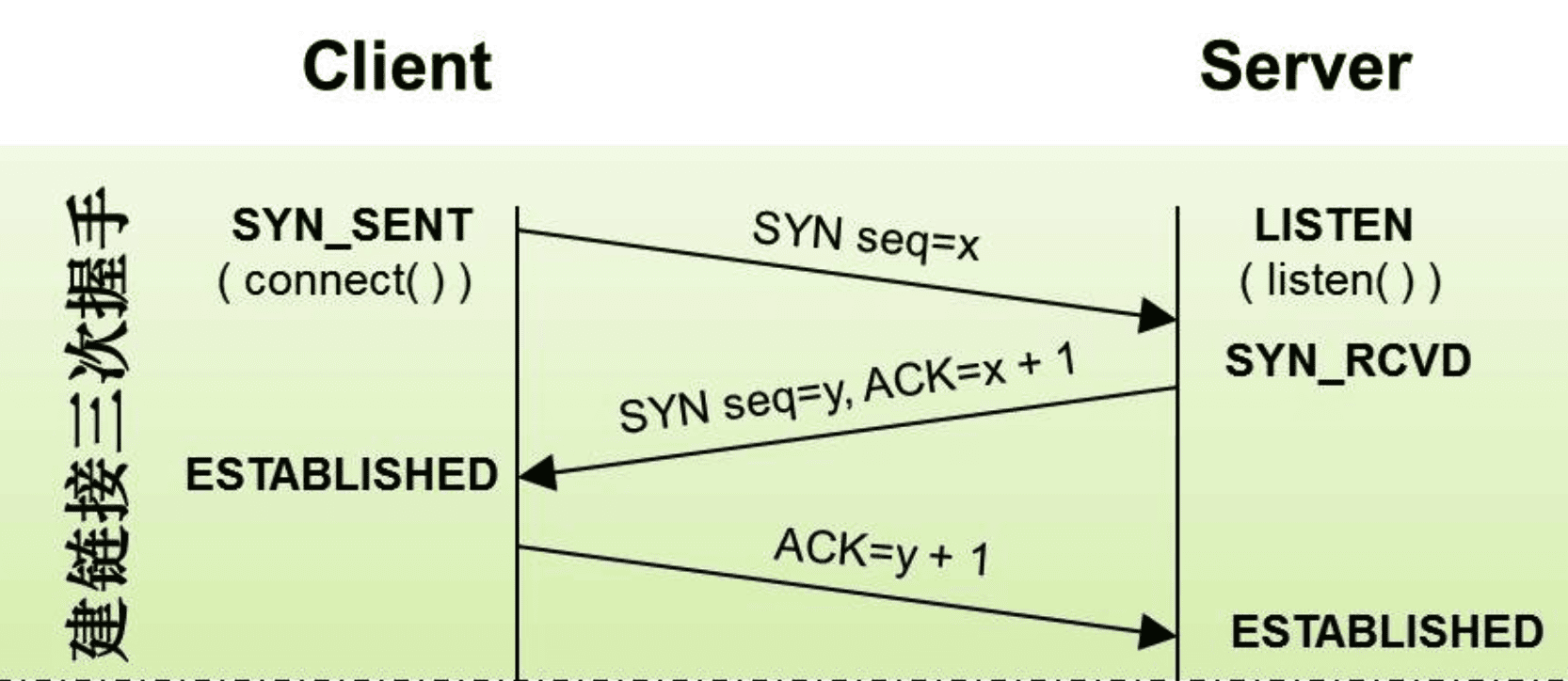
为了保证数据能到达目标,TCP采用三次握手策略:
- 发送端首先发送一个带SYN(synchronize)标志的数据包给接收方【第一次的seq序列号是随机产生的,这样是为了网络安全,如果不是随机产生初始序列号,黑客将会以很容易的方式获取到你与其他主机之间的初始化序列号,并且伪造序列号进行攻击】
- 接收端收到后,回传一个带有SYN/ACK(acknowledgement)标志的数据包以示传达确认信息【SYN 是为了告诉发送端,发送方到接收方的通道没问题;ACK 用来验证接收方到发送方的通道没问题】
- 最后,发送端再回传一个带ACK标志的数据包,代表握手结束若在握手某个过程中某个阶段莫名中断,TCP协议会再次以相同的顺序发送相同的数据包
- 为什么要三次握手?
三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的
- 第一次握手,发送端:什么都确认不了;接收端:对方发送正常,自己接受正常
- 第二次握手,发送端:对方发送,接受正常,自己发送,接受正常 ;接收端:对方发送正常,自己接受正常
- 第三次握手,发送端:对方发送,接受正常,自己发送,接受正常;接收端:对方发送,接受正常,自己发送,接受正常
- 两次握手不行吗?为什么TCP客户端最后还要发送一次确认呢?
主要防止已经失效的连接请求报文突然又传送到了服务器,从而产生错误。经典场景:客户端发送了第一个请求连接并且没有丢失,只是因为在网络结点中滞留的时间太长了。
- 由于TCP的客户端迟迟没有收到确认报文,以为服务器没有收到,此时重新向服务器发送这条报文,此后客户端和服务器经过两次握手完成连接,传输数据,然后关闭连接。
- 此时此前滞留的那一次请求连接,网络通畅了到达服务器,这个报文本该是失效的,但是,两次握手的机制将会让客户端和服务器再次建立连接,这将导致不必要的错误和资源的浪费。
- 如果采用的是三次握手,就算是那一次失效的报文传送过来了,服务端接受到了那条失效报文并且回复了确认报文,但是客户端不会再次发出确认。由于服务器收不到确认,就知道客户端并没有请求连接。
- 为什么三次握手,返回时,ack 值是 seq 加 1(ack = x+1)
- 假设对方接收到数据,比如sequence number = 1000,TCP Payload = 1000,数据第一个字节编号为1000,最后一个为1999,回应一个确认报文,确认号为2000,意味着编号2000前的字节接收完成,准备接收编号为2000及更多的数据
- 确认收到的序列,并且告诉发送端下一次发送的序列号从哪里开始(便于接收方对数据排序,便于选择重传)
- TCP三次握手中,最后一次回复丢失,会发生什么?
- 如果最后一次ACK在网络中丢失,那么Server端(服务端)该TCP连接的状态仍为SYN_RECV,并且根据 TCP的超时重传机制依次等待3秒、6秒、12秒后重新发送 SYN+ACK 包,以便 Client(客户端)重新发送ACK包
- 如果重发指定次数后,仍然未收到ACK应答,那么一段时间后,Server(服务端)自动关闭这个连接
- 但是Client(客户端)认为这个连接已经建立,如果Client(客户端)端向Server(服务端)发送数据,Server端(服务端)将以RST包(Reset,标示复位,用于异常的关闭连接)响应,此时,客户端知道第三次握手失败
SYN洪泛攻击(SYN Flood,半开放攻击),怎么解决?
- 什么是SYN洪范泛攻击?
SYN Flood利用TCP协议缺陷,发送大量伪造的TCP连接请求,常用假冒的IP或IP号段发来海量的请求连接的第一个握手包(SYN包),被攻击服务器回应第二个握手包(SYN+ACK包),因为对方是假冒IP,对方永远收不到包且不会回应第三个握手包。导致被攻击服务器保持大量SYN_RECV状态的“半连接”,并且会重试默认5次回应第二个握手包,大量随机的恶意syn占满了未完成连接队列,导致正常合法的syn排不上队列,让正常的业务请求连接不进来。【服务器端的资源分配是在二次握手时分配的,而客户端的资源是在完成三次握手时分配的,所以服务器容易受到SYN洪泛攻击】
- 如何检测 SYN 攻击?
当你在服务器上看到大量的半连接状态时,特别是源IP地址是随机的,基本上可以断定这是一次SYN攻击【在 Linux/Unix 上可以使用系统自带的 netstats 命令来检测 SYN 攻击】
- 怎么解决? SYN攻击不能完全被阻止,除非将TCP协议重新设计。我们所做的是尽可能的减轻SYN攻击的危害,
- 缩短超时(SYN Timeout)时间
- 增加最大半连接数
- 过滤网关防护
- SYN cookies技术:
- 当服务器接受到 SYN 报文段时,不直接为该 TCP 分配资源,而只是打开一个半开的套接字。接着会使用 SYN 报文段的源 Id,目的 Id,端口号以及只有服务器自己知道的一个秘密函数生成一个 cookie,并把 cookie 作为序列号响应给客户端。
- 如果客户端是正常建立连接,将会返回一个确认字段为 cookie + 1 的报文段。接下来服务器会根据确认报文的源 Id,目的 Id,端口号以及秘密函数计算出一个结果,如果结果的值 + 1 等于确认字段的值,则证明是刚刚请求连接的客户端,这时候才为该 TCP 分配资源
TCP断开连接过程的四次挥手?
- 什么是四次挥手?
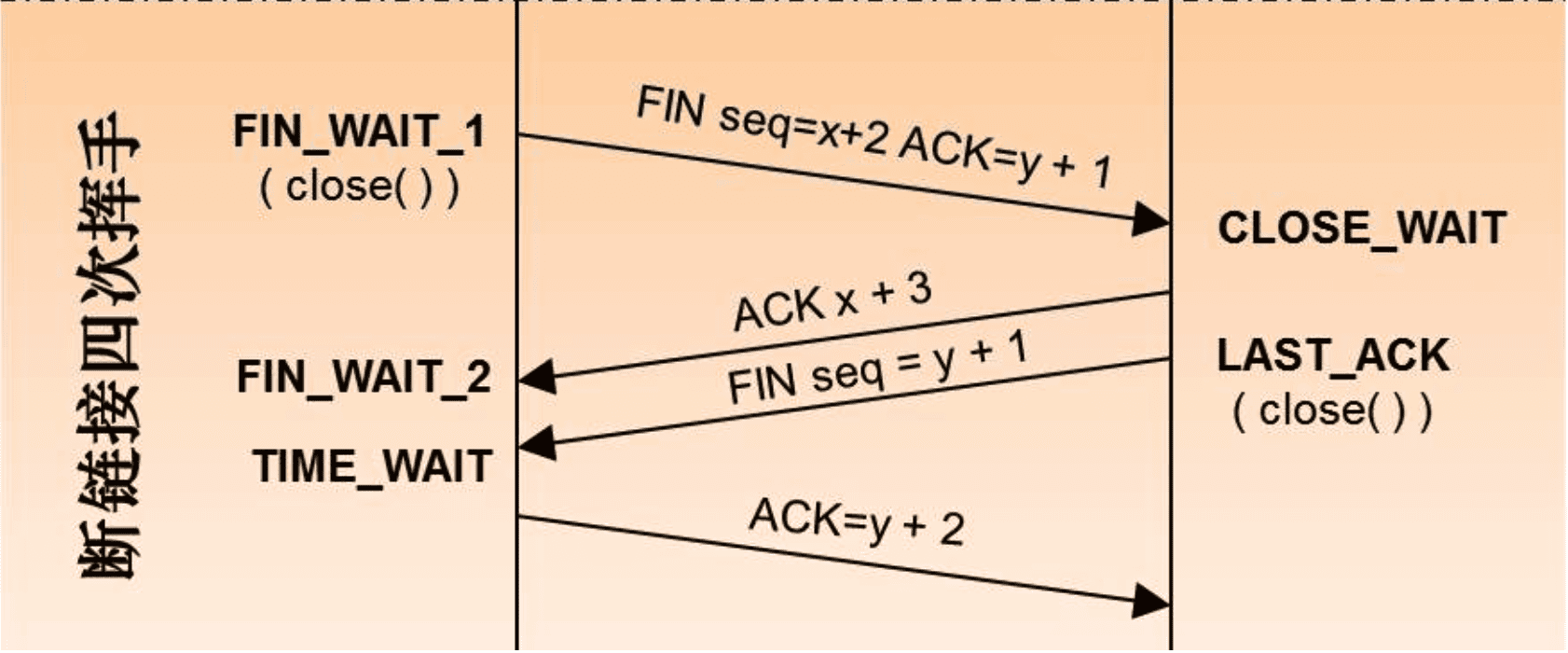
- 主动断开方(客户端/服务端)-发送一个 FIN,用来关闭主动断开方(客户端/服务端)到被动断开方(客户端/服务端)的数据传送
- 被动断开方(客户端/服务端)-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加1 。和 SYN 一样,一个 FIN 将占用一个序号
- 被动断开方(客户端/服务端)-关闭与主动断开方(客户端/服务端)的连接,发送一个FIN给主动断开方(客户端/服务端)
- 主动断开方(客户端/服务端)-发回 ACK 报文确认,并将确认序号设置为收到序号加1
- 为什么连接的时候是三次握手,关闭的时候却是四次握手?
- 建立连接的时候, 服务器在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。
- 关闭连接时,服务器收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,而自己也未必全部数据都发送给对方了,所以服务器可以立即关闭,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接。因此,服务器ACK和FIN一般都会分开发送,从而导致多了一次。
- 为什么TCP挥手每两次中间有一个 FIN-WAIT2等待时间?
主动关闭的一端调用完close以后(即发FIN给被动关闭的一端, 并且收到其对FIN的确认ACK)则进入FIN_WAIT_2状态。如果这个时候因为网络突然断掉、被动关闭的一段宕机等原因,导致主动关闭的一端不能收到被动关闭的一端发来的FIN(防止对端不发送关闭连接的FIN包给本端),这个时候就需要FIN_WAIT_2定时器, 如果在该定时器超时的时候,还是没收到被动关闭一端发来的FIN,那么直接释放这个链接,进入CLOSE状态
- 为什么客户端最后还要等待2MSL?为什么还有个TIME-WAIT的时间等待?
- 保证客户端发送的最后一个ACK报文能够到达服务器,因为这个ACK报文可能丢失,服务器已经发送了FIN+ACK报文,请求断开,客户端却没有回应,于是服务器又会重新发送一次,而客户端就能在这个2MSL时间段内收到这个重传的报文,接着给出回应报文,并且会重启2MSL计时器。
- 防止类似与“三次握手”中提到了的“已经失效的连接请求报文段”出现在本连接中。客户端发送完最后一个确认报文后,在这个2MSL时间中,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失,这样新的连接中不会出现旧连接的请求报文。
- 2MSL,最大报文生存时间,一个MSL 30 秒,2MSL = 60s
- 客户端 TIME-WAIT 状态过多会产生什么后果?怎样处理?
作为服务器,短时间内关闭了大量的Client连接,就会造成服务器上出现大量的TIME_WAIT连接,占据大量的tuple /tApl/ ,严重消耗着服务器的资源,此时部分客户端就会显示连接不上
作为客户端,短时间内大量的短连接,会大量消耗的Client机器的端口,毕竟端口只有65535个,端口被耗尽了,后续就无法在发起新的连接了
在高并发短连接的TCP服务器上,当服务器处理完请求后立刻主动正常关闭连接。这个场景下会出现大量socket处于TIME_WAIT状态。如果客户端的并发量持续很高,此时部分客户端就会显示连接不上
- 高并发可以让服务器在短时间范围内同时占用大量端口,而端口有个0~65535的范围,并不是很多,刨除系统和其他服务要用的,剩下的就更少了
- 短连接表示“业务处理+传输数据的时间 远远小于 TIMEWAIT超时的时间”的连接
解决方法:
- 用负载均衡来抗这些高并发的短请求;
- 服务器可以设置 SO_REUSEADDR 套接字选项来避免 TIME_WAIT状态,TIME_WAIT 状态可以通过优化服务器参数得到解决,因为发生TIME_WAIT的情况是服务器自己可控的,要么就是对方连接的异常,要么就是自己没有迅速回收资源,总之不是由于自己程序错误导致的
- 强制关闭,发送 RST 包越过TIMEWAIT状态,直接进入CLOSED状态
- 服务器出现了大量 CLOSE_WAIT 状态如何解决?
大量 CLOSE_WAIT 表示程序出现了问题,对方的 socket 已经关闭连接,而我方忙于读或写没有及时关闭连接,需要检查代码,特别是释放资源的代码,或者是处理请求的线程配置。
- 服务端会有一个TIME_WAIT状态吗?如果是服务端主动断开连接呢?
- 发起链接的主动方基本都是客户端,但是断开连接的主动方服务器和客户端都可以充当,也就是说,只要是主动断开连接的,就会有 TIME_WAIT状态
- 四次挥手是指断开一个TCP连接时,需要客户端和服务端总共发送4个包以确认连接的断开。在socket编程中,这一过程由客户端或服务端任一方执行close来触发
- 由于TCP连接时全双工的,因此,每个方向的数据传输通道都必须要单独进行关闭。
DNS 解析流程?
.com.fi国际金融域名DNS解析的步骤一共分为9步,如果每次解析都要走完9个步骤,大家浏览网站的速度也不会那么快,现在之所以能保持这么快的访问速度,其实一般的解析都是跑完第4步就可以了。除非一个地区完全是第一次访问(在都没有缓存的情况下)才会走完9个步骤,这个情况很少。
- 1、本地客户机提出域名解析请求,查找本地HOST文件后将该请求发送给本地的域名服务器。
- 2、将请求发送给本地的域名服务器。
- 3、当本地的域名服务器收到请求后,就先查询本地的缓存。
- 4、如果有该纪录项,则本地的域名服务器就直接把查询的结果返回浏览器。
- 5、如果本地DNS缓存中没有该纪录,则本地域名服务器就直接把请求发给根域名服务器。
- 6、然后根域名服务器再返回给本地域名服务器一个所查询域(根的子域)的主域名服务器的地址。
- 7、本地服务器再向上一步返回的域名服务器发送请求,然后接受请求的服务器查询自己的缓存,如果没有该纪录,则返回相关的下级的域名服务器的地址。
- 8、重复第7步,直到找到正确的纪录。
- 9、本地域名服务器把返回的结果保存到缓存,以备下一次使用,同时还将结果返回给客户机。
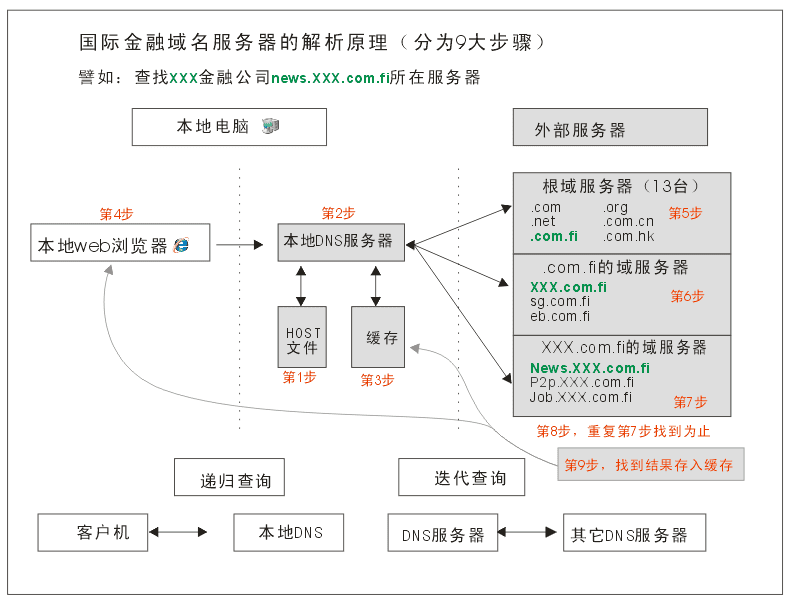
注意事项:
递归查询:在该模式下DNS服务器接收到客户机请求,必须使用一个准确的查询结果回复客户机。如果DNS服务器本地没有存储查询DNS信息,那么该服务器会询问其他服务器,并将返回的查询结果提交给客户机。
迭代查询:DNS所在服务器若没有可以响应的结果,会向客户机提供其他能够解析查询请求的DNS服务器地址,当客户机发送查询请求时,DNS服务器并不直接回复查询结果,而是告诉客户机另一台DNS服务器地址,客户机再向这台DNS服务器提交请求,依次循环直到返回查询的结果为止。
为什么DNS通常基于UDP?
DNS通常是基于UDP的,但当数据长度大于512字节的时候,为了保证传输质量,就会使用基于TCP的实现方式
- 从数据包的数量以及占有网络资源的层面
使用基于UDP的DNS协议只要一个请求、一个应答就好了; 而使用基于TCP的DNS协议要三次握手、发送数据以及应答、四次挥手; 明显基于TCP协议的DNS更浪费网络资源!
- 从数据一致性层面
DNS数据包不是那种大数据包,所以使用UDP不需要考虑分包,如果丢包那么就是全部丢包,如果收到了数据,那就是收到了全部数据!所以只需要考虑丢包的情况,那就算是丢包了,重新请求一次就好了。而且DNS的报文允许填入序号字段,对于请求报文和其对应的应答报文,这个字段是相同的,通过它可以区分DNS应答是对应的哪个请求
什么是DNS劫持?
DNS劫持就是通过劫持了DNS服务器,通过某些手段取得某域名的解析记录控制权,进而修改此域名的解析结果,导致对该域名的访问由原IP地址转入到修改后的指定IP,其结果就是对特定的网址不能访问或访问的是假网址,从而实现窃取资料或者破坏原有正常服务的目的。DNS劫持通过篡改DNS服务器上的数据返回给用户一个错误的查询结果来实现的。
- DNS劫持症状
在某些地区的用户在成功连接宽带后,首次打开任何页面都指向ISP提供的“电信互联星空”、“网通黄页广告”等内容页面。还有就是曾经出现过用户访问Google域名的时候出现了百度的网站。这些都属于DNS劫持。
什么是DNS污染?
DNS污染是一种让一般用户由于得到虚假目标主机IP而不能与其通信的方法,是一种DNS缓存投毒攻击(DNS cache poisoning)。其工作方式是:由于通常的DNS查询没有任何认证机制,而且DNS查询通常基于的UDP是无连接不可靠的协议,因此DNS的查询非常容易被篡改,通过对UDP端口53上的DNS查询进行入侵检测,一经发现与关键词相匹配的请求则立即伪装成目标域名的解析服务器(NS,Name Server)给查询者返回虚假结果。
而DNS污染则是发生在用户请求的第一步上,直接从协议上对用户的DNS请求进行干扰。
DNS污染症状:
目前一些被禁止访问的网站很多就是通过DNS污染来实现的,例如YouTube、Facebook等网站。
解决方法:
- 对于DNS劫持,可以采用使用国外免费公用的DNS服务器解决。例如OpenDNS(208.67.222.222)或GoogleDNS(8.8.8.8)。
- 对于DNS污染,可以说,个人用户很难单单靠设置解决,通常可以使用VPN或者域名远程解析的方法解决,但这大多需要购买付费的VPN或SSH等,也可以通过修改Hosts的方法,手动设置域名正确的IP地址。
为什么要DNS流量监控?
预示网络中正出现可疑或恶意代码的 DNS 组合查询或流量特征。例如:
1.来自伪造源地址的 DNS 查询、或未授权使用且无出口过滤地址的 DNS 查询,若同时观察到异常大的 DNS 查询量或使用 TCP 而非 UDP 进行 DNS 查询,这可能表明网络内存在被感染的主机,受到了 DDoS 攻击。
2.异常 DNS 查询可能是针对域名服务器或解析器(根据目标 IP 地址确定)的漏洞攻击的标志。与此同时,这些查询也可能表明网络中有不正常运行的设备。原因可能是恶意软件或未能成功清除恶意软件。
3.在很多情况下,DNS 查询要求解析的域名如果是已知的恶意域名,或具有域名生成算法( DGA )(与非法僵尸网络有关)常见特征的域名,或者向未授权使用的解析器发送的查询,都是证明网络中存在被感染主机的有力证据。
4.DNS 响应也能显露可疑或恶意数据在网络主机间传播的迹象。例如,DNS 响应的长度或组合特征可以暴露恶意或非法行为。例如,响应消息异常巨大(放大攻击),或响应消息的 Answer Section 或 Additional Section 非常可疑(缓存污染,隐蔽通道)。
5.针对自身域名组合的 DNS 响应,如果解析至不同于你发布在授权区域中的 IP 地址,或来自未授权区域主机的域名服务器的响应,或解析为名称错误( NXDOMAIN )的对区域主机名的肯定响应,均表明域名或注册账号可能被劫持或 DNS 响应被篡改。
6.来自可疑 IP 地址的 DNS 响应,例如来自分配给宽带接入网络 IP 段的地址、非标准端口上出现的 DNS 流量,异常大量的解析至短生存时间( TTL )域名的响应消息,或异常大量的包含“ name error ”( NXDOMAIN )的响应消息,往往是主机被僵尸网络控制、运行恶意软件或被感染的表现。
输入URL 到页面加载过程?
- 地址栏输入URL
- DNS 域名解析IP
- 请求和响应数据
- 建立TCP连接(3次握手)
- 发送HTTP请求
- 服务器处理请求
- 返回HTTP响应结果
- 关闭TCP连接(4次挥手)
- 浏览器加载,解析和渲染
下图是在数据传输过程中的工作方式,在发送端是应用层-->链路层这个方向的封包过程,每经过一层都会增加该层的头部。而接收端则是从链路层-->应用层解包的过程,每经过一层则会去掉相应的首部。

如何使用netstat查看服务及监听端口?
netstat -t/-u/-l/-r/-n【显示网络相关信息,-t:TCP协议,-u:UDP协议,-l:监听,-r:路由,-n:显示IP地址和端口号】
- 查看本机监听的端口
[root@pdai-centos ~]# netstat -tlun
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN
udp 0 0 172.21.0.14:123 0.0.0.0:*
udp 0 0 127.0.0.1:123 0.0.0.0:*
udp6 0 0 fe80::5054:ff:fe2b::123 :::*
udp6 0 0 ::1:123 :::*
如何使用TCPDump抓包?
tcpdump 是一款强大的网络抓包工具,它使用 libpcap 库来抓取网络数据包,这个库在几乎在所有的 Linux/Unix 中都有。
tcpdump 的常用参数如下:
$ tcpdump -i eth0 -nn -s0 -v port 80
- -i : 选择要捕获的接口,通常是以太网卡或无线网卡,也可以是 vlan 或其他特殊接口。如果该系统上只有一个网络接口,则无需指定。
- -nn : 单个 n 表示不解析域名,直接显示 IP;两个 n 表示不解析域名和端口。这样不仅方便查看 IP 和端口号,而且在抓取大量数据时非常高效,因为域名解析会降低抓取速度。
- -s0 : tcpdump 默认只会截取前 96 字节的内容,要想截取所有的报文内容,可以使用
-s number, number 就是你要截取的报文字节数,如果是 0 的话,表示截取报文全部内容。 - -v : 使用
-v,-vv和-vvv来显示更多的详细信息,通常会显示更多与特定协议相关的信息。 port 80: 这是一个常见的端口过滤器,表示仅抓取 80 端口上的流量,通常是 HTTP。
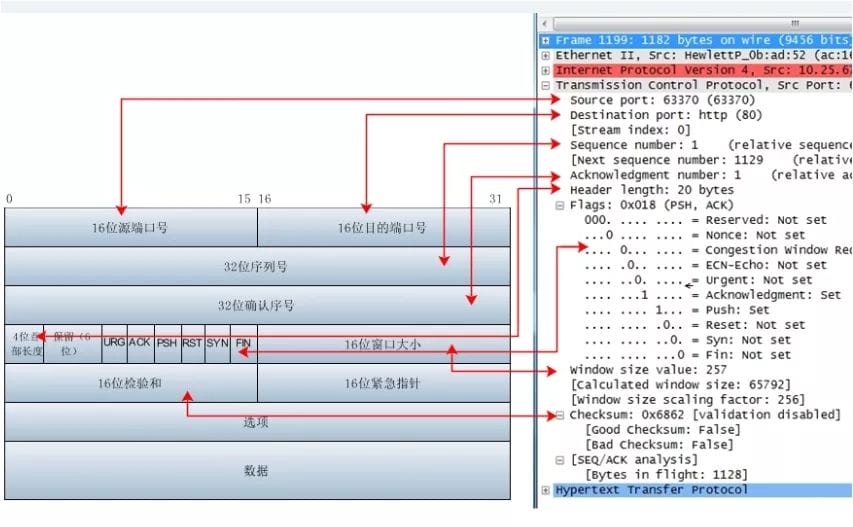
如何使用Wireshark抓包分析?
Wireshark(前称Ethereal)是一个网络封包分析软件。网络封包分析软件的功能是撷取网络封包,并尽可能显示出最为详细的网络封包资料。Wireshark使用WinPCAP作为接口,直接与网卡进行数据报文交换。
首先看下TCP报文首部,和wireshark捕获到的TCP包中的每个字段如下图所示:
9.3 开发安全
开发中有哪些常见的Web安全漏洞?
通过OWASP Top 10来回答

2013版至2017版,应用程序的基础技术和结构发生了重大变化:
- 使用node.js和Spring Boot构建的微服务正在取代传统的单任务应用,微服务本身具有自己的安全挑战,包括微服务间互信、容器 工具、保密管理等等。原来没人期望代码要实现基于互联网的房屋,而现在这些代码就在API或RESTful服务的后面,提供给移动 应用或单页应用(SPA)的大量使用。代码构建时的假设,如受信任的调用等等,再也不存在了。
- 使用JavaScript框架(如:Angular和React)编写的单页应用程序,允许创建高度模块化的前端用户体验;原来交付服务器端处理 的功能现在变为由客户端处理,但也带来了安全挑战。
- JavaScript成为网页上最基本的语言。Node.js运行在服务器端,采用现代网页框架的Bootstrap、Electron、Angular和React则运 行在客户端。
什么是注入攻击?举例说明?
- 什么是注入攻击?从具体的SQL注入说?
重点看这条SQL,密码输入: ' OR '1'='1时,等同于不需要密码
String sql = "SELECT * FROM t_user WHERE username='"+userName+"' AND pwd='"+password+"'";
- 如何解决注入攻击,比如SQL注入?
- 使用预编译处理输入参数:要防御 SQL 注入,用户的输入就不能直接嵌套在 SQL 语句当中。使用参数化的语句,用户的输入就被限制于一个参数当中, 比如用prepareStatement
- 输入验证:检查用户输入的合法性,以确保输入的内容为正常的数据。数据检查应当在客户端和服务器端都执行,之所以要执行服务器端验证,是因为客户端的校验往往只是减轻服务器的压力和提高对用户的友好度,攻击者完全有可能通过抓包修改参数或者是获得网页的源代码后,修改验证合法性的脚本(或者直接删除脚本),然后将非法内容通过修改后的表单提交给服务器等等手段绕过客户端的校验。因此,要保证验证操作确实已经执行,唯一的办法就是在服务器端也执行验证。但是这些方法很容易出现由于过滤不严导致恶意攻击者可能绕过这些过滤的现象,需要慎重使用。
- 错误消息处理:防范 SQL 注入,还要避免出现一些详细的错误消息,恶意攻击者往往会利用这些报错信息来判断后台 SQL 的拼接形式,甚至是直接利用这些报错注入将数据库中的数据通过报错信息显示出来。
- 加密处理:将用户登录名称、密码等数据加密保存。加密用户输入的数据,然后再将它与数据库中保存的数据比较,这相当于对用户输入的数据进行了“消毒”处理,用户输入的数据不再对数据库有任何特殊的意义,从而也就防止了攻击者注入 SQL 命令。
- 还有哪些注入?
- xPath注入,XPath 注入是指利用 XPath 解析器的松散输入和容错特性,能够在 URL、表单或其它信息上附带恶意的 XPath 查询代码,以获得权限信息的访问权并更改这些信息
- 命令注入,Java中
System.Runtime.getRuntime().exec(cmd);可以在目标机器上执行命令,而构建参数的过程中可能会引发注入攻击 - LDAP注入
- CLRF注入
- email注入
- Host注入
什么是CSRF?举例说明并给出开发中解决方案?
你这可以这么理解CSRF攻击:攻击者盗用了你的身份,以你的名义发送恶意请求。
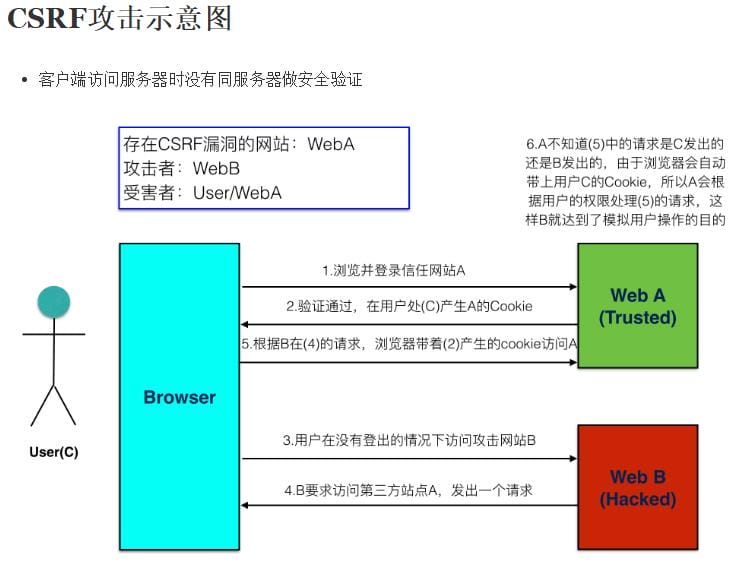
- 黑客能拿到Cookie吗?
CSRF 攻击是黑客借助受害者的 cookie 骗取服务器的信任,但是黑客并不能拿到 cookie,也看不到 cookie 的内容。
对于服务器返回的结果,由于浏览器同源策略的限制,黑客也无法进行解析。因此,黑客无法从返回的结果中得到任何东西,他所能做的就是给服务器发送请求,以执行请求中所描述的命令,在服务器端直接改变数据的值,而非窃取服务器中的数据。
- 什么样的请求是要CSRF保护?
为什么有些框架(比如Spring Security)里防护CSRF的filter限定的Method是POST/PUT/DELETE等,而没有限定GET Method?
我们要保护的对象是那些可以直接产生数据改变的服务,而对于读取数据的服务,则不需要进行 CSRF 的保护。通常而言GET请作为请求数据,不作为修改数据,所以这些框架没有拦截Get等方式请求。比如银行系统中转账的请求会直接改变账户的金额,会遭到 CSRF 攻击,需要保护。而查询余额是对金额的读取操作,不会改变数据,CSRF 攻击无法解析服务器返回的结果,无需保护。
- 为什么对请求做了CSRF拦截,但还是会报CRSF漏洞?
为什么我在前端已经采用POST+CSRF Token请求,后端也对POST请求做了CSRF Filter,但是渗透测试中还有CSRF漏洞?
直接看下面代码。
// 这里没有限制POST Method,导致用户可以不通过POST请求提交数据。
@RequestMapping("/url")
public ReponseData saveSomething(XXParam param){
// 数据保存操作...
}
PS:这一点是很容易被忽视的,在笔者经历过的几个项目的渗透测试中,多次出现。@pdai
- 有哪些CSRF 防御常规思路?
- 验证 HTTP Referer 字段, 根据 HTTP 协议,在 HTTP 头中有一个字段叫 Referer,它记录了该 HTTP 请求的来源地址。只需要验证referer
- 在请求地址中添加 token 并验证,可以在 HTTP 请求中以参数的形式加入一个随机产生的 token,并在服务器端建立一个拦截器来验证这个 token,如果请求中没有 token 或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。 这种方法要比检查 Referer 要安全一些,token 可以在用户登陆后产生并放于 session 之中,然后在每次请求时把 token 从 session 中拿出,与请求中的 token 进行比对,但这种方法的难点在于如何把 token 以参数的形式加入请求。
- 在 HTTP 头中自定义属性并验证
- 开发中如何防御CSRF?
可以通过自定义xxxCsrfFilter去拦截实现, 这里建议你参考 Spring Security - org.springframework.security.web.csrf.CsrfFilter.java。
什么是XSS?举例说明?
通常XSS攻击分为:反射型xss攻击, 存储型xss攻击 和 DOM型xss攻击。同时注意以下例子只是简单的向你解释这三种类型的攻击方式而已,实际情况比这个复杂,具体可以再结合最后一节深入理解。
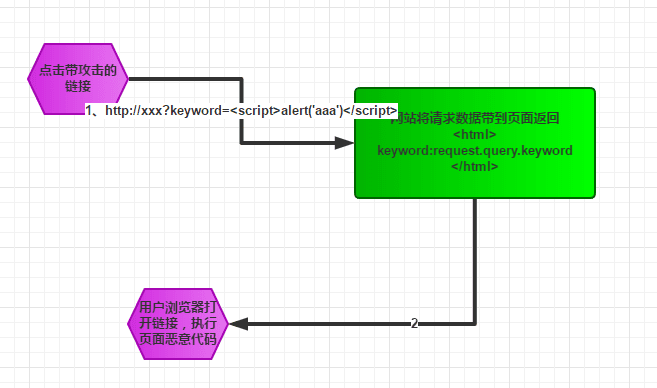
- 反射型xss攻击?
反射型的攻击需要用户主动的去访问带攻击的链接,攻击者可以通过邮件或者短信的形式,诱导受害者点开链接。如果攻击者配合短链接URL,攻击成功的概率会更高。
在一个反射型XSS攻击中,恶意文本属于受害者发送给网站的请求中的一部分。随后网站又把恶意文本包含进用于响应用户的返回页面中,发还给用户。
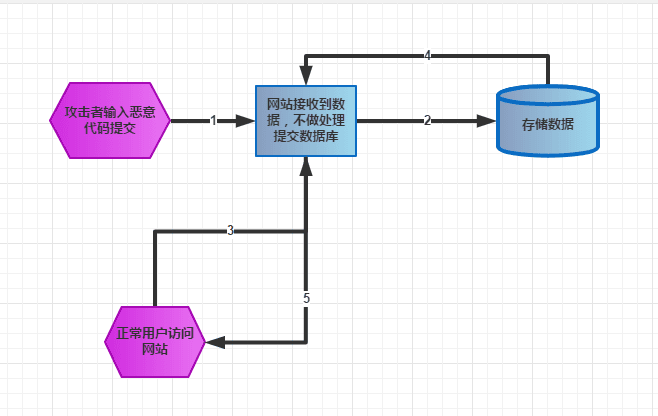
- 存储型xss攻击?
这种攻击方式恶意代码会被存储在数据库中,其他用户在正常访问的情况下,也有会被攻击,影响的范围比较大。
- DOM型xss攻击?
基于DOM的XSS攻击是反射型攻击的变种。服务器返回的页面是正常的,只是我们在页面执行js的过程中,会把攻击代码植入到页面中。
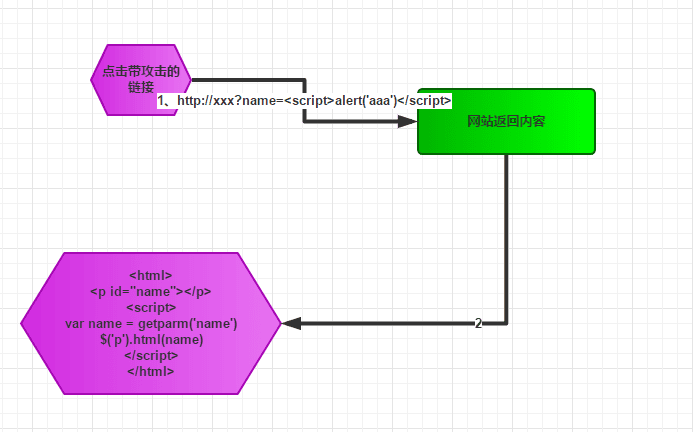
- XSS 攻击的防御?
XSS攻击其实就是代码的注入。用户的输入被编译成恶意的程序代码。所以,为了防范这一类代码的注入,需要确保用户输入的安全性。对于攻击验证,我们可以采用以下两种措施:
- 编码,就是转义用户的输入,把用户的输入解读为数据而不是代码
- 校验,对用户的输入及请求都进行过滤检查,如对特殊字符进行过滤,设置输入域的匹配规则等。
具体比如:
- 对于验证输入,我们既可以在
服务端验证,也可以在客户端验证 - 对于持久性和反射型攻击,
服务端验证是必须的,服务端支持的任何语言都能够做到 - 对于基于DOM的XSS攻击,验证输入在客户端必须执行,因为从服务端来说,所有发出的页面内容是正常的,只是在客户端js代码执行的过程中才发生可攻击
- 但是对于各种攻击方式,我们最好做到客户端和服务端都进行处理。
其它还有一些辅助措施,比如:
- 入参长度限制: 通过以上的案例我们不难发现xss攻击要能达成往往需要较长的字符串,因此对于一些可以预期的输入可以通过限制长度强制截断来进行防御。
- 设置cookie httponly为true(具体请看下文的解释)
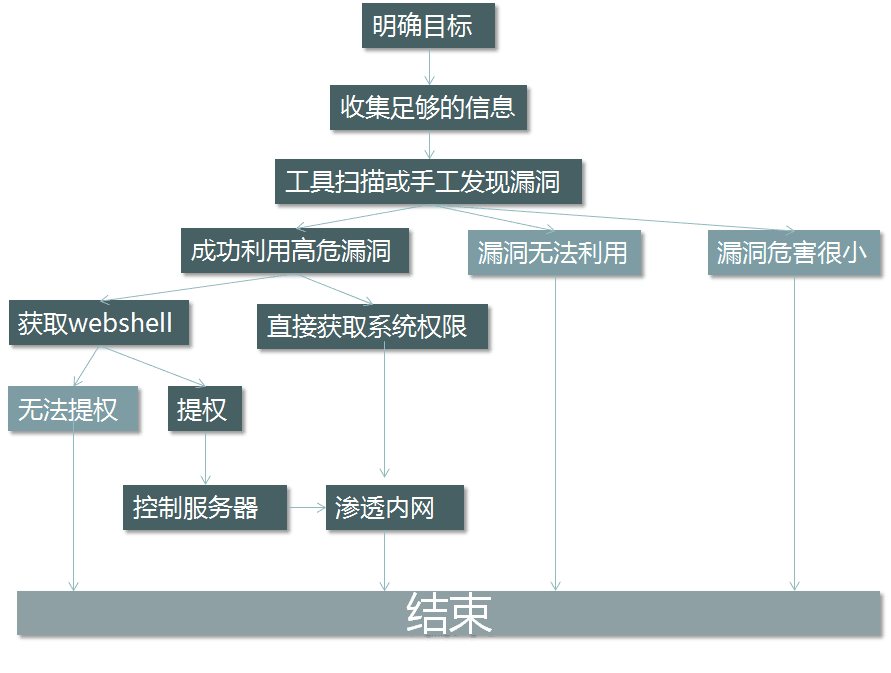
一般的渗透测试流程?
渗透测试就是利用我们所掌握的渗透知识,对网站进行一步一步的渗透,发现其中存在的漏洞和隐藏的风险,然后撰写一篇测试报告,提供给我们的客户。客户根据我们撰写的测试报告,对网站进行漏洞修补,以防止黑客的入侵!
- 渗透测试流程举例?
我们现在就模拟黑客对一个网站进行渗透测试,这属于黑盒测试,我们只知道该网站的URL,其他什么的信息都不知道。
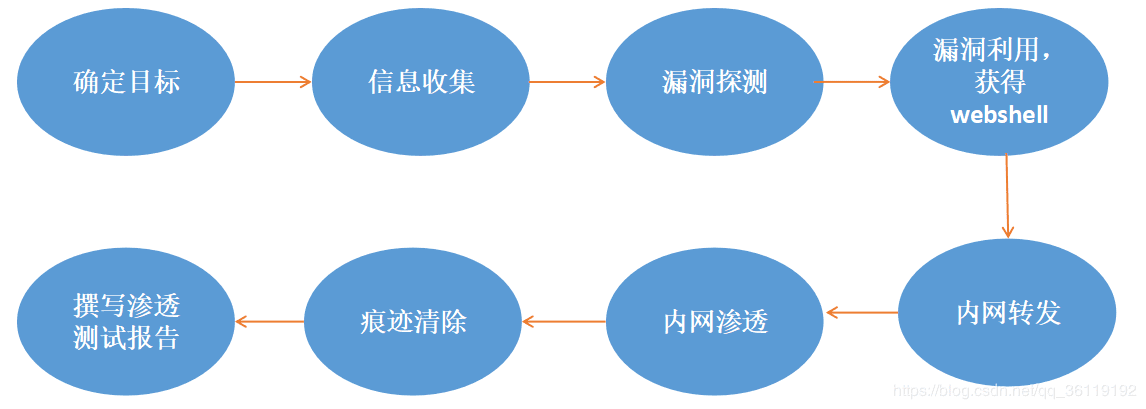
- 确定目标
- 确定范围:测试目标的范围、ip、域名、内外网、测试账户。
- 确定规则:能渗透到什么程度,所需要的时间、能否修改上传、能否提权、等等。
- 确定需求:web应用的漏洞、业务逻辑漏洞、人员权限管理漏洞、等等。
- 信息收集
- 方式:主动扫描,开放搜索等。
- 开放搜索:利用搜索引擎获得:后台、未授权页面、敏感url、等等。
- 基础信息:IP、网段、域名、端口。
- 应用信息:各端口的应用。例如web应用、邮件应用、等等。
- 系统信息:操作系统版本
- 版本信息:所有这些探测到的东西的版本。
- 服务信息:中间件的各类信息,插件信息。
- 人员信息:域名注册人员信息,web应用中发帖人的id,管理员姓名等。
- 防护信息:试着看能否探测到防护设备。
- 漏洞探测
- 漏洞验证
- 内网转发
- 内网横向渗透
- 权限维持
- 痕迹清除
- 撰写渗透测试保告
9.4 单元测试
谈谈你对单元测试的理解?
- 什么是单元测试?
单元测试(unit testing),是指对软件中的最小可测试单元进行检查和验证。
- 为什么要写单元测试?
使用单元测试可以有效地降低程序出错的机率,提供准确的文档,并帮助我们改进设计方案等等。
- 什么时候写单元测试?
比较推荐单元测试与具体实现代码同步进行这个方案的。只有对需求有一定的理解后才能知道什么是代码的正确性,才能写出有效的单元测试来验证正确性,而能写出一些功能代码则说明对需求有一定理解了。
- 单元测试要写多细?
单元测试不是越多越好,而是越有效越好!进一步解读就是哪些代码需要有单元测试覆盖:
- 逻辑复杂的
- 容易出错的
- 不易理解的,即使是自己过段时间也会遗忘的,看不懂自己的代码,单元测试代码有助于理解代码的功能和需求
- 公共代码。比如自定义的所有http请求都会经过的拦截器;工具类等。
- 核心业务代码。一个产品里最核心最有业务价值的代码应该要有较高的单元测试覆盖率。
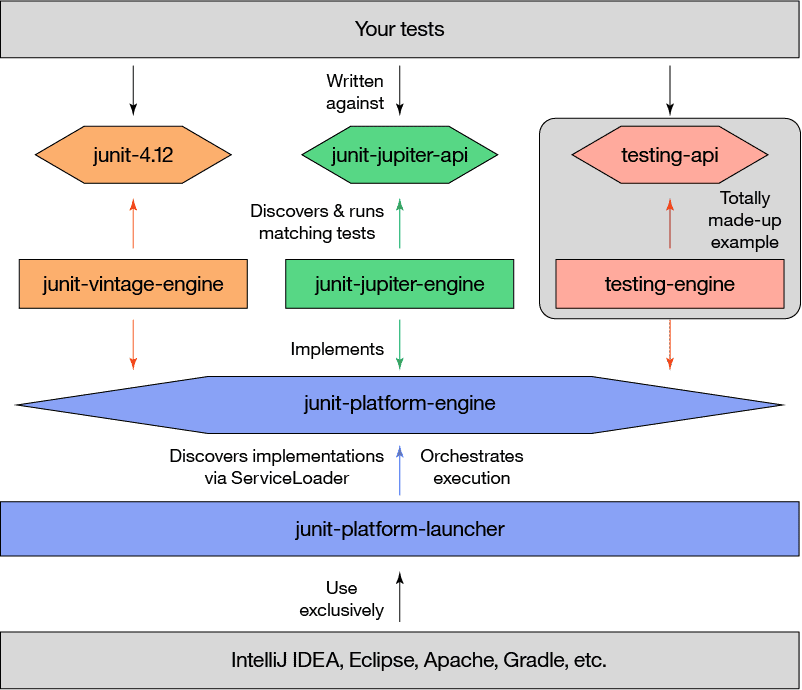
JUnit 5整体架构?
与以前版本的JUnit不同,JUnit 5由三个不同子项目中的几个不同模块组成。JUnit 5 = JUnit Platform + JUnit Jupiter + JUnit Vintage
- JUnit Platform是基于JVM的运行测试的基础框架在,它定义了开发运行在这个测试框架上的TestEngine API。此外该平台提供了一个控制台启动器,可以从命令行启动平台,可以为Gradle和 Maven构建插件,同时提供基于JUnit 4的Runner。
- JUnit Jupiter是在JUnit 5中编写测试和扩展的新编程模型和扩展模型的组合.Jupiter子项目提供了一个TestEngine在平台上运行基于Jupiter的测试。
- JUnit Vintage提供了一个TestEngine在平台上运行基于JUnit 3和JUnit 4的测试。
架构图如下:
JUnit 5与Junit4的差别在哪里?
对比下Junit5和Junit4注解:
| Junit4 | Junit5 | 注释 |
|---|---|---|
| @Test | @Test | 表示该方法是一个测试方法 |
| @BeforeClass | @BeforeAll | 表示使用了该注解的方法应该在当前类中所有测试方法之前执行(只执行一次),并且它必须是 static方法(除非@TestInstance指定生命周期为Lifecycle.PER_CLASS) |
| @AfterClass | @AfterAll | 表示使用了该注解的方法应该在当前类中所有测试方法之后执行(只执行一次),并且它必须是 static方法(除非@TestInstance指定生命周期为Lifecycle.PER_CLASS) |
| @Before | @BeforeEach | 表示使用了该注解的方法应该在当前类中每一个测试方法之前执行 |
| @After | @AfterEach | 表示使用了该注解的方法应该在当前类中每一个测试方法之后执行 |
| @Ignore | @Disabled | 用于禁用(或者说忽略)一个测试类或测试方法 |
| @Category | @Tag | 用于声明过滤测试的tag标签,该注解可以用在方法或类上 |
你在开发中使用什么框架来做单元测试?
- JUnit4/5
- Mockito, mock测试
- Powermock, 静态util的测试
9.5 代码质量
你们项目中是如何保证代码质量的?
- checkstyle, 静态样式检查
- sonarlint Sonar是一个用于代码质量管理的开源平台,用于管理源代码的质量 通过插件形式,可以支持包括java,C#,C/C++,PL/SQL,Cobol,JavaScrip,Groovy等等二十几种编程语言的代码质量管理与检测
- spotbugs, SpotBugs是Findbugs的继任者(Findbugs已经于2016年后不再维护),用于对代码进行静态分析,查找相关的漏洞; 它是一款自由软件,按照GNU Lesser General Public License 的条款发布
你们项目中是如何做code review的?
Gerrit + 定期线下review
9.6 代码重构
如何去除多余的if else?
- 出现if/else和switch/case的场景
通常业务代码会包含这样的逻辑:每种条件下会有不同的处理逻辑。比如两个数a和b之间可以通过不同的操作符(+,-,*,/)进行计算,初学者通常会这么写:
public int calculate(int a, int b, String operator) {
int result = Integer.MIN_VALUE;
if ("add".equals(operator)) {
result = a + b;
} else if ("multiply".equals(operator)) {
result = a * b;
} else if ("divide".equals(operator)) {
result = a / b;
} else if ("subtract".equals(operator)) {
result = a - b;
}
return result;
}
这种最基础的代码如何重构呢?
- 工厂类
public class OperatorFactory {
static Map<String, Operation> operationMap = new HashMap<>();
static {
operationMap.put("add", new Addition());
operationMap.put("divide", new Division());
// more operators
}
public static Optional<Operation> getOperation(String operator) {
return Optional.ofNullable(operationMap.get(operator));
}
}
- 枚举
public enum Operator {
ADD {
@Override
public int apply(int a, int b) {
return a + b;
}
},
// other operators
public abstract int apply(int a, int b);
}
- Command模式
public class AddCommand implements Command {
// Instance variables
public AddCommand(int a, int b) {
this.a = a;
this.b = b;
}
@Override
public Integer execute() {
return a + b;
}
}
- 规则引擎
- 定义规则
public interface Rule {
boolean evaluate(Expression expression);
Result getResult();
}
- Add 规则
public class AddRule implements Rule {
@Override
public boolean evaluate(Expression expression) {
boolean evalResult = false;
if (expression.getOperator() == Operator.ADD) {
this.result = expression.getX() + expression.getY();
evalResult = true;
}
return evalResult;
}
}
- 表达式
public class Expression {
private Integer x;
private Integer y;
private Operator operator;
}
- 规则引擎
public class RuleEngine {
private static List<Rule> rules = new ArrayList<>();
static {
rules.add(new AddRule());
}
public Result process(Expression expression) {
Rule rule = rules
.stream()
.filter(r -> r.evaluate(expression))
.findFirst()
.orElseThrow(() -> new IllegalArgumentException("Expression does not matches any Rule"));
return rule.getResult();
}
}
- 策略模式
- 操作
public interface Opt {
int apply(int a, int b);
}
@Component(value = "addOpt")
public class AddOpt implements Opt {
@Autowired
xxxAddResource resource; // 这里通过Spring框架注入了资源
@Override
public int apply(int a, int b) {
return resource.process(a, b);
}
}
@Component(value = "devideOpt")
public class devideOpt implements Opt {
@Autowired
xxxDivResource resource; // 这里通过Spring框架注入了资源
@Override
public int apply(int a, int b) {
return resource.process(a, b);
}
}
- 策略
@Component
public class OptStrategyContext{
private Map<String, Opt> strategyMap = new ConcurrentHashMap<>();
@Autowired
public OptStrategyContext(Map<String, TalkService> strategyMap) {
this.strategyMap.clear();
this.strategyMap.putAll(strategyMap);
}
public int apply(Sting opt, int a, int b) {
return strategyMap.get(opt).apply(a, b);
}
}
如何去除不必要的!=判空?
- 空对象模式
public class MyParser implements Parser {
private static Action NO_ACTION = new Action() {
public void doSomething() { /* do nothing */ }
};
public Action findAction(String userInput) {
// ...
if ( /* we can't find any actions */ ) {
return NO_ACTION;
}
}
}
然后便可以始终可以这么调用
ParserFactory.getParser().findAction(someInput).doSomething();
- Java8中使用Optional
Outer outer = new Outer();
if (outer != null && outer.nested != null && outer.nested.inner != null) {
System.out.println(outer.nested.inner.foo);
}
我们可以通过利用 Java 8 的 Optional 类型来摆脱所有这些 null 检查。map 方法接收一个 Function 类型的 lambda 表达式,并自动将每个 function 的结果包装成一个 Optional 对象。这使我们能够在一行中进行多个 map 操作。Null 检查是在底层自动处理的。
Optional.of(new Outer())
.map(Outer::getNested)
.map(Nested::getInner)
.map(Inner::getFoo)
.ifPresent(System.out::println);
还有一种实现相同作用的方式就是通过利用一个 supplier 函数来解决嵌套路径的问题:
Outer obj = new Outer();
resolve(() -> obj.getNested().getInner().getFoo())
.ifPresent(System.out::println);
10 开发框架和中间件
开发框架相关
10.1 Spring
什么是Spring框架?
Spring是一种轻量级框架,旨在提高开发人员的开发效率以及系统的可维护性。
我们一般说的Spring框架就是Spring Framework,它是很多模块的集合,使用这些模块可以很方便地协助我们进行开发。这些模块是核心容器、数据访问/集成、Web、AOP(面向切面编程)、工具、消息和测试模块。比如Core Container中的Core组件是Spring所有组件的核心,Beans组件和Context组件是实现IOC和DI的基础,AOP组件用来实现面向切面编程。
Spring官网列出的Spring的6个特征:
- 核心技术:依赖注入(DI),AOP,事件(Events),资源,i18n,验证,数据绑定,类型转换,SpEL。
- 测试:模拟对象,TestContext框架,Spring MVC测试,WebTestClient。
- 数据访问:事务,DAO支持,JDBC,ORM,编组XML。
- Web支持:Spring MVC和Spring WebFlux Web框架。
- 集成:远程处理,JMS,JCA,JMX,电子邮件,任务,调度,缓存。
- 语言:Kotlin,Groovy,动态语言。
列举一些重要的Spring模块?
下图对应的是Spring 4.x的版本,目前最新的5.x版本中Web模块的Portlet组件已经被废弃掉,同时增加了用于异步响应式处理的WebFlux组件。
- Spring Core:基础,可以说Spring其他所有的功能都依赖于该类库。主要提供IOC和DI功能。
- Spring Aspects:该模块为与AspectJ的集成提供支持。
- Spring AOP:提供面向切面的编程实现。
- Spring JDBC:Java数据库连接。
- Spring JMS:Java消息服务。
- Spring ORM:用于支持Hibernate等ORM工具。
- Spring Web:为创建Web应用程序提供支持。
- Spring Test:提供了对JUnit和TestNG测试的支持。
什么是IOC? 如何实现的?
IOC(Inversion Of Controll,控制反转)是一种设计思想,就是将原本在程序中手动创建对象的控制权,交给IOC容器来管理,并由IOC容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。IOC容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。
Spring 中的 IoC 的实现原理就是工厂模式加反射机制。
示例:
interface Fruit {
public abstract void eat();
}
class Apple implements Fruit {
public void eat(){
System.out.println("Apple");
}
}
class Orange implements Fruit {
public void eat(){
System.out.println("Orange");
}
}
class Factory {
public static Fruit getInstance(String ClassName) {
Fruit f=null;
try {
f=(Fruit)Class.forName(ClassName).newInstance();
} catch (Exception e) {
e.printStackTrace();
}
return f;
}
}
class Client {
public static void main(String[] a) {
Fruit f=Factory.getInstance("io.github.dunwu.spring.Apple");
if(f!=null){
f.eat();
}
}
}
什么是AOP? 有哪些AOP的概念?
AOP(Aspect-Oriented Programming,面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可扩展性和可维护性。
Spring AOP是基于动态代理的,如果要代理的对象实现了某个接口,那么Spring AOP就会使用JDK动态代理去创建代理对象;而对于没有实现接口的对象,就无法使用JDK动态代理,转而使用CGlib动态代理生成一个被代理对象的子类来作为代理。
当然也可以使用AspectJ,Spring AOP中已经集成了AspectJ,AspectJ应该算得上是Java生态系统中最完整的AOP框架了。使用AOP之后我们可以把一些通用功能抽象出来,在需要用到的地方直接使用即可,这样可以大大简化代码量。我们需要增加新功能也方便,提高了系统的扩展性。日志功能、事务管理和权限管理等场景都用到了AOP。
AOP包含的几个概念
- Jointpoint(连接点):具体的切面点点抽象概念,可以是在字段、方法上,Spring中具体表现形式是PointCut(切入点),仅作用在方法上。
- Advice(通知): 在连接点进行的具体操作,如何进行增强处理的,分为前置、后置、异常、最终、环绕五种情况。
- 目标对象:被AOP框架进行增强处理的对象,也被称为被增强的对象。
- AOP代理:AOP框架创建的对象,简单的说,代理就是对目标对象的加强。Spring中的AOP代理可以是JDK动态代理,也可以是CGLIB代理。
- Weaving(织入):将增强处理添加到目标对象中,创建一个被增强的对象的过程
总结为一句话就是:在目标对象(target object)的某些方法(jointpoint)添加不同种类的操作(通知、增强操处理),最后通过某些方法(weaving、织入操作)实现一个新的代理目标对象。
AOP 有哪些应用场景?
举几个例子:
- 记录日志(调用方法后记录日志)
- 监控性能(统计方法运行时间)
- 权限控制(调用方法前校验是否有权限)
- 事务管理(调用方法前开启事务,调用方法后提交关闭事务 )
- 缓存优化(第一次调用查询数据库,将查询结果放入内存对象, 第二次调用,直接从内存对象返回,不需要查询数据库 )
有哪些AOP Advice通知的类型?
特定 JoinPoint 处的 Aspect 所采取的动作称为 Advice。Spring AOP 使用一个 Advice 作为拦截器,在 JoinPoint “周围”维护一系列的拦截器。
- 前置通知(Before advice) : 这些类型的 Advice 在 joinpoint 方法之前执行,并使用 @Before 注解标记进行配置。
- 后置通知(After advice) :这些类型的 Advice 在连接点方法之后执行,无论方法退出是正常还是异常返回,并使用 @After 注解标记进行配置。
- 返回后通知(After return advice) :这些类型的 Advice 在连接点方法正常执行后执行,并使用@AfterReturning 注解标记进行配置。
- 环绕通知(Around advice) :这些类型的 Advice 在连接点之前和之后执行,并使用 @Around 注解标记进行配置。
- 抛出异常后通知(After throwing advice) :仅在 joinpoint 方法通过抛出异常退出并使用 @AfterThrowing 注解标记配置时执行。
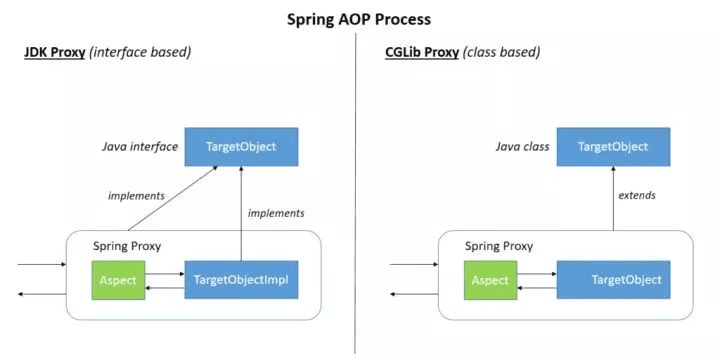
AOP 有哪些实现方式?
实现 AOP 的技术,主要分为两大类:
- 静态代理 - 指使用 AOP 框架提供的命令进行编译,从而在编译阶段就可生成 AOP 代理类,因此也称为编译时增强;
- 编译时编织(特殊编译器实现)
- 类加载时编织(特殊的类加载器实现)。
- 动态代理 - 在运行时在内存中“临时”生成 AOP 动态代理类,因此也被称为运行时增强。
- JDK 动态代理
- JDK Proxy 是 Java 语言自带的功能,无需通过加载第三方类实现;
- Java 对 JDK Proxy 提供了稳定的支持,并且会持续的升级和更新,Java 8 版本中的 JDK Proxy 性能相比于之前版本提升了很多;
- JDK Proxy 是通过拦截器加反射的方式实现的;
- JDK Proxy 只能代理实现接口的类;
- JDK Proxy 实现和调用起来比较简单;
- CGLIB
- CGLib 是第三方提供的工具,基于 ASM 实现的,性能比较高;
- CGLib 无需通过接口来实现,它是针对类实现代理,主要是对指定的类生成一个子类,它是通过实现子类的方式来完成调用的。
- JDK 动态代理
谈谈你对CGLib的理解?
JDK 动态代理机制只能代理实现接口的类,一般没有实现接口的类不能进行代理。使用 CGLib 实现动态代理,完全不受代理类必须实现接口的限制。
CGLib 的原理是对指定目标类生成一个子类,并覆盖其中方法实现增强,但因为采用的是继承,所以不能对 final 修饰的类进行代理。
举例:
public class CGLibDemo {
// 需要动态代理的实际对象
static class Sister {
public void sing() {
System.out.println("I am Jinsha, a little sister.");
}
}
static class CGLibProxy implements MethodInterceptor {
private Object target;
public Object getInstance(Object target){
this.target = target;
Enhancer enhancer = new Enhancer();
// 设置父类为实例类
enhancer.setSuperclass(this.target.getClass());
// 回调方法
enhancer.setCallback(this);
// 创建代理对象
return enhancer.create();
}
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
System.out.println("introduce yourself...");
Object result = methodProxy.invokeSuper(o,objects);
System.out.println("score...");
return result;
}
}
public static void main(String[] args) {
CGLibProxy cgLibProxy = new CGLibProxy();
//获取动态代理类实例
Sister proxySister = (Sister) cgLibProxy.getInstance(new Sister());
System.out.println("CGLib Dynamic object name: " + proxySister.getClass().getName());
proxySister.sing();
}
}
CGLib 的调用流程就是通过调用拦截器的 intercept 方法来实现对被代理类的调用。而拦截逻辑可以写在 intercept 方法的 invokeSuper(o, objects);的前后实现拦截。
Spring AOP和AspectJ AOP有什么区别?
Spring AOP是属于运行时增强,而AspectJ是编译时增强。Spring AOP基于代理(Proxying),而AspectJ基于字节码操作(Bytecode Manipulation)。
Spring AOP已经集成了AspectJ,AspectJ应该算得上是Java生态系统中最完整的AOP框架了。AspectJ相比于Spring AOP功能更加强大,但是Spring AOP相对来说更简单。
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择AspectJ,它比SpringAOP快很多。
Spring中的bean的作用域有哪些?
singleton:唯一bean实例,Spring中的bean默认都是单例的。
prototype:每次请求都会创建一个新的bean实例。
request:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效。
session:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP session内有效。
global-session:全局session作用域,仅仅在基于Portlet的Web应用中才有意义,Spring5中已经没有了。Portlet是能够生成语义代码(例如HTML)片段的小型Java Web插件。它们基于Portlet容器,可以像Servlet一样处理HTTP请求。但是与Servlet不同,每个Portlet都有不同的会话。
Spring中的单例bean的线程安全问题了解吗?
大部分时候我们并没有在系统中使用多线程,所以很少有人会关注这个问题。单例bean存在线程问题,主要是因为当多个线程操作同一个对象的时候,对这个对象的非静态成员变量的写操作会存在线程安全问题。
有两种常见的解决方案:
1.在bean对象中尽量避免定义可变的成员变量(不太现实)。
2.在类中定义一个ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中(推荐的一种方式)。
Spring中的bean生命周期?
Bean的完整生命周期经历了各种方法调用,这些方法可以划分为以下几类:
- Bean自身的方法: 这个包括了Bean本身调用的方法和通过配置文件中
<bean>的init-method和destroy-method指定的方法 - Bean级生命周期接口方法: 这个包括了BeanNameAware、BeanFactoryAware、ApplicationContextAware;当然也包括InitializingBean和DiposableBean这些接口的方法(可以被@PostConstruct和@PreDestroy注解替代)
- 容器级生命周期接口方法: 这个包括了InstantiationAwareBeanPostProcessor 和 BeanPostProcessor 这两个接口实现,一般称它们的实现类为“后处理器”。
- 工厂后处理器接口方法: 这个包括了AspectJWeavingEnabler, ConfigurationClassPostProcessor, CustomAutowireConfigurer等等非常有用的工厂后处理器接口的方法。工厂后处理器也是容器级的。在应用上下文装配配置文件之后立即调用。

具体而言,流程如下
- 如果 BeanFactoryPostProcessor 和 Bean 关联, 则调用postProcessBeanFactory方法.(即首先尝试从Bean工厂中获取Bean)
- 如果 InstantiationAwareBeanPostProcessor 和 Bean 关联,则调用postProcessBeforeInstantiation方法
- 根据配置情况调用 Bean 构造方法实例化 Bean。
- 利用依赖注入完成 Bean 中所有属性值的配置注入。
- 如果 InstantiationAwareBeanPostProcessor 和 Bean 关联,则调用postProcessAfterInstantiation方法和postProcessProperties
- 调用xxxAware接口 (上图只是给了几个例子)
- 第一类Aware接口
- 如果 Bean 实现了 BeanNameAware 接口,则 Spring 调用 Bean 的 setBeanName() 方法传入当前 Bean 的 id 值。
- 如果 Bean 实现了 BeanClassLoaderAware 接口,则 Spring 调用 setBeanClassLoader() 方法传入classLoader的引用。
- 如果 Bean 实现了 BeanFactoryAware 接口,则 Spring 调用 setBeanFactory() 方法传入当前工厂实例的引用。
- 第二类Aware接口
- 如果 Bean 实现了 EnvironmentAware 接口,则 Spring 调用 setEnvironment() 方法传入当前 Environment 实例的引用。
- 如果 Bean 实现了 EmbeddedValueResolverAware 接口,则 Spring 调用 setEmbeddedValueResolver() 方法传入当前 StringValueResolver 实例的引用。
- 如果 Bean 实现了 ApplicationContextAware 接口,则 Spring 调用 setApplicationContext() 方法传入当前 ApplicationContext 实例的引用。
- ...
- 第一类Aware接口
- 如果 BeanPostProcessor 和 Bean 关联,则 Spring 将调用该接口的预初始化方法 postProcessBeforeInitialzation() 对 Bean 进行加工操作,此处非常重要,Spring 的 AOP 就是利用它实现的。
- 如果 Bean 实现了 InitializingBean 接口,则 Spring 将调用 afterPropertiesSet() 方法。(或者有执行@PostConstruct注解的方法)
- 如果在配置文件中通过 init-method 属性指定了初始化方法,则调用该初始化方法。
- 如果 BeanPostProcessor 和 Bean 关联,则 Spring 将调用该接口的初始化方法 postProcessAfterInitialization()。此时,Bean 已经可以被应用系统使用了。
- 如果在
<bean>中指定了该 Bean 的作用范围为 scope="singleton",则将该 Bean 放入 Spring IoC 的缓存池中,将触发 Spring 对该 Bean 的生命周期管理;如果在<bean>中指定了该 Bean 的作用范围为 scope="prototype",则将该 Bean 交给调用者,调用者管理该 Bean 的生命周期,Spring 不再管理该 Bean。 - 如果 Bean 实现了 DisposableBean 接口,则 Spring 会调用 destory() 方法将 Spring 中的 Bean 销毁;(或者有执行@PreDestroy注解的方法)
- 如果在配置文件中通过 destory-method 属性指定了 Bean 的销毁方法,则 Spring 将调用该方法对 Bean 进行销毁。
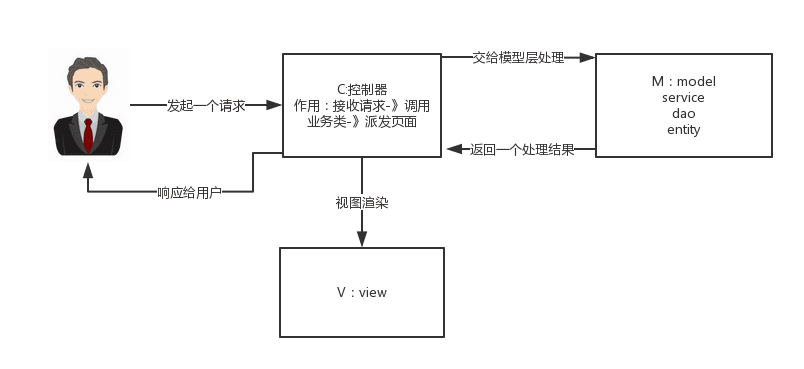
说说自己对于Spring MVC的了解?
MVC是一种设计模式,Spring MVC是一款很优秀的MVC框架。Spring MVC可以帮助我们进行更简洁的Web层的开发,并且它天生与Spring框架集成。Spring MVC下我们一般把后端项目分为Service层(处理业务)、Dao层(数据库操作)、Entity层(实体类)、Controller层(控制层,返回数据给前台页面)。
Spring MVC的简单原理图如下:
Spring MVC的工作原理了解嘛?
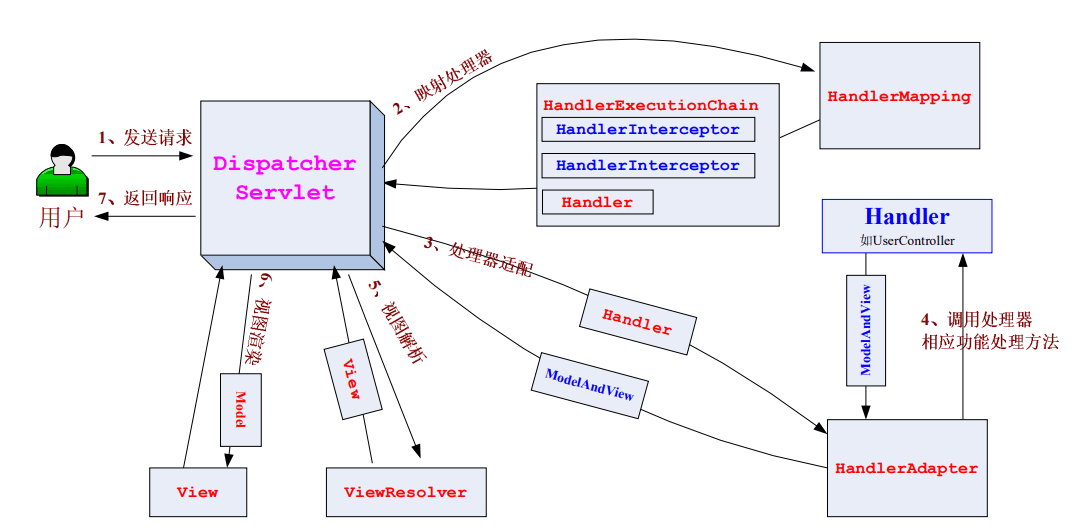
流程说明:
1.客户端(浏览器)发送请求,直接请求到DispatcherServlet。
2.DispatcherServlet根据请求信息调用HandlerMapping,解析请求对应的Handler。
3.解析到对应的Handler(也就是我们平常说的Controller控制器)。
4.HandlerAdapter会根据Handler来调用真正的处理器来处理请求和执行相对应的业务逻辑。
5.处理器处理完业务后,会返回一个ModelAndView对象,Model是返回的数据对象,View是逻辑上的View。
6.ViewResolver会根据逻辑View去查找实际的View。
7.DispatcherServlet把返回的Model传给View(视图渲染)。
8.把View返回给请求者(浏览器)。
Spring框架中用到了哪些设计模式?
举几个例子
1.工厂设计模式:Spring使用工厂模式通过BeanFactory和ApplicationContext创建bean对象。
2.代理设计模式:Spring AOP功能的实现。
3.单例设计模式:Spring中的bean默认都是单例的。
4.模板方法模式:Spring中的jdbcTemplate、hibernateTemplate等以Template结尾的对数据库操作的类,它们就使用到了模板模式。
5.包装器设计模式:我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
6.观察者模式:Spring事件驱动模型就是观察者模式很经典的一个应用。
7.适配器模式:Spring AOP的增强或通知(Advice)使用到了适配器模式、Spring MVC中也是用到了适配器模式适配Controller。
@Component和@Bean的区别是什么?
1.作用对象不同。@Component注解作用于类,而@Bean注解作用于方法。
2.@Component注解通常是通过类路径扫描来自动侦测以及自动装配到Spring容器中(我们可以使用@ComponentScan注解定义要扫描的路径)。@Bean注解通常是在标有该注解的方法中定义产生这个bean,告诉Spring这是某个类的实例,当我需要用它的时候还给我。
3.@Bean注解比@Component注解的自定义性更强,而且很多地方只能通过@Bean注解来注册bean。比如当引用第三方库的类需要装配到Spring容器的时候,就只能通过@Bean注解来实现。
@Bean注解的使用示例:
@Configuration
public class AppConfig {
@Bean
public TransferService transferService() {
return new TransferServiceImpl();
}
}
上面的代码相当于下面的XML配置:
<beans>
<bean id="transferService" class="com.yanggb.TransferServiceImpl"/>
</beans>
下面这个例子是无法通过@Component注解实现的:
@Bean
public OneService getService(status) {
case (status) {
when 1:
return new serviceImpl1();
when 2:
return new serviceImpl2();
when 3:
return new serviceImpl3();
}
}
将一个类声明为Spring的bean的注解有哪些?
我们一般使用@Autowired注解去自动装配bean。而想要把一个类标识为可以用@Autowired注解自动装配的bean,可以采用以下的注解实现:
1.@Component注解。通用的注解,可标注任意类为Spring组件。如果一个Bean不知道属于哪一个层,可以使用@Component注解标注。
2.@Repository注解。对应持久层,即Dao层,主要用于数据库相关操作。
3.@Service注解。对应服务层,即Service层,主要涉及一些复杂的逻辑,需要用到Dao层(注入)。
4.@Controller注解。对应Spring MVC的控制层,即Controller层,主要用于接受用户请求并调用Service层的方法返回数据给前端页面。
Spring事务管理的方式有几种?
1.编程式事务:在代码中硬编码(不推荐使用)。
2.声明式事务:在配置文件中配置(推荐使用),分为基于XML的声明式事务和基于注解的声明式事务。
Spring事务中的隔离级别有哪几种?
在TransactionDefinition接口中定义了五个表示隔离级别的常量:
ISOLATION_DEFAULT:使用后端数据库默认的隔离级别,Mysql默认采用的REPEATABLE_READ隔离级别;Oracle默认采用的READ_COMMITTED隔离级别。
ISOLATION_READ_UNCOMMITTED:最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
ISOLATION_READ_COMMITTED:允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
ISOLATION_REPEATABLE_READ:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
ISOLATION_SERIALIZABLE:最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
Spring事务中有哪几种事务传播行为?
在TransactionDefinition接口中定义了7个表示事务传播行为的常量。
支持当前事务的情况:
PROPAGATION_REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)。
不支持当前事务的情况:
PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
其他情况:
PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于PROPAGATION_REQUIRED。
Bean Factory和ApplicationContext有什么区别?
ApplicationContex提供了一种解析文本消息的方法,一种加载文件资源(如图像)的通用方法,它们可以将事件发布到注册为侦听器的bean。此外,可以在应用程序上下文中以声明方式处理容器中的容器或容器上的操作,这些操作必须以编程方式与Bean Factory一起处理。ApplicationContext实现MessageSource,一个用于获取本地化消息的接口,实际的实现是可插入的。
如何定义bean的范围?
在Spring中定义一个时,我们也可以为bean声明一个范围。它可以通过bean定义中的scope属性定义。例如,当Spring每次需要生成一个新的bean实例时,bean'sscope属性就是原型。另一方面,当每次需要Spring都必须返回相同的bean实例时,bean scope属性必须设置为singleton。
可以通过多少种方式完成依赖注入?
通常,依赖注入可以通过三种方式完成,即:
- 构造函数注入
- setter 注入
- 接口注入
10.2 Spring Boot
什么是SpringBoot?
Spring Boot 是 Spring 开源组织下的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,简省了繁重的配置,提供了各种启动器,开发者能快速上手。
- 用来简化Spring应用的初始搭建以及开发过程,使用特定的方式来进行配置
- 创建独立的Spring引用程序main方法运行
- 嵌入的tomcat无需部署war文件
- 简化maven配置
- 自动配置Spring添加对应的功能starter自动化配置
- SpringBoot来简化Spring应用开发,约定大于配置,去繁化简
为什么使用SpringBoot?
- 独立运行
Spring Boot 而且内嵌了各种 servlet 容器,Tomcat、Jetty 等,现在不再需要打成war 包部署到容器中,Spring Boot 只要打成一个可执行的 jar 包就能独立运行,所有的依赖包都在一个 jar 包内。
- 简化配置
spring-boot-starter-web 启动器自动依赖其他组件,简少了 maven 的配置。
- 自动配置
Spring Boot 能根据当前类路径下的类、jar 包来自动配置 bean,如添加一个 spring
boot-starter-web 启动器就能拥有 web 的功能,无需其他配置。
- 无代码生成和XML配置
Spring Boot 配置过程中无代码生成,也无需 XML 配置文件就能完成所有配置工作,这一切都是借助于条件注解完成的,这也是 Spring4.x 的核心功能之一。
- 应用监控
Spring Boot 提供一系列端点可以监控服务及应用,做健康检测。
Spring、Spring MVC和SpringBoot有什么区别?
- Spring
Spring最重要的特征是依赖注入。所有Spring Modules不是依赖注入就是IOC控制反转。
当我们恰当的使用DI或者是IOC的时候,可以开发松耦合应用。
- Spring MVC
Spring MVC提供了一种分离式的方法来开发Web应用。通过运用像DispatcherServelet,ModelAndView 和 ViewResolver 等一些简单的概念,开发 Web 应用将会变的非常简单。
- SpringBoot
Spring和Spring MVC的问题在于需要配置大量的参数。
SpringBoot通过一个自动配置和启动的项来解决这个问题。
SpringBoot自动配置的原理?
在Spring程序main方法中,添加@SpringBootApplication或者@EnableAutoConfiguration会自动去maven中读取每个starter中的spring.factories文件,该文件里配置了所有需要被创建的Spring容器中的bean
Spring Boot的核心注解是哪些?他主由哪几个注解组成的?
启动类上面的注解是@SpringBootApplication,他也是SpringBoot的核心注解,主要组合包含了以下3个注解:
- @SpringBootConfiguration:组合了@Configuration注解,实现配置文件的功能;
- @EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置的功能:
- @SpringBootApplication(exclude={DataSourceAutoConfiguration.class});
- @ComponentScan:Spring组件扫描。
SpringBoot的核心配置文件有哪几个?他们的区别是什么?
SpringBoot的核心配置文件是application和bootstrap配置文件。
application配置文件这个容易理解,主要用于Spring Boot项目的自动化配置。
bootstrap配置文件有以下几个应用场景:
- 使用Spring Cloud Config配置中心时,这时需要在bootstrap配置文件中添加连接到配置中心的配置属性来加载外部配置中心的配置信息;
- 一些固定的不能被覆盖的属性;
- 一些加密/解密的场景;
什么是Spring Boot Starter?有哪些常用的?
和自动配置一样,Spring Boot Starter的目的也是简化配置,而Spring Boot Starter解决的是依赖管理配置复杂的问题,有了它,当我需要构建一个Web应用程序时,不必再遍历所有的依赖包,一个一个地添加到项目的依赖管理中,而是只需要一个配置spring-boot-starter-web, 同理,如果想引入持久化功能,可以配置spring-boot-starter-data-jpa:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
Spring Boot 也提供了其它的启动器项目包括,包括用于开发特定类型应用程序的典型依赖项。
spring-boot-starter-web-services - SOAP Web Services
spring-boot-starter-web - Web 和 RESTful 应用程序
spring-boot-starter-test - 单元测试和集成测试
spring-boot-starter-jdbc - 传统的 JDBC
spring-boot-starter-hateoas - 为服务添加 HATEOAS 功能
spring-boot-starter-security - 使用 SpringSecurity 进行身份验证和授权
spring-boot-starter-data-jpa - 带有 Hibernate 的 Spring Data JPA
spring-boot-starter-data-rest - 使用 Spring Data REST 公布简单的 REST 服务
spring-boot-starter-parent有什么作用?
我们知道,新建一个SpringBoot项目,默认都是有parent的,这个parent就是spring-boot-starter-parent,spring-boot-starter-parent主要有如下作用:
- 定义了Java编译版本
- 使用UTF-8格式编码
- 继承自spring-boor-dependencies,这里面定义了依赖的版本,也正是因为继承了这个依赖,所以我们在写依赖时才不需要写版本号
- 执行打包操作的配置
- 自动化的资源过滤
- 自动化的插件配置
如何自定义Spring Boot Starter?
- 实现功能
- 添加Properties
@Data
@ConfigurationProperties(prefix = "com.pdai")
public class DemoProperties {
private String version;
private String name;
}
- 添加AutoConfiguration
@Configuration
@EnableConfigurationProperties(DemoProperties.class)
public class DemoAutoConfiguration {
@Bean
public com.pdai.demo.module.DemoModule demoModule(DemoProperties properties){
com.pdai.demo.module.DemoModule demoModule = new com.pdai.demo.module.DemoModule();
demoModule.setName(properties.getName());
demoModule.setVersion(properties.getVersion());
return demoModule;
}
}
- 添加spring.factory
在META-INF下创建spring.factory文件
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.pdai.demospringbootstarter.DemoAutoConfiguration
- install
为什么需要spring-boot-maven-plugin?
spring-boot-maven-plugin提供了一些像jar一样打包或者运行应用程序的命令。
- spring-boot:run 运行SpringBoot应用程序;
- spring-boot:repackage 重新打包你的jar包或者是war包使其可执行
- spring-boot:start和spring-boot:stop管理Spring Boot应用程序的生命周期
- spring-boot:build-info生成执行器可以使用的构造信息
SpringBoot 打成jar和普通的jar有什么区别?
Spring Boot 项目最终打包成的 jar 是可执行 jar ,这种 jar 可以直接通过java -jar xxx.jar命令来运行,这种 jar 不可以作为普通的 jar 被其他项目依赖,即使依赖了也无法使用其中的类。
Spring Boot 的 jar 无法被其他项目依赖,主要还是他和普通 jar 的结构不同。普通的 jar 包,解压后直接就是包名,包里就是我们的代码,而 Spring Boot 打包成的可执行 jar 解压后,在 \BOOT-INF\classes目录下才是我们的代码,因此无法被直接引用。如果非要引用,可以在 pom.xml 文件中增加配置,将 Spring Boot 项目打包成两个 jar ,一个可执行,一个可引用。
如何使用Spring Boot实现异常处理?
Spring提供了一种使用ControllerAdvice处理异常的非常有用的方法。通过实现一个ControlerAdvice类,来处理控制类抛出的所有异常。
SpringBoot 实现热部署有哪几种方式?
主要有两种方式:
- Spring Loaded
- Spring-boot-devtools
Spring Boot中的监视器是什么?
Spring boot actuator是spring启动框架中的重要功能之一。Spring boot监视器可帮助您访问生产环境中正在运行的应用程序的当前状态。
有几个指标必须在生产环境中进行检查和监控。即使一些外部应用程序可能正在使用这些服务来向相关人员触发警报消息。监视器模块公开了一组可直接作为HTTP URL访问的REST端点来检查状态。
Spring Boot 可以兼容老 Spring 项目吗?
可以兼容,使用 @ImportResource 注解导入老 Spring 项目配置文件。
10.3 Spring Security
什么是Spring Security?核心功能?
Spring Security是基于Spring的安全框架.它提供全面的安全性解决方案,同时在Web请求级别和调用级别确认和授权.在Spring Framework基础上,Spring Security充分利用了依赖注入(DI)和面向切面编程(AOP)功能,为应用系统提供声明式的安全访问控制功能,建晒了为企业安全控制编写大量重复代码的工作,是一个轻量级的安全框架,并且很好集成Spring MVC
spring security 的核心功能主要包括:
- 认证(Authentication):指的是验证某个用户是否为系统中的合法主体,也就是说用户能否访问该系统。
- 授权(Authorization):指的是验证某个用户是否有权限执行某个操作
- 攻击防护:指的是防止伪造身份
Spring Security的原理?
简单谈谈其中的要点
- 基于Filter技术实现?
首先SpringSecurity是基于Filter技术实现的。Spring通过DelegatingFilterProxy建立Web容器和Spring ApplicationContext的联系,而SpringSecurity使用FilterChainProxy 注册SecurityFilterChain。

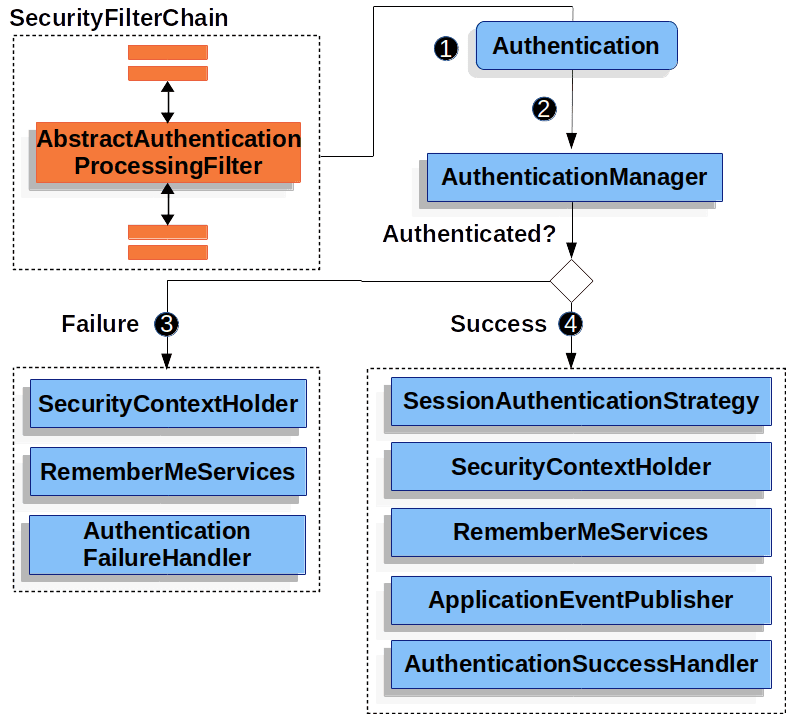
- 认证模块的实现?
SecurityContextHolder(用于存储授权信息)

手动授权的例子(SecurityContextHolder.getContext().setAuthentication(authentication)这种授权方式多线程不安全):
SecurityContext context = SecurityContextHolder.createEmptyContext();
Authentication authentication =
new TestingAuthenticationToken("username", "password", "ROLE_USER");
context.setAuthentication(authentication);
SecurityContextHolder.setContext(context);
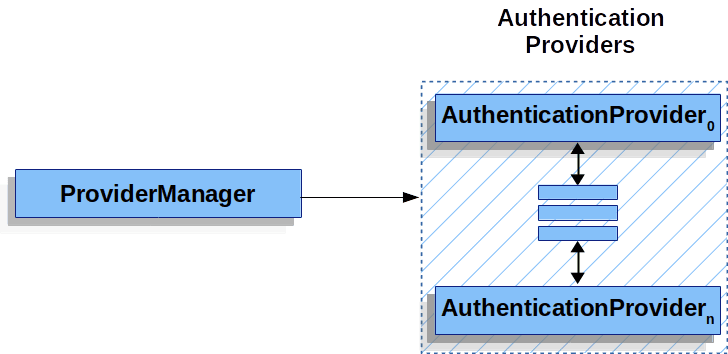
除了手动授权外,SpringSecurity通过AuthenticationManager和ProviderManager进行授权。其中AuthenticationProvider代表不同的认证机制(最常用的账号/密码)。
ProviderManager
AuthenticationManager
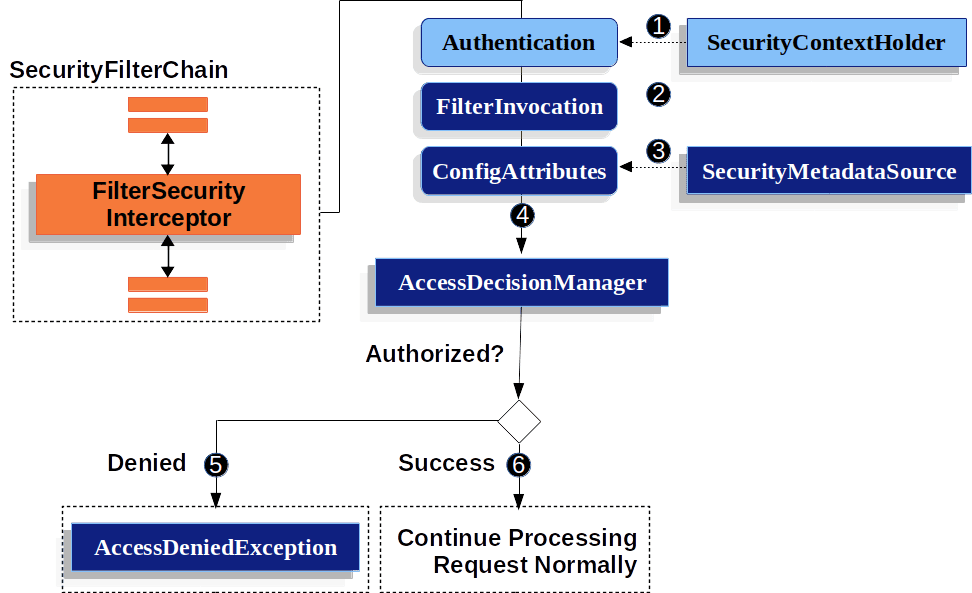
- 授权模块的实现?
认证完成之后,SpringSecurity通过AccessDecisionManager 完成授权操作。除了全局的授权配置之外,也可以通过@PreAuthorize, @PreFilter, @PostAuthorize , @PostFilter注解实现方法级别的权限控制。
Spring Security基于用户名和密码的认证模式流程?
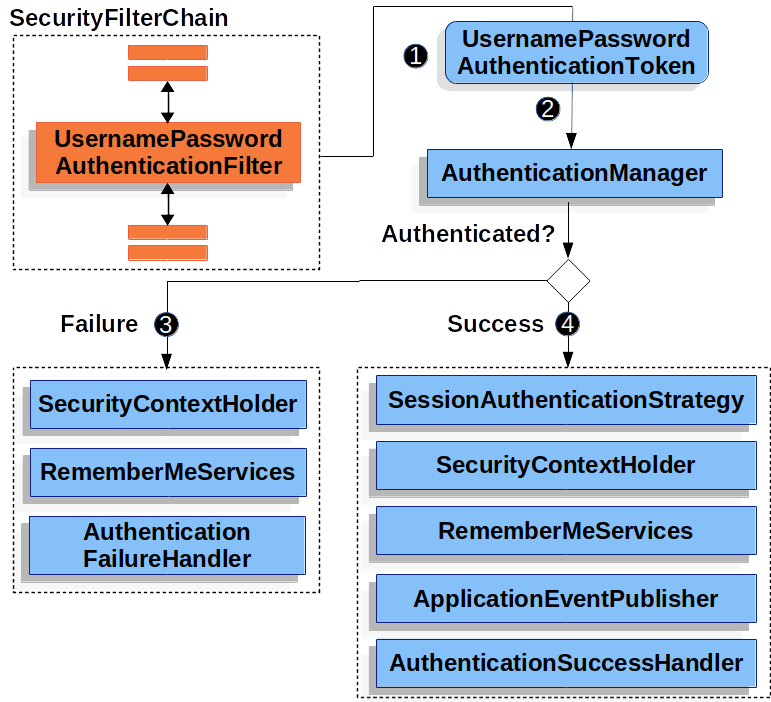
请求的用户名密码可以通过表单登录,基础认证,数字认证三种方式从HttpServletRequest中获得,用于认证的数据源策略有内存,数据库,ldap,自定义等。
拦截未授权的请求,重定向到登录页面
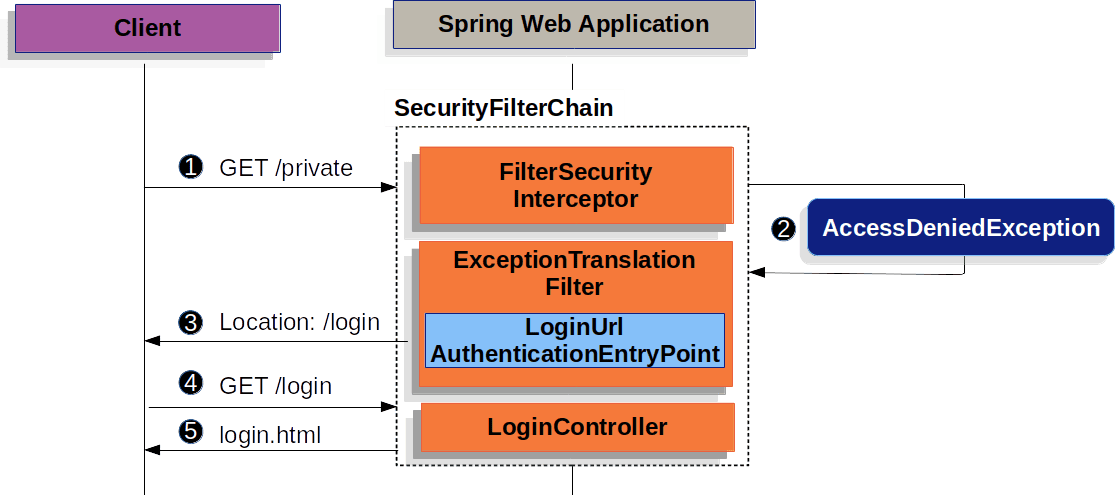
表单登录的过程,进行账号密码认证
10.4 MyBatis
10.5 JPA
10.6 日志框架
什么是日志系统和日志门面?分别有哪些框架?
日志系统是具体的日志框架,日志门面是不提供日志的具体实现,而是在运行时动态的绑定日志实现组件来工作,是一种外观模式。
日志系统
- java.util.logging (JUL),JDK1.4 开始,通过 java.util.logging 提供日志功能。虽然是官方自带的log lib,JUL的使用确不广泛。
- Log4j,Log4j 是 apache 的一个开源项目,创始人 Ceki Gulcu。Log4j 应该说是 Java 领域资格最老,应用最广的日志工具。Log4j 是高度可配置的,并可通过在运行时的外部文件配置。它根据记录的优先级别,并提供机制,以指示记录信息到许多的目的地,诸如:数据库,文件,控制台,UNIX 系统日志等。Log4j 的短板在于性能,在Logback 和 Log4j2 出来之后,Log4j的使用也减少了。
- Logback,Logback 是由 log4j 创始人 Ceki Gulcu 设计的又一个开源日志组件,是作为 Log4j 的继承者来开发的,提供了性能更好的实现,异步 logger,Filter等更多的特性。
- Log4j2,维护 Log4j 的人为了性能又搞出了 Log4j2。Log4j2 和 Log4j1.x 并不兼容,设计上很大程度上模仿了 SLF4J/Logback,性能上也获得了很大的提升。Log4j2 也做了 Facade/Implementation 分离的设计,分成了 log4j-api 和 log4j-core。
日志门面
- common-logging,common-logging 是 apache 的一个开源项目。也称Jakarta Commons Logging,缩写 JCL。
- slf4j, 全称为 Simple Logging Facade for Java,即 java 简单日志门面。作者又是 Ceki Gulcu!这位大神写了 Log4j、Logback 和 slf4j。类似于 Common-Logging,slf4j 是对不同日志框架提供的一个 API 封装,可以在部署的时候不修改任何配置即可接入一种日志实现方案。但是,slf4j 在编译时静态绑定真正的 Log 库。使用 SLF4J 时,如果你需要使用某一种日志实现,那么你必须选择正确的 SLF4J 的 jar 包的集合(各种桥接包)。
日志库中使用桥接模式解决什么问题?
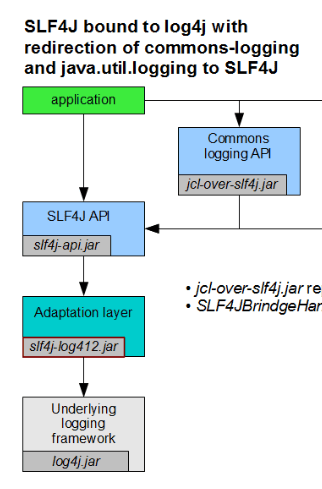
- 什么是桥接呢?
假如你正在开发应用程序所调用的组件当中已经使用了 common-logging,这时你需要 jcl-over-slf4j.jar 把日志信息输出重定向到 slf4j-api,slf4j-api 再去调用 slf4j 实际依赖的日志组件。这个过程称为桥接。下图是官方的 slf4j 桥接策略图:

从图中应该可以看出,无论你的老项目中使用的是 common-logging 或是直接使用 log4j、java.util.logging,都可以使用对应的桥接 jar 包来解决兼容问题。
- slf4j 兼容 common-logging
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>1.7.12</version>
</dependency>
- slf4j 兼容 log4j
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
<version>1.7.12</version>
</dependency>
在日志配置时会考虑哪些点?
- 支持日志路径,日志level等配置
- 日志控制配置通过application.yml下发
- 按天生成日志,当天的日志>50MB回滚
- 最多保存10天日志
- 生成的日志中Pattern自定义
- Pattern中添加用户自定义的MDC字段,比如用户信息(当前日志是由哪个用户的请求产生),request信息。此种方式可以通过AOP切面控制,在MDC中添加requestID,在spring-logback.xml中配置Pattern。
- 根据不同的运行环境设置Profile - dev,test,product
- 对控制台,Err和全量日志分别配置
- 对第三方包路径日志控制
对Java日志组件选型的建议?
slf4j已经成为了Java日志组件的明星选手,可以完美替代JCL,使用JCL桥接库也能完美兼容一切使用JCL作为日志门面的类库,现在的新系统已经没有不使用slf4j作为日志API的理由了。
日志记录服务方面,log4j在功能上输于logback和log4j2,在性能方面log4j2则全面超越log4j和logback。所以新系统应该在logback和log4j2中做出选择,对于性能有很高要求的系统,应优先考虑log4j2。
对日志架构使用比较好的实践?
说几个点:
- 总是使用Log Facade,而不是具体Log Implementation
- 只添加一个 Log Implementation依赖
- 具体的日志实现依赖应该设置为optional和使用runtime scope
- 如果有必要, 排除依赖的第三方库中的Log Impementation依赖
- 避免为不会输出的log付出代价
- 日志格式中最好不要使用行号,函数名等字段
对现有系统日志架构的改造建议?
如果现有系统使用JCL作为日志门面,又确实面临着JCL的ClassLoader机制带来的问题,完全可以引入slf4j并通过桥接库将JCL api输出的日志桥接至slf4j,再通过适配库适配至现有的日志输出服务(如log4j),如下图:
这样做不需要任何代码级的改造,就可以解决JCL的ClassLoader带来的问题,但没有办法享受日志模板等slf4j的api带来的优点。不过之后在现系统上开发的新功能就可以使用slf4j的api了,老代码也可以分批进行改造。
如果现有系统使用JCL作为日志门面,又头疼JCL不支持logback和log4j2等新的日志服务,也可以通过桥接库以slf4j替代JCL,但同样无法直接享受slf4j api的优点。
如果想要使用slf4j的api,那么就不得不进行代码改造了,当然改造也可以参考1中提到的方式逐步进行。
如果现系统面临着log4j的性能问题,可以使用Apache Logging提供的log4j到log4j2的桥接库log4j-1.2-api,把通过log4j api输出的日志桥接至log4j2。这样可以最快地使用上log4j2的先进性能,但组件中缺失了slf4j,对后续进行日志架构改造的灵活性有影响。另一种办法是先把log4j桥接至slf4j,再使用slf4j到log4j2的适配库。这样做稍微麻烦了一点,但可以逐步将系统中的日志输出标准化为使用slf4j的api,为后面的工作打好基础。
10.7 Tomcat
Tomcat 整体架构的设计?
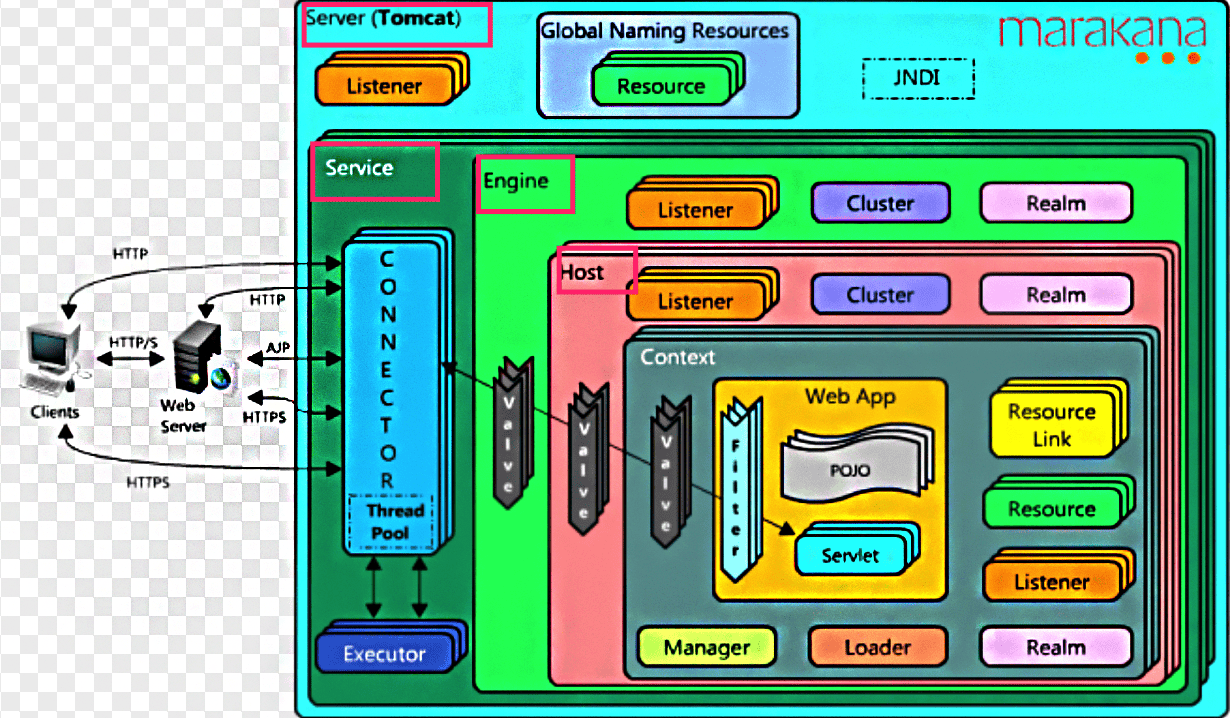
从组件的角度看
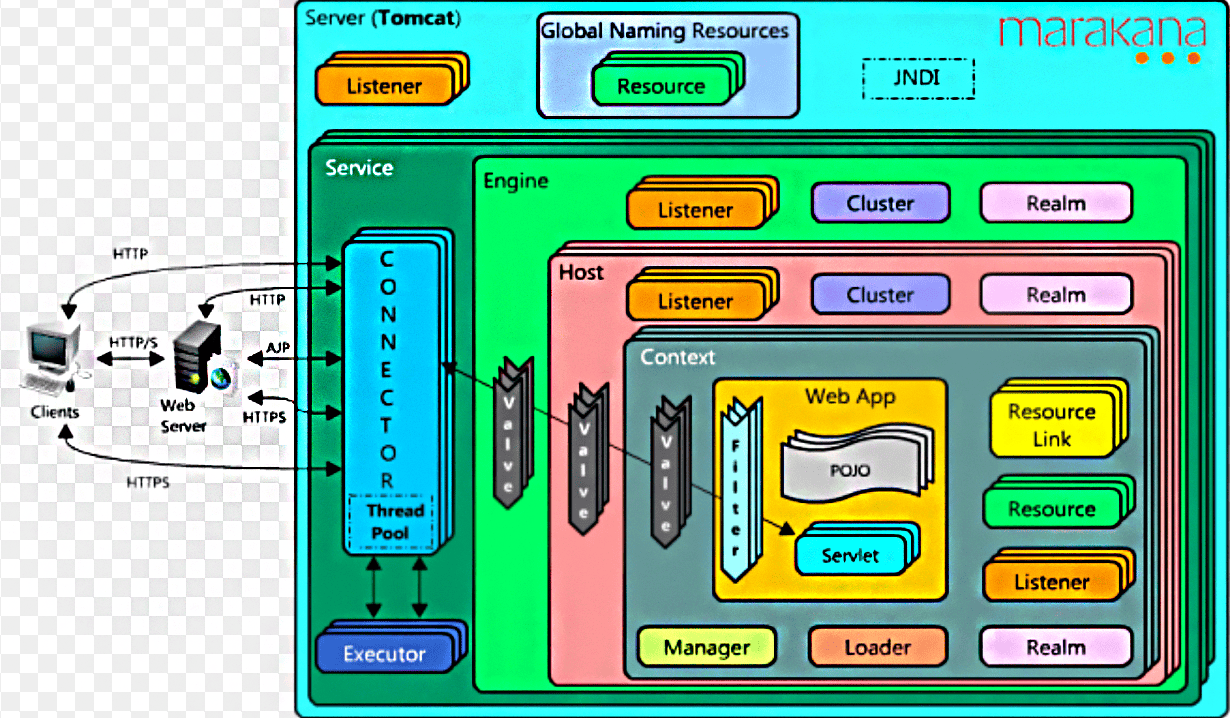
Server: 表示服务器,它提供了一种优雅的方式来启动和停止整个系统,不必单独启停连接器和容器;它是Tomcat构成的顶级构成元素,所有一切均包含在Server中;
Service: 表示服务,Server可以运行多个服务。比如一个Tomcat里面可运行订单服务、支付服务、用户服务等等;Server的实现类StandardServer可以包含一个到多个Services, Service的实现类为StandardService调用了容器(Container)接口,其实是调用了Servlet Engine(引擎),而且StandardService类中也指明了该Service归属的Server;
Container: 表示容器,可以看做Servlet容器;引擎(Engine)、主机(Host)、上下文(Context)和Wraper均继承自Container接口,所以它们都是容器。
- Engine -- 引擎
- Host -- 主机
- Context -- 上下文
- Wrapper -- 包装器
Connector: 表示连接器, 它将Service和Container连接起来,首先它需要注册到一个Service,它的作用就是把来自客户端的请求转发到Container(容器),这就是它为什么称作连接器, 它支持的协议如下:
- 支持AJP协议
- 支持Http协议
- 支持Https协议
Service内部还有各种支撑组件,下面简单罗列一下这些组件
- Manager -- 管理器,用于管理会话Session
- Logger -- 日志器,用于管理日志
- Loader -- 加载器,和类加载有关,只会开放给Context所使用
- Pipeline -- 管道组件,配合Valve实现过滤器功能
- Valve -- 阀门组件,配合Pipeline实现过滤器功能
- Realm -- 认证授权组件
Tomcat 一个请求的处理流程?
假设来自客户的请求为:http://localhost:8080/test/index.jsp 请求被发送到本机端口8080,被在那里侦听的Coyote HTTP/1.1 Connector,然后
- Connector把该请求交给它所在的Service的Engine来处理,并等待Engine的回应
- Engine获得请求localhost:8080/test/index.jsp,匹配它所有虚拟主机Host
- Engine匹配到名为localhost的Host(即使匹配不到也把请求交给该Host处理,因为该Host被定义为该Engine的默认主机)
- localhost Host获得请求/test/index.jsp,匹配它所拥有的所有Context
- Host匹配到路径为/test的Context(如果匹配不到就把该请求交给路径名为""的Context去处理)
- path="/test"的Context获得请求/index.jsp,在它的mapping table中寻找对应的servlet
- Context匹配到URL PATTERN为*.jsp的servlet,对应于JspServlet类,构造HttpServletRequest对象和HttpServletResponse对象,作为参数调用JspServlet的doGet或doPost方法
- Context把执行完了之后的HttpServletResponse对象返回给Host
- Host把HttpServletResponse对象返回给Engine
- Engine把HttpServletResponse对象返回给Connector
- Connector把HttpServletResponse对象返回给客户browser
Tomcat 中类加载机制?
在Bootstrap中我们可以看到有如下三个classloader
ClassLoader commonLoader = null;
ClassLoader catalinaLoader = null;
ClassLoader sharedLoader = null;
- 为什么要设计多个类加载器?
如果所有的类都使用一个类加载器来加载,会出现什么问题呢?
假如我们自己编写一个类java.util.Object,它的实现可能有一定的危险性或者隐藏的bug。而我们知道Java自带的核心类里面也有java.util.Object,如果JVM启动的时候先行加载的是我们自己编写的java.util.Object,那么就有可能出现安全问题!
所以,Sun(后被Oracle收购)采用了另外一种方式来保证最基本的、也是最核心的功能不会被破坏。你猜的没错,那就是双亲委派模式!
- 什么是双亲委派模型?
双亲委派模型解决了类错乱加载的问题,也设计得非常精妙。
双亲委派模式对类加载器定义了层级,每个类加载器都有一个父类加载器。在一个类需要加载的时候,首先委派给父类加载器来加载,而父类加载器又委派给祖父类加载器来加载,以此类推。如果父类及上面的类加载器都加载不了,那么由当前类加载器来加载,并将被加载的类缓存起来。
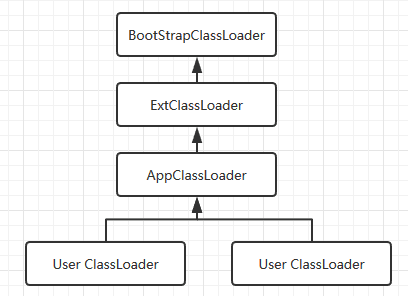
所以上述类是这么加载的
Java自带的核心类 -- 由启动类加载器加载
Java支持的可扩展类 -- 由扩展类加载器加载
我们自己编写的类 -- 默认由应用程序类加载器或其子类加载
为什么Tomcat的类加载器也不是双亲委派模型?
Java默认的类加载机制是通过双亲委派模型来实现的,而Tomcat实现的方式又和双亲委派模型有所区别。
原因在于一个Tomcat容器允许同时运行多个Web程序,每个Web程序依赖的类又必须是相互隔离的。因此,如果Tomcat使用双亲委派模式来加载类的话,将导致Web程序依赖的类变为共享的。
举个例子,假如我们有两个Web程序,一个依赖A库的1.0版本,另一个依赖A库的2.0版本,他们都使用了类xxx.xx.Clazz,其实现的逻辑因类库版本的不同而结构完全不同。那么这两个Web程序的其中一个必然因为加载的Clazz不是所使用的Clazz而出现问题!而这对于开发来说是非常致命的!
Tomcat Container设计?
我们看下几个Container之间的关系:
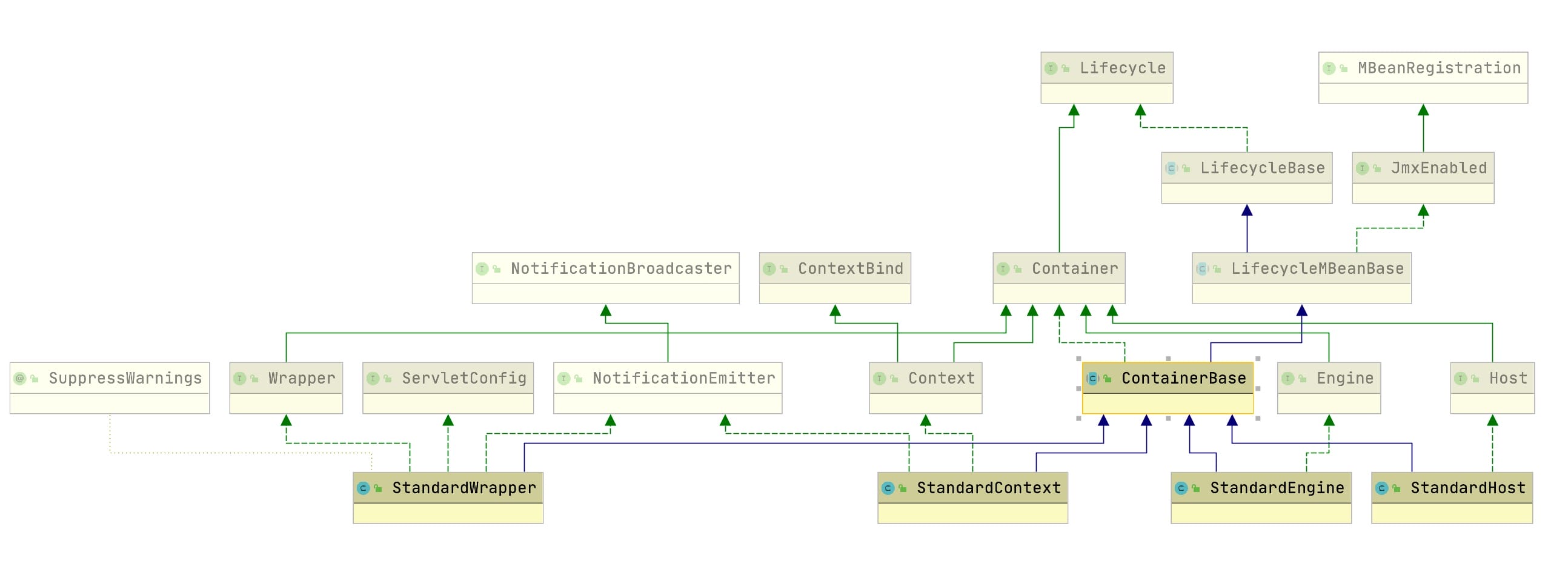
从上图上,我们也可以看出Container顶层也是基于Lifecycle的组件设计的。
- 在设计Container组件层次组件时,上述4个组件分别做什么的呢?为什么要四种组件呢?
Engine - 表示整个catalina的servlet引擎,多数情况下包含一个或多个子容器,这些子容器要么是Host,要么是Context实现,或者是其他自定义组。
Host - 表示包含多个Context的虚拟主机的。
Context — 表示一个ServletContext,表示一个webapp,它通常包含一个或多个wrapper。
Wrapper - 表示一个servlet定义的(如果servlet本身实现了SingleThreadModel,则可能支持多个servlet实例)。
- 结合整体的框架图中上述组件部分,我们看下包含了什么?

很明显,除了四个组件的嵌套关系,Container中还包含了Realm,Cluster,Listeners, Pipleline等支持组件。
这一点,还可以通过相关注释可以看出:
**Loader** - Class loader to use for integrating new Java classes for this Container into the JVM in which Catalina is running.
**Logger** - Implementation of the log() method signatures of the ServletContext interface.
**Manager** - Manager for the pool of Sessions associated with this Container.
**Realm** - Read-only interface to a security domain, for authenticating user identities and their corresponding roles.
**Resources** - JNDI directory context enabling access to static resources, enabling custom linkages to existing server components when Catalina is embedded in a larger server.
Tomcat LifeCycle机制?
- Server及其它组件
- Server后续组件生命周期及初始化
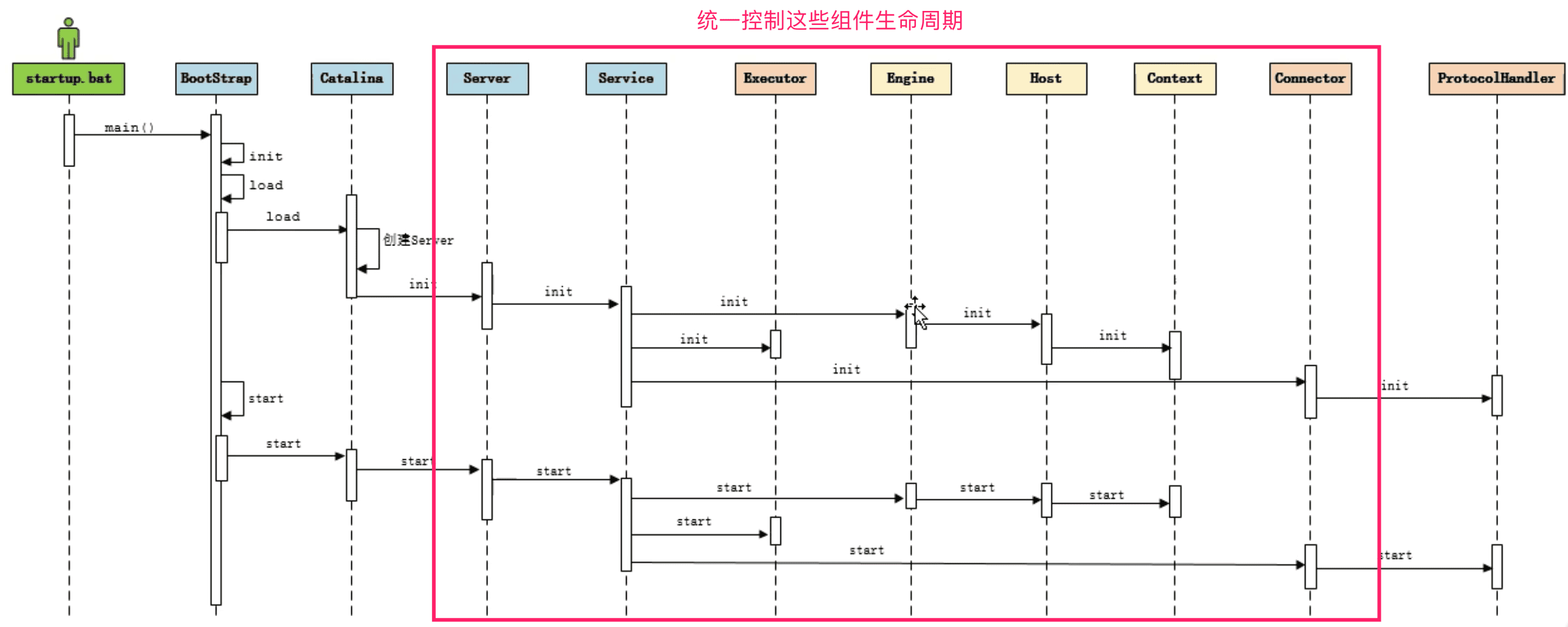
- Server的依赖结构
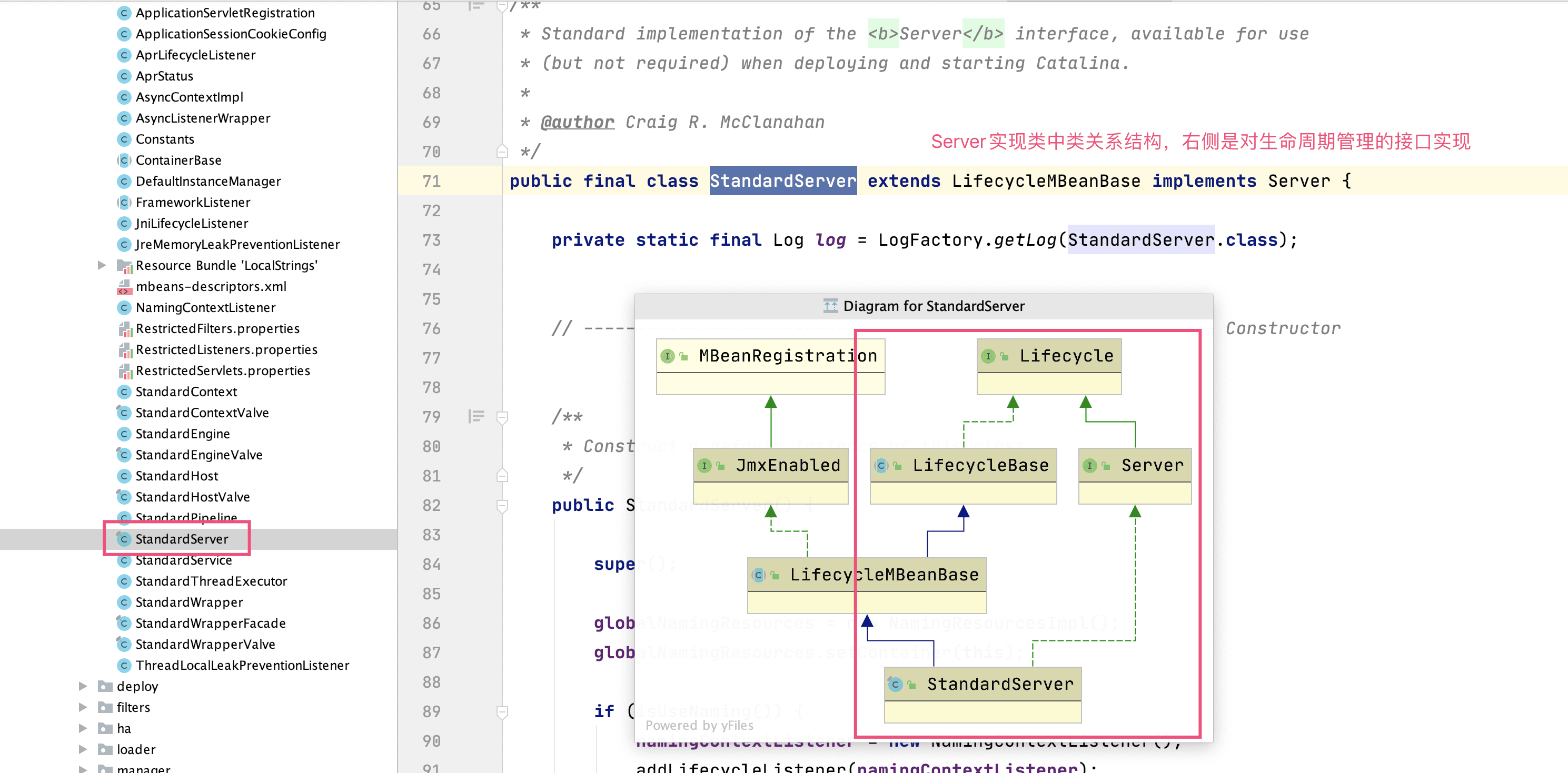
public interface Lifecycle {
/** 第1类:针对监听器 **/
// 添加监听器
public void addLifecycleListener(LifecycleListener listener);
// 获取所以监听器
public LifecycleListener[] findLifecycleListeners();
// 移除某个监听器
public void removeLifecycleListener(LifecycleListener listener);
/** 第2类:针对控制流程 **/
// 初始化方法
public void init() throws LifecycleException;
// 启动方法
public void start() throws LifecycleException;
// 停止方法,和start对应
public void stop() throws LifecycleException;
// 销毁方法,和init对应
public void destroy() throws LifecycleException;
/** 第3类:针对状态 **/
// 获取生命周期状态
public LifecycleState getState();
// 获取字符串类型的生命周期状态
public String getStateName();
}
Tomcat 中Executor?
1.Tomcat希望将Executor也纳入Lifecycle生命周期管理,所以让它实现了Lifecycle接口
2.引入超时机制:也就是说当work queue满时,会等待指定的时间,如果超时将抛出RejectedExecutionException,所以这里增加了一个
void execute(Runnable command, long timeout, TimeUnit unit)方法; 其实本质上,它构造了JUC中ThreadPoolExecutor,通过它调用ThreadPoolExecutor的void execute(Runnable command, long timeout, TimeUnit unit)方法。
Tomcat 中的设计模式?
- 责任链模式:管道机制
在软件开发的常接触的责任链模式是FilterChain,它体现在很多软件设计中:
- 比如Spring Security框架中
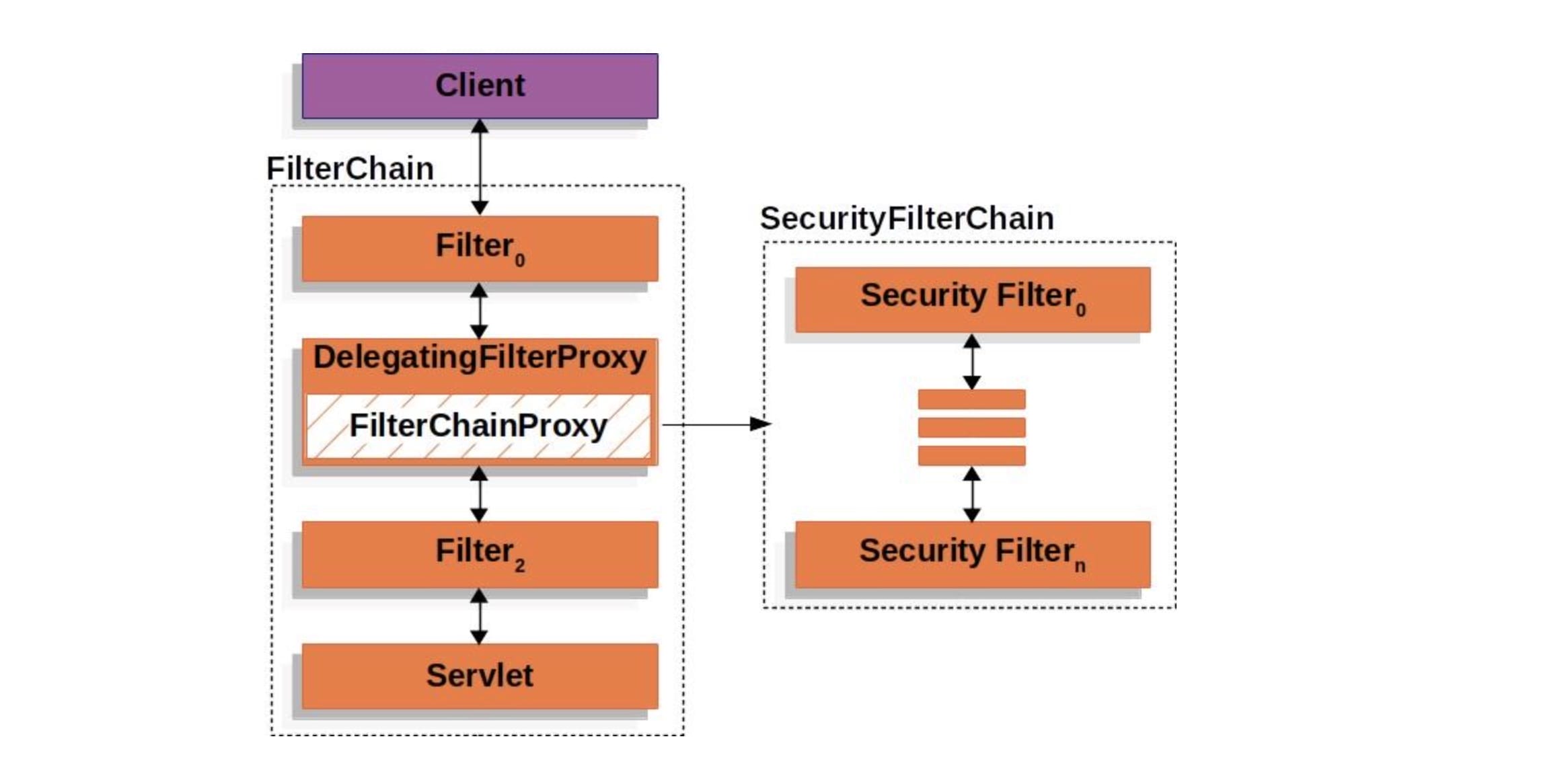
- 比如HttpServletRequest处理的过滤器中
当一个request过来的时候,需要对这个request做一系列的加工,使用责任链模式可以使每个加工组件化,减少耦合。也可以使用在当一个request过来的时候,需要找到合适的加工方式。当一个加工方式不适合这个request的时候,传递到下一个加工方法,该加工方式再尝试对request加工。
网上找了图,这里我们后文将通过Tomcat请求处理向你阐述。

外观模式:request请求
观察者模式:事件监听
java中的事件机制的参与者有3种角色
Event Eource:事件源,发起事件的主体。Event Object:事件状态对象,传递的信息载体,就好比Watcher的update方法的参数,可以是事件源本身,一般作为参数存在于listerner 的方法之中。Event Listener:事件监听器,当它监听到event object产生的时候,它就调用相应的方法,进行处理。
其实还有个东西比较重要:事件环境,在这个环境中,可以添加事件监听器,可以产生事件,可以触发事件监听器。

- 模板方式: Lifecycle
LifecycleBase是使用了状态机+模板模式来实现的。模板方法有下面这几个:
// 初始化方法
protected abstract void initInternal() throws LifecycleException;
// 启动方法
protected abstract void startInternal() throws LifecycleException;
// 停止方法
protected abstract void stopInternal() throws LifecycleException;
// 销毁方法
protected abstract void destroyInternal() throws LifecycleException;
Tomcat JMX拓展机制?
11 开发工具
开发工具问题汇总。
11.1 Git
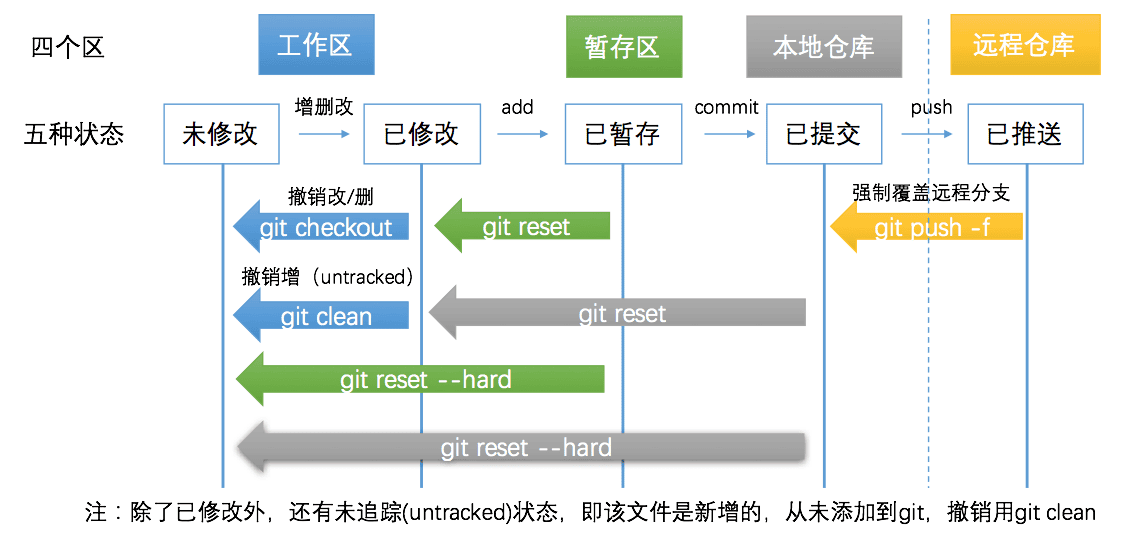
Git中5个区,和具体操作?
- 代码提交和同步代码
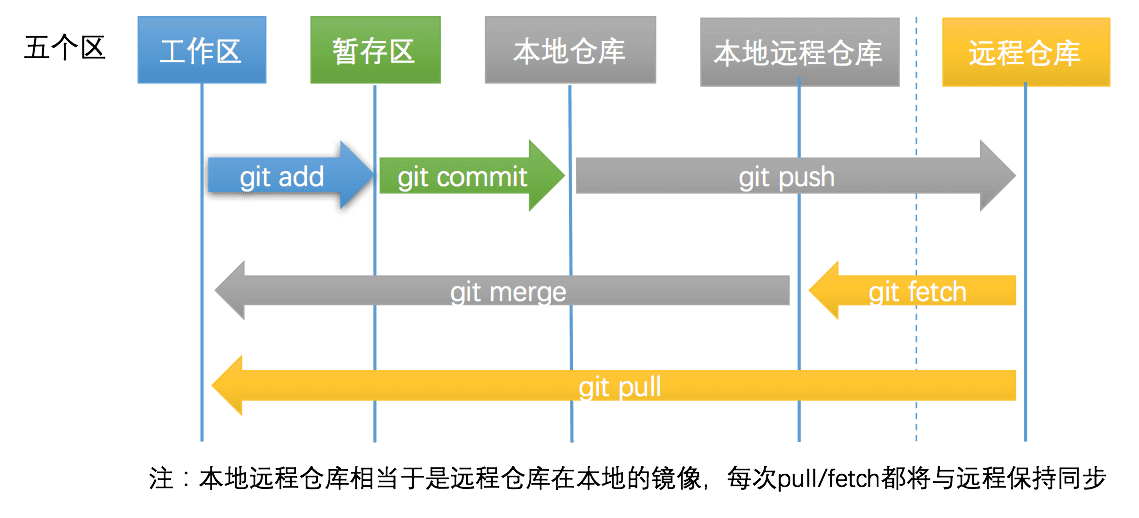
- 代码撤销和撤销同步
平时是怎么提交代码的?
- 第零步: 工作区与仓库保持一致
- 第一步: 文件增删改,变为已修改状态
- 第二步: git add ,变为已暂存状态
$ git status
$ git add --all # 当前项目下的所有更改
$ git add . # 当前目录下的所有更改
$ git add xx/xx.py xx/xx2.py # 添加某几个文件
- 第三步: git commit,变为已提交状态
$ git commit -m "<这里写commit的描述>"
- 第四步: git push,变为已推送状态
$ git push -u origin master # 第一次需要关联上
$ git push # 之后再推送就不用指明应该推送的远程分支了
$ git branch # 可以查看本地仓库的分支
$ git branch -a # 可以查看本地仓库和本地远程仓库(远程仓库的本地镜像)的所有分支
在某个分支下,我最常用的操作如下
$ git status
$ git add -a
$ git status
$ git commit -m 'xxx'
$ git pull --rebase
$ git push origin xxbranch
11.2 Maven
Maven中包的依赖原则?如何解决冲突?
- 依赖原则?
- 依赖路径最短优先原则
A -> B -> C -> X(1.0)
A -> D -> X(2.0)
由于 X(2.0) 路径最短,所以使用 X(2.0)。
- 声明顺序优先原则
A -> B -> X(1.0)
A -> C -> X(2.0)
在 POM 中最先声明的优先,上面的两个依赖如果先声明 B,那么最后使用 X(1.0)。
- 覆写优先原则
子 POM 内声明的依赖优先于父 POM 中声明的依赖。
- 如何解决冲突?
找到 Maven 加载的 Jar 包版本,使用
mvn dependency:tree查看依赖树,根据依赖原则来调整依赖在 POM 文件的声明顺序。发现了冲突的包之后,剩下的就是选择一个合适版本的包留下,如果是传递依赖的包正确,那么把显示依赖的包exclude掉。如果是某一个传递依赖的包有问题,那么我们需要手动把这个传递依赖execlude掉
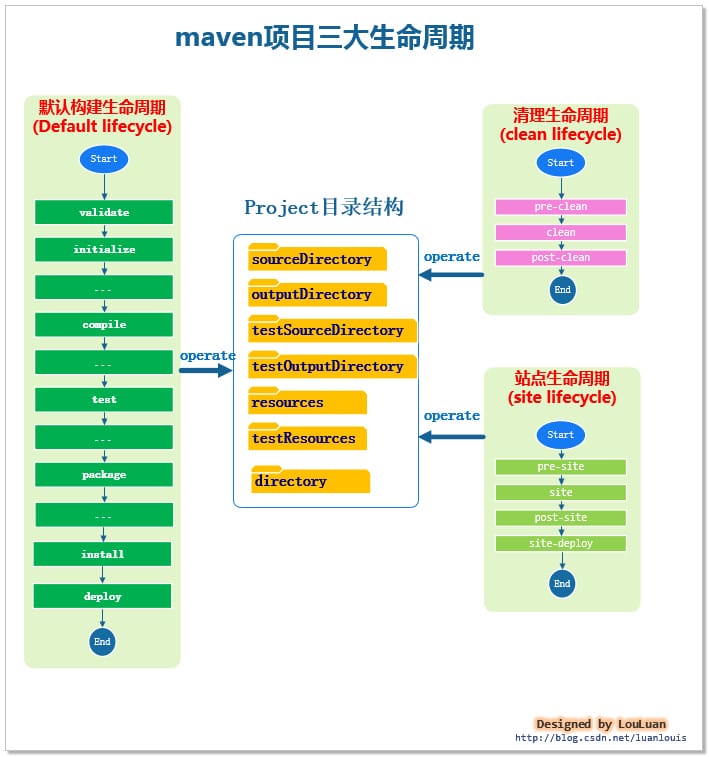
Maven 项目生命周期与构建原理?
Maven从项目的三个不同的角度,定义了单套生命周期,三套生命周期是相互独立的,它们之间不会相互影响。
- 默认构建生命周期(Default Lifeclyle): 该生命周期表示这项目的构建过程,定义了一个项目的构建要经过的不同的阶段。
- 清理生命周期(Clean Lifecycle): 该生命周期负责清理项目中的多余信息,保持项目资源和代码的整洁性。一般拿来清空directory(即一般的target)目录下的文件。
- 站点管理生命周期(Site Lifecycle) :向我们创建一个项目时,我们有时候需要提供一个站点,来介绍这个项目的信息,如项目介绍,项目进度状态、项目组成成员,版本控制信息,项目javadoc索引信息等等。站点管理生命周期定义了站点管理过程的各个阶段。
12 架构
架构相关。
12.1 架构基础
如何理解架构的演进?
- 初始阶段的网站架构
- 应用服务和数据服务分离
- 使用缓存改善网站性能
- 使用应用服务器集群改善网站的并发处理能力
- 数据库读写分离
- 使用反向代理和CDN加上网站相应
- 使用分布式文件系统和分布式数据库系统
- 使用NoSQL和搜索引擎
- 业务拆分 : 拆成A, B服务,以及MQ服务

- 分布式服务
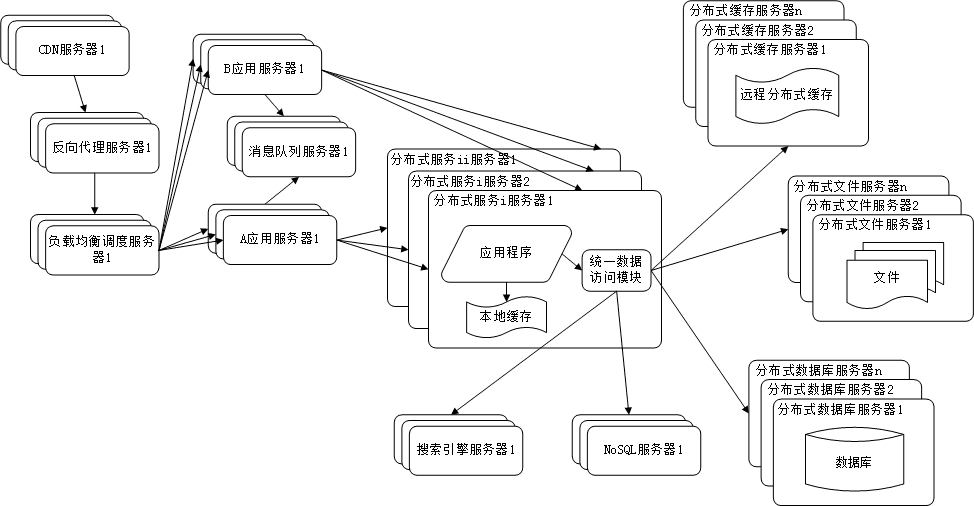
如何理解架构的服务化趋势?
- 方向一: 架构服务化
- 单体分层架构
- 面向服务架构 -SOA
- 微服务架构 - Microservices
- 云原生架构 - Cloud Native
- 方向二: 部署容器编排化
- 虚拟机
- 容器
- Kubernetes 与编排
架构中有哪些技术点?
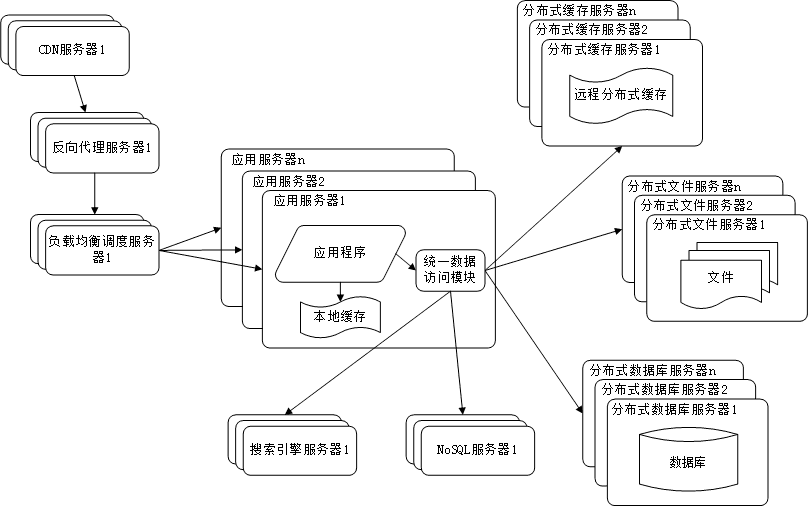
所谓网站架构模式即为了解决大型网站面临的高并发访问、海量数据、高可靠运行灯一系列问题与挑战。为此,在实践中提出了许多解决方案,以实现网站高性能、高可靠性、易伸缩、可扩展、安全等各种技术架构目标。
- 分层
分层是企业应用系统中最常见的一种架构模式,将系统在横向维度上切分成几个部分,每个部分负责一部分相对简单并比较单一的职责,然后通过上层对下层的依赖和调度组成一个完整的系统。
在网站的分层架构中,常见的为3层,即应用层、服务层、数据层:
- 应用层具体负责业务和视图的展示;
- 服务层为应用层提供服务支持;
- 数据库提供数据存储访问服务,如数据库、缓存、文件、搜索引擎等。
分层架构是逻辑上的,在物理部署上,三层架构可以部署在同一个物理机器上,但是随着网站业务的发展,必然需要对已经分层的模块分离部署,即三层结构分别部署在不同的服务器上,是网站拥有更多的计算资源以应对越来越多的用户访问。
所以虽然分层架构模式最初的目的是规划软件清晰的逻辑结构以便于开发维护,但在网站的发展过程中,分层结构对网站支持高并发向分布式方向的发展至关重要。
- 分隔
如果说分层是将软件在横向方面进行切分,那么分隔就是在纵向方面对软件进行切分。
网站越大,功能越复杂,服务和数据处理的种类也越多,将这些不同的功能和服务分隔开来,包装成高内聚低耦合的模块单元,不仅有助于软件的开发维护也便于不同模块的分布式部署,提高网站的并发处理能力和功能扩展能力。
大型网站分隔的粒度可能会很小。比如在应用层,将不同业务进行分隔,例如将购物、论坛、搜索、广告分隔成不同的应用,有对立的团队负责,部署在不同的服务器上。
- 分布式
对于大型网站,分层和分隔的一个主要目的是为了切分后的模块便于分布式部署,即将不同模块部署在不同的服务器上,通过远程调用协同工作。分布式意味着可以使用更多的计算机完同样的工作,计算机越多,CPU、内存、存储资源就越多,能过处理的并发访问和数据量就越大,进而能够为更多的用户提供服务。
在网站应用中,常用的分布式方案有一下几种.
分布式应用和服务:将分层和分隔后的应用和服务模块分布式部署,可以改善网站性能和并发性、加快开发和发布速度、减少数据库连接资源消耗。分布式静态资源:网站的静态资源如JS、CSS、Logo图片等资源对立分布式部署,并采用独立的域名,即人们常说的动静分离。静态资源分布式部署可以减轻应用服务器的负载压力;通过使用独立域名加快浏览器并发加载的速度。分布式数据和存储:大型网站需要处理以P为单位的海量数据,单台计算机无法提供如此大的存储空间,这些数据库需要分布式存储。分布式计算:目前网站普遍使用Hadoop和MapReduce分布式计算框架进行此类批处理计算,其特点是移动计算而不是移动数据,将计算程序分发到数据所在的位置以加速计算和分布式计算。
- 集群
对于用户访问集中的模块需要将独立部署的服务器集群化,即多台服务器部署相同的应用构成一个集群,通过负载均衡设备共同对外提供服务。
服务器集群能够为相同的服务提供更多的并发支持,因此当有更多的用户访问时,只需要向集群中加入新的机器即可;另外可以实现当其中的某台服务器发生故障时,可以通过负载均衡的失效转移机制将请求转移至集群中其他的服务器上,因此可以提高系统的可用性。
- 缓存
缓存目的就是减轻服务器的计算,使数据直接返回给用户。在现在的软件设计中,缓存已经无处不在。具体实现有CDN、反向代理、本地缓存、分布式缓存等。
使用缓存有两个条件:访问数据热点不均衡,即某些频繁访问的数据需要放在缓存中;数据在某个时间段内有效,不过很快过期,否则会因为数据过期而脏读,影响数据的正确性。
- 异步
使用异步,业务之间的消息传递不是同步调用,而是将一个业务操作分成多个阶段,每个阶段之间通过共享数据的方法异步执行进行协作。
具体实现则在单一服务器内部可用通过多线程共享内存对了的方式处理;在分布式系统中可用通过分布式消息队列来实现异步。
异步架构的典型就是生产者消费者方式,两者不存在直接调用。
- 冗余
网站需要7×24小时连续运行,那么就得有相应的冗余机制,以防某台机器宕掉时无法访问,而冗余则可以通过部署至少两台服务器构成一个集群实现服务高可用。数据库除了定期备份还需要实现冷热备份。甚至可以在全球范围内部署灾备数据中心。
- 自动化
具体有自动化发布过程,自动化代码管理、自动化测试、自动化安全检测、自动化部署、自动化监控、自动化报警、自动化失效转移、自动化失效恢复等。
- 安全
网站在安全架构方面有许多模式:通过密码和手机校验码进行身份认证;登录、交易需要对网络通信进行加密;为了防止机器人程序滥用资源,需要使用验证码进行识别;对常见的XSS攻击、SQL注入需要编码转换;垃圾信息需要过滤等。
- 敏捷性
积极接受需求变更,快速响应业务发展需求。
12.2 缓存
谈谈架构中的缓存应用?
缓存有各类特征,而且有不同介质的区别,那么实际工程中我们怎么去对缓存分类呢? 在目前的应用服务框架中,比较常见的,时根据缓存雨应用的藕合度,分为local cache(本地缓存)和remote cache(分布式缓存):
本地缓存:指的是在应用中的缓存组件,其最大的优点是应用和cache是在同一个进程内部,请求缓存非常快速,没有过多的网络开销等,在单应用不需要集群支持或者集群情况下各节点无需互相通知的场景下使用本地缓存较合适;同时,它的缺点也是应为缓存跟应用程序耦合,多个应用程序无法直接的共享缓存,各应用或集群的各节点都需要维护自己的单独缓存,对内存是一种浪费。
分布式缓存:指的是与应用分离的缓存组件或服务,其最大的优点是自身就是一个独立的应用,与本地应用隔离,多个应用可直接的共享缓存。
目前各种类型的缓存都活跃在成千上万的应用服务中,还没有一种缓存方案可以解决一切的业务场景或数据类型,我们需要根据自身的特殊场景和背景,选择最适合的缓存方案。缓存的使用是程序员、架构师的必备技能,好的程序员能根据数据类型、业务场景来准确判断使用何种类型的缓存,如何使用这种缓存,以最小的成本最快的效率达到最优的目的。
在开发中缓存具体如何实现?
- 本地缓存
- 成员变量或局部变量实现, 比如map
- 静态变量实现
- Ehcache
- Guava Cache
- 分布式缓存
- Redis集群+ Spring Cache注解方式
缓存会有哪些问题?如何解决?
参见redis缓存问题
使用缓存的经验?
不合理使用缓存非但不能提高系统的性能,还会成为系统的累赘,甚至风险。
- 频繁修改的数据
如果缓存中保存的是频繁修改的数据,就会出现数据写入缓存后,应用还来不及读取缓存,数据就已经失效,徒增系统负担。一般来说,数据的读写比在2:1(写入一次缓存,在数据更新前至少读取两次)以上,缓存才有意义。
- 没有热点的访问
如果应用系统访问数据没有热点,不遵循二八定律,那么缓存就没有意义。
- 数据不一致与脏读
一般会对缓存的数据设置失效时间,一旦超过失效时间,就要从数据库中重新加载。因此要容忍一定时间的数据不一致,如卖家已经编辑了商品属性,但是需要过一段时间才能被买家看到。还有一种策略是数据更新立即更新缓存,不过这也会带来更多系统开销和事务一致性问题。
- 缓存可用性
缓存会承担大部分数据库访问压力,数据库已经习惯了有缓存的日子,所以当缓存服务崩溃时,数据库会因为完全不能承受如此大压力而宕机,导致网站不可用。这种情况被称作缓存雪崩,发生这种故障,甚至不能简单地重启缓存服务器和数据库服务器来恢复。
实践中,有的网站通过缓存热备份等手段提高缓存可用性:当某台缓存服务器宕机时,将缓存访问切换到热备服务器上。但这种设计有违缓存的初衷,缓存根本就不应该当做一个可靠的数据源来使用。
通过分布式缓存服务器集群,将缓存数据分布到集群多台服务器上可在一定程度上改善缓存的可用性。当一台缓存服务器宕机时,只有部分缓存数据丢失,重新从数据库加载这部分数据不会产生很大的影响。
- 缓存预热warm up
缓存中存放的是热点数据,热点数据又是缓存系统利用LRU(最近最久未用算法)对不断访问的数据筛选淘汰出来,这个过程需要花费较长的时间。新系统的缓存系统如果没有任何数据,在重建缓存数据的过程中,系统的性能和数据库负载都不太好,那么最好在缓存系统启动时就把热点数据加载好,这个缓存预加载手段叫缓存预热。对于一些元数据如城市地名列表、类目信息,可以在启动时加载数据库中全部数据到缓存进行预热。
- 避免缓存穿透
如果因为不恰当的业务、或者恶意攻击持续高并发地请求某个不存在的数据,由于缓存没有保存该数据,所有的请求都会落到数据库上,会对数据库造成压力,甚至崩溃。一个简单的对策是将不存在的数据也缓存起来(其value为null)。
12.3 限流
什么是限流?三种限流的算法?
每个系统都有服务的上线,所以当流量超过服务极限能力时,系统可能会出现卡死、崩溃的情况,所以就有了降级和限流。限流其实就是:当高并发或者瞬时高并发时,为了保证系统的稳定性、可用性,系统以牺牲部分请求为代价或者延迟处理请求为代价,保证系统整体服务可用。
令牌桶(Token Bucket)、漏桶(leaky bucket)和计数器算法是最常用的三种限流的算法:
- 令牌桶方式(Token Bucket)
- Guava RateLimiter
令牌桶算法是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。先有一个木桶,系统按照固定速度,往桶里加入Token,如果桶已经满了就不再添加。当有请求到来时,会各自拿走一个Token,取到Token 才能继续进行请求处理,没有Token 就拒绝服务。
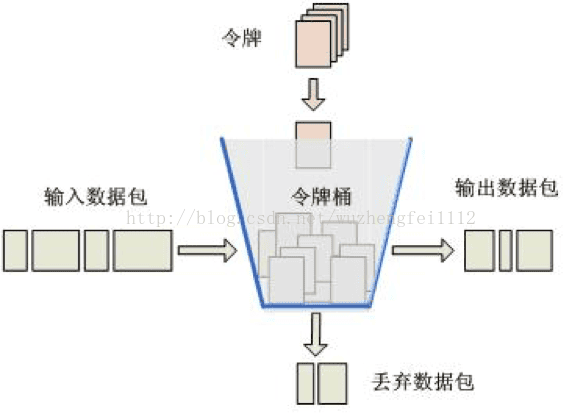
这里如果一段时间没有请求时,桶内就会积累一些Token,下次一旦有突发流量,只要Token足够,也能一次处理,所以令牌桶算法的特点是允许突发流量。
- 漏桶
水(请求)先进入到漏桶里,漏桶以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求,可以看出漏桶算法能强行限制数据的传输速率。

可见这里有两个变量,一个是桶的大小,支持流量突发增多时可以存多少的水(burst),另一个是水桶漏洞的大小(rate)。
因为漏桶的漏出速率是固定的参数,所以,即使网络中不存在资源冲突(没有发生拥塞),漏桶算法也不能使流突发(burst)到端口速率.因此,漏桶算法对于存在突发特性的流量来说缺乏效率.
- 计数器 计数器限流算法也是比较常用的,主要用来限制总并发数,比如数据库连接池大小、线程池大小、程序访问并发数等都是使用计数器算法。也是最简单粗暴的算法。
- 采用AtomicInteger
- 使用AomicInteger来进行统计当前正在并发执行的次数,如果超过域值就简单粗暴的直接响应给用户,说明系统繁忙,请稍后再试或其它跟业务相关的信息。
- 弊端:使用 AomicInteger 简单粗暴超过域值就拒绝请求,可能只是瞬时的请求量高,也会拒绝请求。
- 采用令牌Semaphore:
- 使用Semaphore信号量来控制并发执行的次数,如果超过域值信号量,则进入阻塞队列中排队等待获取信号量进行执行。如果阻塞队列中排队的请求过多超出系统处理能力,则可以在拒绝请求。
- 相对Atomic优点:如果是瞬时的高并发,可以使请求在阻塞队列中排队,而不是马上拒绝请求,从而达到一个流量削峰的目的。
- 采用ThreadPoolExecutor java线程池:
- 固定线程池大小,超出固定先线程池和最大的线程数,拒绝线程请求;
- 采用AtomicInteger
限流令牌桶和漏桶对比?
- 令牌桶是按照固定速率往桶中添加令牌,请求是否被处理需要看桶中令牌是否足够,当令牌数减为零时则拒绝新的请求;
- 漏桶则是按照常量固定速率流出请求,流入请求速率任意,当流入的请求数累积到漏桶容量时,则新流入的请求被拒绝;
- 令牌桶限制的是平均流入速率(允许突发请求,只要有令牌就可以处理,支持一次拿3个令牌,4个令牌),并允许一定程度突发流量;
- 漏桶限制的是常量流出速率(即流出速率是一个固定常量值,比如都是1的速率流出,而不能一次是1,下次又是2),从而平滑突发流入速率;
- 令牌桶允许一定程度的突发,而漏桶主要目的是平滑流入速率;
- 两个算法实现可以一样,但是方向是相反的,对于相同的参数得到的限流效果是一样的。
在单机情况下如何实现限流?
应用级限流方式只是单应用内的请求限流,不能进行全局限流。
- 限流总资源数
- 限流总并发/连接/请求数
- 限流某个接口的总并发/请求数
- 限流某个接口的时间窗请求数
- 平滑限流某个接口的请求数
- Guava RateLimiter
在分布式环境下如何实现限流?
我们需要分布式限流和接入层限流来进行全局限流。
- redis+lua实现中的lua脚本
- 使用Nginx+Lua实现的Lua脚本
12.4 降级和熔断
为什么会有容错?一般有哪些方式解决容错相关问题?
服务之间的依赖关系,如果有被依赖的服务挂了以后,造成其它服务也会出现请求堆积、资源占用,慢慢扩散到所有服务,引发雪崩效应。
而容错就是要解决这类问题,常见的方式:
- 主动超时:Http请求主动设置一个超时时间,超时就直接返回,不会造成服务堆积
- 限流:限制最大并发数
- 熔断:当错误数超过阈值时快速失败,不调用后端服务,同时隔一定时间放几个请求去重试后端服务是否能正常调用,如果成功则关闭熔断状态,失败则继续快速失败,直接返回。(此处有个重试,重试就是弹性恢复的能力)
- 隔离:把每个依赖或调用的服务都隔离开来,防止级联失败引起整体服务不可用
- 降级:服务失败或异常后,返回指定的默认信息

谈谈你对服务降级的理解?
由于爆炸性的流量冲击,对一些服务进行有策略的放弃,以此缓解系统压力,保证目前主要业务的正常运行。它主要是针对非正常情况下的应急服务措施:当此时一些业务服务无法执行时,给出一个统一的返回结果。
降级服务的特征
- 原因:整体负荷超出整体负载承受能力。
- 目的:保证重要或基本服务正常运行,非重要服务延迟使用或暂停使用
- 大小:降低服务粒度,要考虑整体模块粒度的大小,将粒度控制在合适的范围内
- 可控性:在服务粒度大小的基础上增加服务的可控性,后台服务开关的功能是一项必要配置(单机可配置文件,其他可领用数据库和缓存),可分为手动控制和自动控制。
- 次序:一般从外围延伸服务开始降级,需要有一定的配置项,重要性低的优先降级,比如可以分组设置等级1-10,当服务需要降级到某一个级别时,进行相关配置
降级方式
- 延迟服务:比如发表了评论,重要服务,比如在文章中显示正常,但是延迟给用户增加积分,只是放到一个缓存中,等服务平稳之后再执行。
- 在粒度范围内关闭服务(片段降级或服务功能降级):比如关闭相关文章的推荐,直接关闭推荐区
- 页面异步请求降级:比如商品详情页上有推荐信息/配送至等异步加载的请求,如果这些信息响应慢或者后端服务有问题,可以进行降级;
- 页面跳转(页面降级):比如可以有相关文章推荐,但是更多的页面则直接跳转到某一个地址
- 写降级:比如秒杀抢购,我们可以只进行Cache的更新,然后异步同步扣减库存到DB,保证最终一致性即可,此时可以将DB降级为Cache。
- 读降级:比如多级缓存模式,如果后端服务有问题,可以降级为只读缓存,这种方式适用于对读一致性要求不高的场景。
降级预案 在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
- 一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
- 警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
- 错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
- 严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
服务降级分类
- 降级按照是否自动化可分为:自动开关降级(超时、失败次数、故障、限流)和人工开关降级(秒杀、电商大促等)。
- 降级按照功能可分为:读服务降级、写服务降级。
- 降级按照处于的系统层次可分为:多级降级。
自动降级分类
- 超时降级:主要配置好超时时间和超时重试次数和机制,并使用异步机制探测回复情况
- 失败次数降级:主要是一些不稳定的api,当失败调用次数达到一定阀值自动降级,同样要使用异步机制探测回复情况
- 故障降级:比如要调用的远程服务挂掉了(网络故障、DNS故障、http服务返回错误的状态码、rpc服务抛出异常),则可以直接降级。降级后的处理方案有:默认值(比如库存服务挂了,返回默认现货)、兜底数据(比如广告挂了,返回提前准备好的一些静态页面)、缓存(之前暂存的一些缓存数据)
- 限流降级: 当我们去秒杀或者抢购一些限购商品时,此时可能会因为访问量太大而导致系统崩溃,此时开发者会使用限流来进行限制访问量,当达到限流阀值,后续请求会被降级;降级后的处理方案可以是:排队页面(将用户导流到排队页面等一会重试)、无货(直接告知用户没货了)、错误页(如活动太火爆了,稍后重试)
什么是服务熔断?和服务降级有什么区别?
熔断机制是应对雪崩效应的一种微服务链路保护机制,当扇出链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回”错误”的响应信息。
和服务降级有什么区别?
服务熔断对服务提供了proxy,防止服务不可能时,出现串联故障(cascading failure),导致雪崩效应。
服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑。
- 共性:
- 目的 -> 都是从可用性、可靠性出发,提高系统的容错能力。
- 最终表现->使某一些应用不可达或不可用,来保证整体系统稳定。
- 粒度 -> 一般都是服务级别,但也有细粒度的层面:如做到数据持久层、只许查询不许增删改等。
- 自治 -> 对其自治性要求很高。都要求具有较高的自动处理机制。
- 区别:
- 触发原因 -> 服务熔断通常是下级服务故障引起;服务降级通常为整体系统而考虑。
- 管理目标 -> 熔断是每个微服务都需要的,是一个框架级的处理;而服务降级一般是关注业务,对业务进行考虑,抓住业务的层级,从而决定在哪一层上进行处理:比如在IO层,业务逻辑层,还是在外围进行处理。
- 实现方式 -> 代码实现中的差异。
如何设计服务的熔断?
异常处理:调用受熔断器保护的服务的时候,我们必须要处理当服务不可用时的异常情况。这些异常处理通常需要视具体的业务情况而定。比如,如果应用程序只是暂时的功能降级,可能需要切换到其它的可替换的服务上来执行相同的任务或者获取相同的数据,或者给用户报告错误然后提示他们稍后重试。
异常的类型:请求失败的原因可能有很多种。一些原因可能会比其它原因更严重。比如,请求会失败可能是由于远程的服务崩溃,这可能需要花费数分钟来恢复;也可能是由于服务器暂时负载过重导致超时。熔断器应该能够检查错误的类型,从而根据具体的错误情况来调整策略。比如,可能需要很多次超时异常才可以断定需要切换到断开状态,而只需要几次错误提示就可以判断服务不可用而快速切换到断开状态。
日志:熔断器应该能够记录所有失败的请求,以及一些可能会尝试成功的请求,使得的管理员能够监控使用熔断器保护的服务的执行情况。 测试服务是否可用:在断开状态下,熔断器可以采用定期的ping远程的服务或者资源,来判断是否服务是否恢复,而不是使用计时器来自动切换到半断开状态。这种ping操作可以模拟之前那些失败的请求,或者可以使用通过调用远程服务提供的检查服务是否可用的方法来判断。
手动重置:在系统中对于失败操作的恢复时间是很难确定的,提供一个手动重置功能能够使得管理员可以手动的强制将熔断器切换到闭合状态。同样的,如果受熔断器保护的服务暂时不可用的话,管理员能够强制的将熔断器设置为断开状态。 并发问题:相同的熔断器有可能被大量并发请求同时访问。熔断器的实现不应该阻塞并发的请求或者增加每次请求调用的负担。 资源的差异性:使用单个熔断器时,一个资源如果有分布在多个地方就需要小心。比如,一个数据可能存储在多个磁盘分区上(shard),某个分区可以正常访问,而另一个可能存在暂时性的问题。在这种情况下,不同的错误响应如果混为一谈,那么应用程序访问的这些存在问题的分区的失败的可能性就会高,而那些被认为是正常的分区,就有可能被阻塞。
加快熔断器的熔断操作:有时候,服务返回的错误信息足够让熔断器立即执行熔断操作并且保持一段时间。比如,如果从一个分布式资源返回的响应提示负载超重,那么应该等待几分钟后再重试。(HTTP协议定义了”HTTP 503 Service Unavailable”来表示请求的服务当前不可用,他可以包含其他信息比如,超时等)
重复失败请求:当熔断器在断开状态的时候,熔断器可以记录每一次请求的细节,而不是仅仅返回失败信息,这样当远程服务恢复的时候,可以将这些失败的请求再重新请求一次。
服务熔断有哪些实现方案?
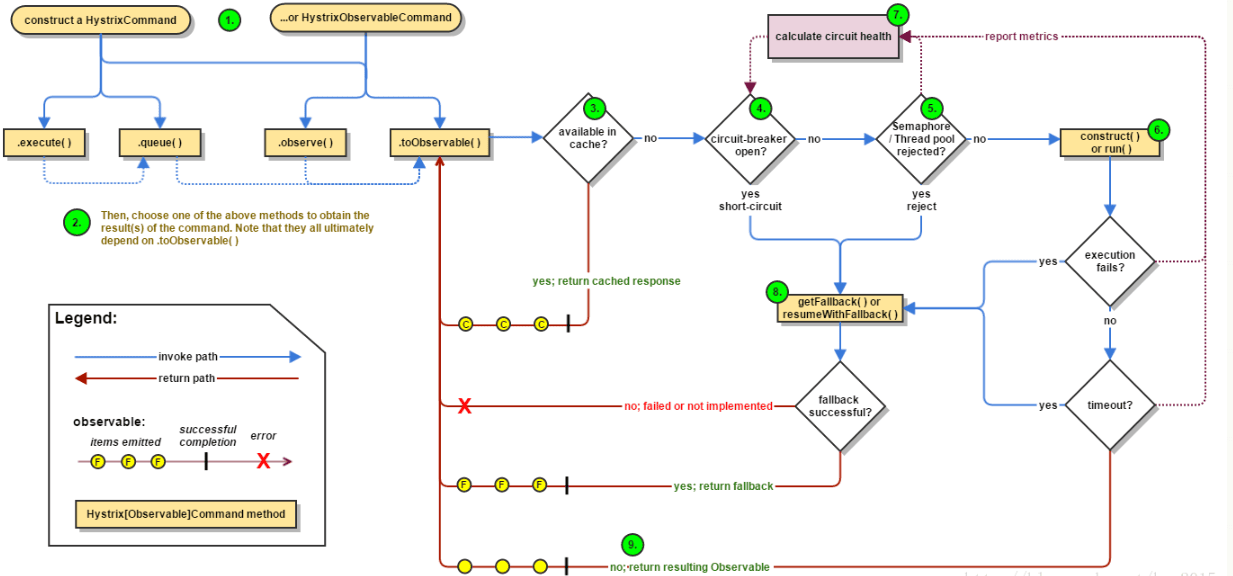
- Hystrix
Spring Cloud Netflix Hystrix就是隔离措施的一种实现,可以设置在某种超时或者失败情形下断开依赖调用或者返回指定逻辑,从而提高分布式系统的稳定性. 流程图如下:
- Sentinel
Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。分为两个部分:
- 核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
- 控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
主要特性:

12.5 负载均衡
什么是负载均衡?原理是什么?
负载均衡(Load Balance),意思是将负载(工作任务,访问请求)进行平衡、分摊到多个操作单元(服务器,组件)上进行执行。是解决高性能,单点故障(高可用),扩展性(水平伸缩)的终极解决方案。
- 负载均衡原理
采用横向扩展的方式,通过添加机器来满足大型网站服务的处理能力。比如:一台机器不能满足,则增加两台或者多台机器,共同承担访问压力。这就是典型的集群和负载均衡架构:如下图:

应用集群:将同一应用部署到多台机器上,组成处理集群,接收负载均衡设备分发的请求,进行处理,并返回相应数据。
负载均衡设备:将用户访问的请求,根据负载均衡算法,分发到集群中的一台处理服务器。(一种把网络请求分散到一个服务器集群中的可用服务器上去的设备)
- 负载均衡的作用(解决的问题):
1.解决并发压力,提高应用处理性能(增加吞吐量,加强网络处理能力);
2.提供故障转移,实现高可用;
3.通过添加或减少服务器数量,提供网站伸缩性(扩展性);
4.安全防护;(负载均衡设备上做一些过滤,黑白名单等处理)
负载均衡有哪些分类?
根据实现技术不同,可分为DNS负载均衡,HTTP负载均衡,IP负载均衡,链路层负载均衡等。
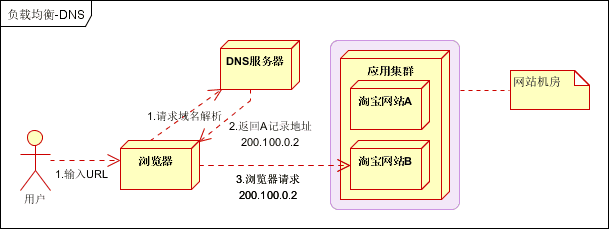
- DNS负载均衡
最早的负载均衡技术,利用域名解析实现负载均衡,在DNS服务器,配置多个A记录,这些A记录对应的服务器构成集群。大型网站总是部分使用DNS解析,作为第一级负载均衡。如下图:
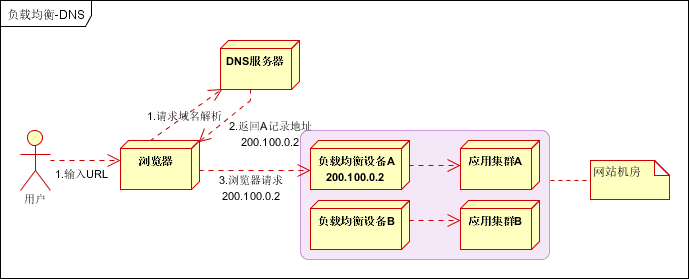
实践建议
将DNS作为第一级负载均衡,A记录对应着内部负载均衡的IP地址,通过内部负载均衡将请求分发到真实的Web服务器上。一般用于互联网公司,复杂的业务系统不合适使用。如下图:
- IP负载均衡
在网络层通过修改请求目标地址进行负载均衡。
用户请求数据包,到达负载均衡服务器后,负载均衡服务器在操作系统内核进程获取网络数据包,根据负载均衡算法得到一台真实服务器地址,然后将请求目的地址修改为,获得的真实ip地址,不需要经过用户进程处理。
真实服务器处理完成后,响应数据包回到负载均衡服务器,负载均衡服务器,再将数据包源地址修改为自身的ip地址,发送给用户浏览器。如下图:

IP负载均衡,真实物理服务器返回给负载均衡服务器,存在两种方式:(1)负载均衡服务器在修改目的ip地址的同时修改源地址。将数据包源地址设为自身盘,即源地址转换(snat)。(2)将负载均衡服务器同时作为真实物理服务器集群的网关服务器。
- 链路层负载均衡
在通信协议的数据链路层修改mac地址,进行负载均衡。
数据分发时,不修改ip地址,指修改目标mac地址,配置真实物理服务器集群所有机器虚拟ip和负载均衡服务器ip地址一致,达到不修改数据包的源地址和目标地址,进行数据分发的目的。
实际处理服务器ip和数据请求目的ip一致,不需要经过负载均衡服务器进行地址转换,可将响应数据包直接返回给用户浏览器,避免负载均衡服务器网卡带宽成为瓶颈。也称为直接路由模式(DR模式)。如下图:
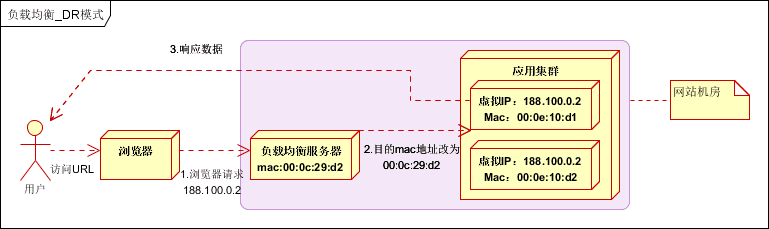
实践建议:DR模式是目前使用最广泛的一种负载均衡方式。
- 混合型负载均衡
由于多个服务器群内硬件设备、各自的规模、提供的服务等的差异,可以考虑给每个服务器群采用最合适的负载均衡方式,然后又在这多个服务器群间再一次负载均衡或群集起来以一个整体向外界提供服务(即把这多个服务器群当做一个新的服务器群),从而达到最佳的性能。将这种方式称之为混合型负载均衡。
此种方式有时也用于单台均衡设备的性能不能满足大量连接请求的情况下。是目前大型互联网公司,普遍使用的方式。
方式一,如下图:

以上模式适合有动静分离的场景,反向代理服务器(集群)可以起到缓存和动态请求分发的作用,当时静态资源缓存在代理服务器时,则直接返回到浏览器。如果动态页面则请求后面的应用负载均衡(应用集群)。
方式二,如下图:
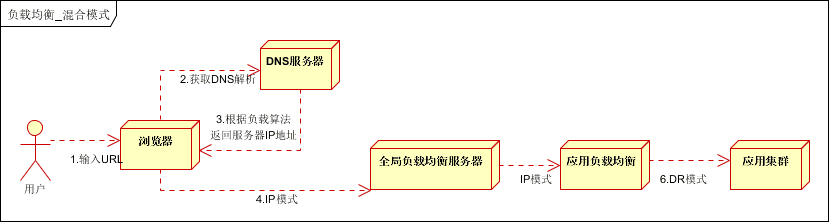
以上模式,适合动态请求场景。
因混合模式,可以根据具体场景,灵活搭配各种方式,以上两种方式仅供参考。
常见的负载均衡服务器有哪些?
平时我们常用的有四层负载均衡和七层负载均衡,四层的负载均衡是基于IP和端口实现的,七层的负载均衡是在四层的基础上,基于URL等信息实现。
- 四层负载均衡
LVS:重量级软件,本身不支持正则表达式,部署起来比较麻烦,但是性能高,应用范围广,一般的大型互联网公司都有用到。
HAProxy:轻量级软件,支持的负载均衡策略非常多,较灵活。
Nginx:轻量级软件,支持的协议少(HTTP、HTTPS和Email协议),对于Session支持不友好。
- 七层负载均衡
HAProxy:全面支持七层代理,灵活性高,支持Session会话保持。
Nginx:可以针对HTTP应用进行分流,正则规则灵活,支持高并发,部署简单。
Apache:性能较差,一般不考虑。
MySQL Proxy:官方的数据库中间件,可以实现读写分离,负载均衡等功能,但是对分表分库支持不完善(可选替代品:Atlas,Cobar,TDDL)。
常见的负载均衡的算法?
常见的负载均衡算法包含:
第一类,轮询法
- 轮询法(Round Robin)
- 将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载。
- 加权轮询法(Weight Round Robin)
- 不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载,加权轮询能很好地处理这一问题,并将请求顺序且按照权重分配到后端。
- 平滑加权轮询法(Smooth Weight Round Robin)
第二类,随机法
- 随机法(Random)
- 通过系统的随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问。由概率统计理论可以得知,随着客户端调用服务端的次数增多, 其实际效果越来越接近于平均分配调用量到后端的每一台服务器,也就是轮询的结果。
- 加权随机法(Weight Random)
- 与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
第三类,哈希
- 源地址哈希法(Hash)
- 源地址哈希的思想是根据获取客户端的IP地址,通过哈希函数计算得到的一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是客服端要访问服务器的序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。
第四类,连接数法
- 最小连接数法(Least Connections)
- 最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,它是根据后端服务器当前的连接情况,动态地选取其中当前积压连接数最少的一台服务器来处理当前的请求,尽可能地提高后端服务的利用效率,将负责合理地分流到每一台服务器。
12.6 灾备和故障转移
什么是容灾?一般基于什么实现?
容灾是指为了保证关键业务和应用在经历各种灾难后,仍然能够最大限度的提供正常服务的所进行的一系列系统计划及建设和管理行为。
容灾能力基于数据复制和故障转移。
一般怎么实现灾备?
备份是对数据进行保护,容灾是在备份的基础上,保障企业的业务连续性,从这个层面,一般将容灾划分为数据容灾和应用容灾。
- 数据容灾是指建立一个异地的数据系统,该系统是本地关键应用数据的一个实时复制。
- 应用容灾是指在数据容灾的基础上,在异地建立一套完整的与本地生产系统相当的备份应用系统,在灾难发生时,备端系统迅速接管业务继续运行。
13 分布式
分布式相关。
13.1 一致性算法
什么是分布式系统的副本一致性?有哪些?
分布式系统通过副本控制协议,使得从系统外部读取系统内部各个副本的数据在一定的约束条件下相同,称之为副本一致性(consistency)。副本一致性是针对分布式系统而言的,不是针对某一个副本而言。
强一致性(strong consistency):任何时刻任何用户或节点都可以读到最近一次成功更新的副本数据。强一致性是程度最高的一致性要求,也是实践中最难以实现的一致性。
单调一致性(monotonic consistency):任何时刻,任何用户一旦读到某个数据在某次更新后的值,这个用户不会再读到比这个值更旧的值。单调一致性是弱于强一致性却非常实用的一种一致性级别。因为通常来说,用户只关心从己方视角观察到的一致性,而不会关注其他用户的一致性情况。
会话一致性(session consistency):任何用户在某一次会话内一旦读到某个数据在某次更新后的值,这个用户在这次会话过程中不会再读到比这个值更旧的值。会话一致性通过引入会话的概念,在单调一致性的基础上进一步放松约束,会话一致性只保证单个用户单次会话内数据的单调修改,对于不同用户间的一致性和同一用户不同会话间的一致性没有保障。实践中有许多机制正好对应会话的概念,例如php 中的session 概念。
最终一致性(eventual consistency):最终一致性要求一旦更新成功,各个副本上的数据最终将达 到完全一致的状态,但达到完全一致状态所需要的时间不能保障。对于最终一致性系统而言,一个用户只要始终读取某一个副本的数据,则可以实现类似单调一致性的效果,但一旦用户更换读取的副本,则无法保障任何一致性。
弱一致性(week consistency):一旦某个更新成功,用户无法在一个确定时间内读到这次更新的值,且即使在某个副本上读到了新的值,也不能保证在其他副本上可以读到新的值。弱一致性系统一般很难在实际中使用,使用弱一致性系统需要应用方做更多的工作从而使得系统可用。
在分布式系统中有哪些常见的一致性算法?
- 分布式算法 - 一致性Hash算法
- 一致性Hash算法是个经典算法,Hash环的引入是为解决
单调性(Monotonicity)的问题;虚拟节点的引入是为了解决平衡性(Balance)问题
- 一致性Hash算法是个经典算法,Hash环的引入是为解决
- 分布式算法 - Paxos算法
- Paxos算法是Lamport宗师提出的一种基于消息传递的分布式一致性算法,使其获得2013年图灵奖。自Paxos问世以来就持续垄断了分布式一致性算法,Paxos这个名词几乎等同于分布式一致性, 很多分布式一致性算法都由Paxos演变而来
- 分布式算法 - Raft算法
- Paxos是出了名的难懂,而Raft正是为了探索一种更易于理解的一致性算法而产生的。它的首要设计目的就是易于理解,所以在选主的冲突处理等方式上它都选择了非常简单明了的解决方案
- 分布式算法 - ZAB算法
- ZAB 协议全称:Zookeeper Atomic Broadcast(Zookeeper 原子广播协议), 它应该是所有一致性协议中生产环境中应用最多的了。为什么呢?因为他是为 Zookeeper 设计的分布式一致性协议!
谈谈你对一致性hash算法的理解?
判定哈希算法好坏的四个定义:
平衡性(Balance): 平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。单调性(Monotonicity): 单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。分散性(Spread): 在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。负载(Load): 负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
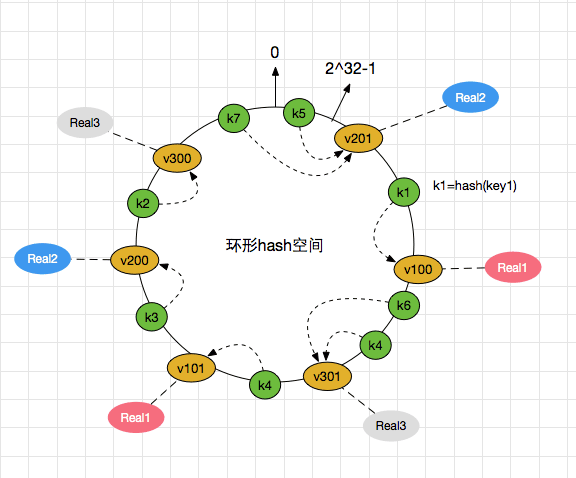
什么是Paxos算法? 如何实现的?
Paxos算法是Lamport宗师提出的一种基于消息传递的分布式一致性算法,使其获得2013年图灵奖。
- 三个角色? 可以理解为人大代表(Proposer)在人大向其它代表(Acceptors)提案,通过后让老百姓(Learner)落实
Paxos将系统中的角色分为提议者 (Proposer),决策者 (Acceptor),和最终决策学习者 (Learner):
Proposer: 提出提案 (Proposal)。Proposal信息包括提案编号 (Proposal ID) 和提议的值 (Value)。Acceptor: 参与决策,回应Proposers的提案。收到Proposal后可以接受提案,若Proposal获得多数Acceptors的接受,则称该Proposal被批准。Learner: 不参与决策,从Proposers/Acceptors学习最新达成一致的提案(Value)。
在多副本状态机中,每个副本同时具有Proposer、Acceptor、Learner三种角色。
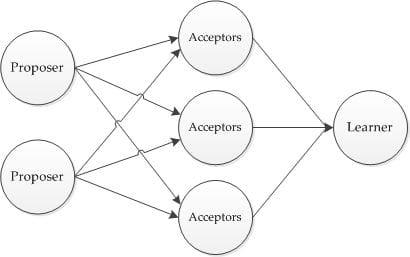
- 基于消息传递的3个阶段
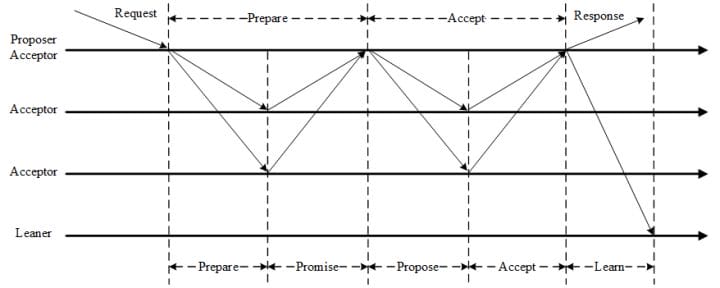
- 第一阶段: Prepare阶段;Proposer向Acceptors发出Prepare请求,Acceptors针对收到的Prepare请求进行Promise承诺。
Prepare: Proposer生成全局唯一且递增的Proposal ID (可使用时间戳加Server ID),向所有Acceptors发送Prepare请求,这里无需携带提案内容,只携带Proposal ID即可。Promise: Acceptors收到Prepare请求后,做出“两个承诺,一个应答”。- 承诺1: 不再接受Proposal ID小于等于(注意: 这里是<= )当前请求的Prepare请求;
- 承诺2: 不再接受Proposal ID小于(注意: 这里是< )当前请求的Propose请求;
- 应答: 不违背以前作出的承诺下,回复已经Accept过的提案中Proposal ID最大的那个提案的Value和Proposal ID,没有则返回空值。
- 第二阶段: Accept阶段; Proposer收到多数Acceptors承诺的Promise后,向Acceptors发出Propose请求,Acceptors针对收到的Propose请求进行Accept处理。
Propose: Proposer 收到多数Acceptors的Promise应答后,从应答中选择Proposal ID最大的提案的Value,作为本次要发起的提案。如果所有应答的提案Value均为空值,则可以自己随意决定提案Value。然后携带当前Proposal ID,向所有Acceptors发送Propose请求。Accept: Acceptor收到Propose请求后,在不违背自己之前作出的承诺下,接受并持久化当前Proposal ID和提案Value。
- 第三阶段: Learn阶段; Proposer在收到多数Acceptors的Accept之后,标志着本次Accept成功,决议形成,将形成的决议发送给所有Learners。
什么是Raft算法?
不同于Paxos算法直接从分布式一致性问题出发推导出来,Raft算法则是从多副本状态机的角度提出。Raft实现了和Paxos相同的功能,它将一致性分解为多个子问题: Leader选举(Leader election)、日志同步(Log replication)、安全性(Safety)、日志压缩(Log compaction)、成员变更(Membership change)等。同时,Raft算法使用了更强的假设来减少了需要考虑的状态,使之变的易于理解和实现。
- 三个角色
Raft将系统中的角色分为领导者(Leader)、跟从者(Follower)和候选人(Candidate):
Leader: 接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后告诉Follower提交日志。Follower: 接受并持久化Leader同步的日志,在Leader告之日志可以提交之后,提交日志。Candidate: Leader选举过程中的临时角色。
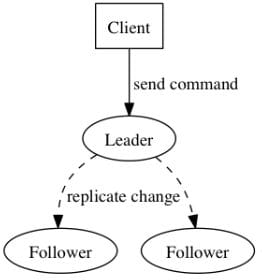
Raft要求系统在任意时刻最多只有一个Leader,正常工作期间只有Leader和Followers。
- 以子问题Leader选举为例?
Raft 使用心跳(heartbeat)触发Leader选举。当服务器启动时,初始化为Follower。Leader向所有Followers周期性发送heartbeat。如果Follower在选举超时时间内没有收到Leader的heartbeat,就会等待一段随机的时间后发起一次Leader选举。
Follower将其当前term加一然后转换为Candidate。它首先给自己投票并且给集群中的其他服务器发送 RequestVote RPC (RPC细节参见八、Raft算法总结)。结果有以下三种情况:
- 赢得了多数的选票,成功选举为Leader;
- 收到了Leader的消息,表示有其它服务器已经抢先当选了Leader;
- 没有服务器赢得多数的选票,Leader选举失败,等待选举时间超时后发起下一次选举。

选举出Leader后,Leader通过定期向所有Followers发送心跳信息维持其统治。若Follower一段时间未收到Leader的心跳则认为Leader可能已经挂了,再次发起Leader选举过程。
13.2 全局唯一ID
全局唯一ID有哪些实现方案?
常见的分布式ID生成方式,大致分类的话可以分为两类:
- 一种是类DB型的,根据设置不同起始值和步长来实现趋势递增,需要考虑服务的容错性和可用性;
- 另一种是类snowflake型,这种就是将64位划分为不同的段,每段代表不同的涵义,基本就是时间戳、机器ID和序列数。这种方案就是需要考虑时钟回拨的问题以及做一些 buffer的缓冲设计提高性能。
数据库方式实现方案?有什么缺陷?
- MySQL为例
我们将分布式系统中数据库的同一个业务表的自增ID设计成不一样的起始值,然后设置固定的步长,步长的值即为分库的数量或分表的数量。
以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增。
auto_increment_offset:表示自增长字段从那个数开始,他的取值范围是1 .. 65535。auto_increment_increment:表示自增长字段每次递增的量,其默认值是1,取值范围是1 .. 65535。
缺点也很明显,首先它强依赖DB,当DB异常时整个系统不可用。虽然配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。还有就是ID发号性能瓶颈限制在单台MySQL的读写性能。
- 使用redis实现
Redis实现分布式唯一ID主要是通过提供像 INCR 和 INCRBY 这样的自增原子命令,由于Redis自身的单线程的特点所以能保证生成的 ID 肯定是唯一有序的。
但是单机存在性能瓶颈,无法满足高并发的业务需求,所以可以采用集群的方式来实现。集群的方式又会涉及到和数据库集群同样的问题,所以也需要设置分段和步长来实现。
为了避免长期自增后数字过大可以通过与当前时间戳组合起来使用,另外为了保证并发和业务多线程的问题可以采用 Redis + Lua的方式进行编码,保证安全。
Redis 实现分布式全局唯一ID,它的性能比较高,生成的数据是有序的,对排序业务有利,但是同样它依赖于redis,需要系统引进redis组件,增加了系统的配置复杂性。
当然现在Redis的使用性很普遍,所以如果其他业务已经引进了Redis集群,则可以资源利用考虑使用Redis来实现。
雪花算法如何实现的?
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割成多个部分,每个部分代表不同的含义。而 Java中64bit的整数是Long类型,所以在 Java 中 SnowFlake 算法生成的 ID 就是 long 来存储的。
- 第1位占用1bit,其值始终是0,可看做是符号位不使用。
- 第2位开始的41位是时间戳,41-bit位可表示2^41个数,每个数代表毫秒,那么雪花算法可用的时间年限是
(1L<<41)/(1000L360024*365)=69 年的时间。 - 中间的10-bit位可表示机器数,即2^10 = 1024台机器,但是一般情况下我们不会部署这么台机器。如果我们对IDC(互联网数据中心)有需求,还可以将 10-bit 分 5-bit 给 IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,具体的划分可以根据自身需求定义。
- 最后12-bit位是自增序列,可表示2^12 = 4096个数。
这样的划分之后相当于在一毫秒一个数据中心的一台机器上可产生4096个有序的不重复的ID。但是我们 IDC 和机器数肯定不止一个,所以毫秒内能生成的有序ID数是翻倍的。

雪花算法有什么问题?有哪些解决思路?
- 有哪些问题?
- 时钟回拨问题;
- 趋势递增,而不是绝对递增;
- 不能在一台服务器上部署多个分布式ID服务;
- 如何解决时钟回拨?
以百度的UidGenerator为例,CachedUidGenerator方式主要通过采取如下一些措施和方案规避了时钟回拨问题和增强唯一性:
自增列:UidGenerator的workerId在实例每次重启时初始化,且就是数据库的自增ID,从而完美的实现每个实例获取到的workerId不会有任何冲突。
RingBuffer:UidGenerator不再在每次取ID时都实时计算分布式ID,而是利用RingBuffer数据结构预先生成若干个分布式ID并保存。
时间递增:传统的雪花算法实现都是通过System.currentTimeMillis()来获取时间并与上一次时间进行比较,这样的实现严重依赖服务器的时间。而UidGenerator的时间类型是AtomicLong,且通过incrementAndGet()方法获取下一次的时间,从而脱离了对服务器时间的依赖,也就不会有时钟回拨的问题
(这种做法也有一个小问题,即分布式ID中的时间信息可能并不是这个ID真正产生的时间点,例如:获取的某分布式ID的值为3200169789968523265,它的反解析结果为{"timestamp":"2019-05-02 23:26:39","workerId":"21","sequence":"1"},但是这个ID可能并不是在"2019-05-02 23:26:39"这个时间产生的)。
13.3 分布式锁
有哪些方案实现分布式锁?
综合讲讲方案:
- 使用场景
- 需要保证一个方法在同一时间内只能被同一个线程执行
- 实现方式:
- 加锁和解锁
- 方案,考虑因素(性能,稳定,实现难度,死锁)
- 基于数据库做分布式锁--乐观锁(基于版本号)和悲观锁(基于排它锁)
- 基于 redis 做分布式锁:setnx(key,当前时间+过期时间)和Redlock机制
- 基于 zookeeper 做分布式锁:临时有序节点来实现的分布式锁,Curator
- 基于 Consul 做分布式锁
基于数据库如何实现分布式锁?有什么缺陷?
- 基于数据库表(锁表,很少使用)
最简单的方式可能就是直接创建一张锁表,然后通过操作该表中的数据来实现了。当我们想要获得锁的时候,就可以在该表中增加一条记录,想要释放锁的时候就删除这条记录。
为了更好的演示,我们先创建一张数据库表,参考如下:
CREATE TABLE database_lock (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`resource` int NOT NULL COMMENT '锁定的资源',
`description` varchar(1024) NOT NULL DEFAULT "" COMMENT '描述',
PRIMARY KEY (id),
UNIQUE KEY uiq_idx_resource (resource)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='数据库分布式锁表';
当我们想要获得锁时,可以插入一条数据:
INSERT INTO database_lock(resource, description) VALUES (1, 'lock');
当需要释放锁的时,可以删除这条数据:
DELETE FROM database_lock WHERE resource=1;
- 基于悲观锁
悲观锁实现思路?
- 在对任意记录进行修改前,先尝试为该记录加上排他锁(exclusive locking)。
- 如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。 具体响应方式由开发者根据实际需要决定。
- 如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
- 其间如果有其他对该记录做修改或加排他锁的操作,都会等待我们解锁或直接抛出异常。
以MySQL InnoDB中使用悲观锁为例?
要使用悲观锁,我们必须关闭mysql数据库的自动提交属性,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。set autocommit=0;
//0.开始事务
begin;/begin work;/start transaction; (三者选一就可以)
//1.查询出商品信息
select status from t_goods where id=1 for update;
//2.根据商品信息生成订单
insert into t_orders (id,goods_id) values (null,1);
//3.修改商品status为2
update t_goods set status=2;
//4.提交事务
commit;/commit work;
上面的查询语句中,我们使用了select…for update的方式,这样就通过开启排他锁的方式实现了悲观锁。此时在t_goods表中,id为1的 那条数据就被我们锁定了,其它的事务必须等本次事务提交之后才能执行。这样我们可以保证当前的数据不会被其它事务修改。
上面我们提到,使用select…for update会把数据给锁住,不过我们需要注意一些锁的级别,MySQL InnoDB默认行级锁。行级锁都是基于索引的,如果一条SQL语句用不到索引是不会使用行级锁的,会使用表级锁把整张表锁住,这点需要注意。
- 基于乐观锁
乐观并发控制(又名“乐观锁”,Optimistic Concurrency Control,缩写“OCC”)是一种并发控制的方法。它假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚。
以使用版本号实现乐观锁为例?
使用版本号时,可以在数据初始化时指定一个版本号,每次对数据的更新操作都对版本号执行+1操作。并判断当前版本号是不是该数据的最新的版本号。
1.查询出商品信息
select (status,status,version) from t_goods where id=#{id}
2.根据商品信息生成订单
3.修改商品status为2
update t_goods
set status=2,version=version+1
where id=#{id} and version=#{version};
需要注意的是,乐观锁机制往往基于系统中数据存储逻辑,因此也具备一定的局限性。由于乐观锁机制是在我们的系统中实现的,对于来自外部系统的用户数据更新操作不受我们系统的控制,因此可能会造成脏数据被更新到数据库中。在系统设计阶段,我们应该充分考虑到这些情况,并进行相应的调整(如将乐观锁策略在数据库存储过程中实现,对外只开放基于此存储过程的数据更新途径,而不是将数据库表直接对外公开)。
- 缺陷
对数据库依赖,开销问题,行锁变表锁问题,无法解决数据库单点和可重入的问题。
基于redis如何实现分布式锁?有什么缺陷?
- 最基本的Jedis方案
加锁: set NX PX + 重试 + 重试间隔
向Redis发起如下命令: SET productId:lock 0xx9p03001 NX PX 30000 其中,"productId"由自己定义,可以是与本次业务有关的id,"0xx9p03001"是一串随机值,必须保证全局唯一(原因在后文中会提到),“NX"指的是当且仅当key(也就是案例中的"productId:lock”)在Redis中不存在时,返回执行成功,否则执行失败。"PX 30000"指的是在30秒后,key将被自动删除。执行命令后返回成功,表明服务成功的获得了锁。
@Override
public boolean lock(String key, long expire, int retryTimes, long retryDuration) {
// use JedisCommands instead of setIfAbsense
boolean result = setRedis(key, expire);
// retry if needed
while ((!result) && retryTimes-- > 0) {
try {
log.debug("lock failed, retrying..." + retryTimes);
Thread.sleep(retryDuration);
} catch (Exception e) {
return false;
}
// use JedisCommands instead of setIfAbsense
result = setRedis(key, expire);
}
return result;
}
private boolean setRedis(String key, long expire) {
try {
RedisCallback<String> redisCallback = connection -> {
JedisCommands commands = (JedisCommands) connection.getNativeConnection();
String uuid = SnowIDUtil.uniqueStr();
lockFlag.set(uuid);
return commands.set(key, uuid, NX, PX, expire); // 看这里
};
String result = redisTemplate.execute(redisCallback);
return !StringUtil.isEmpty(result);
} catch (Exception e) {
log.error("set redis occurred an exception", e);
}
return false;
}
解锁: 采用lua脚本: 在删除key之前,一定要判断服务A持有的value与Redis内存储的value是否一致。如果贸然使用服务A持有的key来删除锁,则会误将服务B的锁释放掉。
if redis.call("get", KEYS[1])==ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
- 基于RedLock实现分布式锁
假设有两个服务A、B都希望获得锁,有一个包含了5个redis master的Redis Cluster,执行过程大致如下:
- 客户端获取当前时间戳,单位: 毫秒
- 服务A轮寻每个master节点,尝试创建锁。(这里锁的过期时间比较短,一般就几十毫秒) RedLock算法会尝试在大多数节点上分别创建锁,假如节点总数为n,那么大多数节点指的是n/2+1。
- 客户端计算成功建立完锁的时间,如果建锁时间小于超时时间,就可以判定锁创建成功。如果锁创建失败,则依次(遍历master节点)删除锁。
- 只要有其它服务创建过分布式锁,那么当前服务就必须轮寻尝试获取锁。
- 基于Redisson实现分布式锁?
过程?
- 线程去获取锁,获取成功: 执行lua脚本,保存数据到redis数据库。
- 线程去获取锁,获取失败: 订阅了解锁消息,然后再尝试获取锁,获取成功后,执行lua脚本,保存数据到redis数据库。
互斥?
如果这个时候客户端B来尝试加锁,执行了同样的一段lua脚本。第一个if判断会执行“exists myLock”,发现myLock这个锁key已经存在。接着第二个if判断,判断myLock锁key的hash数据结构中,是否包含客户端B的ID,但明显没有,那么客户端B会获取到pttl myLock返回的一个数字,代表myLock这个锁key的剩余生存时间。此时客户端B会进入一个while循环,不听的尝试加锁。
watch dog自动延时机制?
客户端A加锁的锁key默认生存时间只有30秒,如果超过了30秒,客户端A还想一直持有这把锁,怎么办?其实只要客户端A一旦加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果客户端A还持有锁key,那么就会不断的延长锁key的生存时间。
可重入?
每次lock会调用incrby,每次unlock会减一。
- 方案比较
- 借助Redis实现分布式锁时,有一个共同的缺陷: 当获取锁被决绝后,需要不断的循环,重新发送获取锁(创建key)的请求,直到请求成功。这就造成空转,浪费宝贵的CPU资源。
- RedLock算法本身有争议,并不能保证健壮性。
- Redisson实现分布式锁时,除了将key新增到某个指定的master节点外,还需要由master自动异步的将key和value等数据同步至绑定的slave节点上。那么问题来了,如果master没来得及同步数据,突然发生宕机,那么通过故障转移和主备切换,slave节点被迅速升级为master节点,新的客户端加锁成功,旧的客户端的watch dog发现key存在,误以为旧客户端仍然持有这把锁,这就导致同时存在多个客户端持有同名锁的问题了。
基于zookeeper如何实现分布式锁?
说几个核心点:
- 顺序节点
创建一个用于发号的节点“/test/lock”,然后以它为父亲节点的前缀为“/test/lock/seq-”依次发号:
- 获得最小号得锁
由于序号的递增性,可以规定排号最小的那个获得锁。所以,每个线程在尝试占用锁之前,首先判断自己是排号是不是当前最小,如果是,则获取锁。
- 节点监听机制
每个线程抢占锁之前,先抢号创建自己的ZNode。同样,释放锁的时候,就需要删除抢号的Znode。抢号成功后,如果不是排号最小的节点,就处于等待通知的状态。等谁的通知呢?不需要其他人,只需要等前一个Znode 的通知就可以了。当前一个Znode 删除的时候,就是轮到了自己占有锁的时候。第一个通知第二个、第二个通知第三个,击鼓传花似的依次向后。
13.4 分布式事务
什么是ACID?
一个事务有四个基本特性,也就是我们常说的(ACID):
- Atomicity(原子性):事务是一个不可分割的整体,事务内所有操作要么全做成功,要么全失败。
- Consistency(一致性):事务执行前后,数据从一个状态到另一个状态必须是一致的(A向B转账,不能出现A扣了钱,B却没收到)。
- Isolation(隔离性): 多个并发事务之间相互隔离,不能互相干扰。
- Durability(持久性):事务完成后,对数据库的更改是永久保存的,不能回滚。
分布式事务有哪些解决方案?
什么是分布式的XA协议?
XA协议是一个基于数据库的分布式事务协议,其分为两部分:事务管理器和本地资源管理器。事务管理器作为一个全局的调度者,负责对各个本地资源管理器统一号令提交或者回滚。二阶提交协议(2PC)和三阶提交协议(3PC)就是根据此协议衍生出来而来。主流的诸如Oracle、MySQL等数据库均已实现了XA接口。
XA接口是双向的系统接口,在事务管理器(Transaction Manager)以及一个或多个资源管理器(Resource Manager)之间形成通信桥梁。也就是说,在基于XA的一个事务中,我们可以针对多个资源进行事务管理,例如一个系统访问多个数据库,或即访问数据库、又访问像消息中间件这样的资源。这样我们就能够实现在多个数据库和消息中间件直接实现全部提交、或全部取消的事务。XA规范不是java的规范,而是一种通用的规范。
什么是2PC?
两段提交顾名思义就是要进行两个阶段的提交:
- 第一阶段,准备阶段(投票阶段);
- 第二阶段,提交阶段(执行阶段)。
![]()
下面还拿下单扣库存举例子,简单描述一下两段提交(2PC)的原理:
之前说过业务服务化(SOA)以后,一个下单流程就会用到多个服务,各个服务都无法保证调用的其他服务的成功与否,这个时候就需要一个全局的角色(协调者)对各个服务(参与者)进行协调。
![]()
一个下单请求过来通过协调者,给每一个参与者发送Prepare消息,执行本地数据脚本但不提交事务。
如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中被占用的资源,显然2PC做到了所有操作要么全部成功、要么全部失败。
两段提交(2PC)的缺点:
二阶段提交看似能够提供原子性的操作,但它存在着严重的缺陷:
- 网络抖动导致的数据不一致:第二阶段中协调者向参与者发送commit命令之后,一旦此时发生网络抖动,导致一部分参与者接收到了commit请求并执行,可其他未接到commit请求的参与者无法执行事务提交。进而导致整个分布式系统出现了数据不一致。
- 超时导致的同步阻塞问题:2PC中的所有的参与者节点都为事务阻塞型,当某一个参与者节点出现通信超时,其余参与者都会被动阻塞占用资源不能释放。
- 单点故障的风险:由于严重的依赖协调者,一旦协调者发生故障,而此时参与者还都处于锁定资源的状态,无法完成事务commit操作。虽然协调者出现故障后,会重新选举一个协调者,可无法解决因前一个协调者宕机导致的参与者处于阻塞状态的问题。
什么是3PC?
三段提交(3PC)是对两段提交(2PC)的一种升级优化,3PC在2PC的第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前,各参与者节点的状态都一致。同时在协调者和参与者中都引入超时机制,当参与者各种原因未收到协调者的commit请求后,会对本地事务进行commit,不会一直阻塞等待,解决了2PC的单点故障问题,但3PC还是没能从根本上解决数据一致性的问题。
![]()
3PC的三个阶段分别是CanCommit、PreCommit、DoCommit:
- CanCommit:协调者向所有参与者发送CanCommit命令,询问是否可以执行事务提交操作。如果全部响应YES则进入下一个阶段。
- PreCommit:协调者向所有参与者发送PreCommit命令,询问是否可以进行事务的预提交操作,参与者接收到PreCommit请求后,如参与者成功的执行了事务操作,则返回Yes响应,进入最终commit阶段。一旦参与者中有向协调者发送了No响应,或因网络造成超时,协调者没有接到参与者的响应,协调者向所有参与者发送abort请求,参与者接受abort命令执行事务的中断。
- DoCommit:在前两个阶段中所有参与者的响应反馈均是YES后,协调者向参与者发送DoCommit命令正式提交事务,如协调者没有接收到参与者发送的ACK响应,会向所有参与者发送abort请求命令,执行事务的中断。
什么是TCC?
TCC(Try-Confirm-Cancel)又被称补偿事务,TCC与2PC的思想很相似,事务处理流程也很相似,但2PC是应用于在DB层面,TCC则可以理解为在应用层面的2PC,是需要我们编写业务逻辑来实现。
TCC它的核心思想是:"针对每个操作都要注册一个与其对应的确认(Try)和补偿(Cancel)"。
还拿下单扣库存解释下它的三个操作:
- Try阶段:下单时通过Try操作去扣除库存预留资源。
- Confirm阶段:确认执行业务操作,在只预留的资源基础上,发起购买请求。
- Cancel阶段:只要涉及到的相关业务中,有一个业务方预留资源未成功,则取消所有业务资源的预留请求。
![]()
TCC的缺点:
- 应用侵入性强:TCC由于基于在业务层面,至使每个操作都需要有try、confirm、cancel三个接口。
- 开发难度大:代码开发量很大,要保证数据一致性confirm和cancel接口还必须实现幂等性。
什么是SAGA方案?
13.5 分布式缓存
分布式系统中常用的缓存方案有哪些?
- 客户端缓存:页面和浏览器缓存,APP缓存,H5缓存,localStorage和sessionStorage
- CDN缓存:
- 内存存储:数据的缓存
- 内容分发:负载均衡
- nginx缓存:本地缓存,外部缓存
- 数据库缓存:持久层缓存(mybatis,hibernate多级缓存),Mysql查询缓存
- 操作系统缓存:Page Cache,Buffer Cache
分布式系统缓存的更新模式?
- Cache Aside模式
- 读取失效:cache数据没有命中,查询DB,成功后把数据写入缓存
- 读取命中:读取cache数据
- 更新:把数据更新到DB,失效缓存
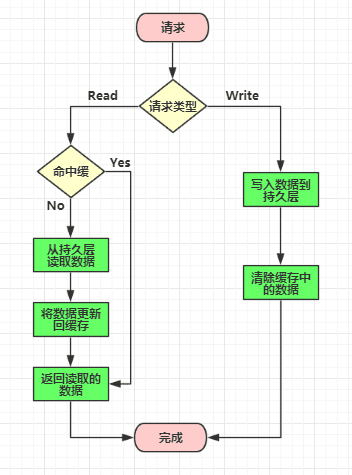
// Read
data = cache.get(id);
if (data == null) {
data = db.get(id);
cache.put(id, data);
}
// Write
db.save(data);
cache.invalid(data.id);
- Read/Write Through模式
缓存代理了DB读取、写入的逻辑,可以把缓存看成唯一的存储。
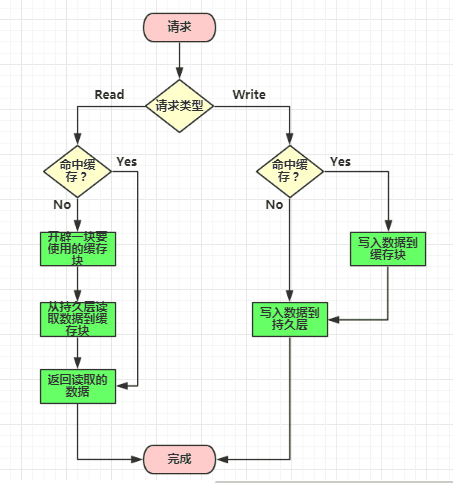
- Write Back模式
这种模式下所有的操作都走缓存,缓存里的数据再通过异步的方式同步到数据库里面。所以系统的写性能能够大大提升了。

分布式系统缓存淘汰策略
缓存淘汰,又称为缓存逐出(cache replacement algorithms或者cache replacement policies),是指在存储空间不足的情况下,缓存系统主动释放一些缓存对象获取更多的存储空间。一般LRU用的比较多,可以重点了解一下。
- FIFO 先进先出(First In First Out)是一种简单的淘汰策略,缓存对象以队列的形式存在,如果空间不足,就释放队列头部的(先缓存)对象。一般用链表实现。
- LRU 最近最久未使用(Least Recently Used),这种策略是根据访问的时间先后来进行淘汰的,如果空间不足,会释放最久没有访问的对象(上次访问时间最早的对象)。比较常见的是通过优先队列来实现。
- LFU 最近最少使用(Least Frequently Used),这种策略根据最近访问的频率来进行淘汰,如果空间不足,会释放最近访问频率最低的对象。这个算法也是用优先队列实现的比较常见。
更进一步的谈谈Redis缓存淘汰的8个模式,可以参考上文Redis问答部分。
13.6 分布式任务
Java中定时任务是有些?如何演化的?
这里主要讲讲Java的定时任务是如何一步步发展而来的:
- Timer
new Timer("testTimer").schedule(new TimerTask() {
@Override
public void run() {
System.out.println("TimerTask");
}
}, 1000,2000);
解释:1000ms是延迟启动时间,2000ms是定时任务周期,每2s执行一次
- ScheduledExecutorService
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(10);
scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
System.out.println("ScheduledTask");
}
}, 1, 1, TimeUnit.SECONDS);
解释:延迟1s启动,每隔1s执行一次,是前一个任务开始时就开始计算时间间隔,但是会等上一个任务结束在开始下一个
- SpringTask
@Service
public class SpringTask {
private static final Logger log = LoggerFactory.getLogger(SpringTask.class);
@Scheduled(cron = "1/5 * * * * *")
public void task1(){
log.info("springtask 定时任务!");
}
@Scheduled(initialDelay = 1000,fixedRate = 1*1000)
public void task2(){
log.info("springtask 定时任务!");
}
}
解释:
- task1是每隔5s执行一次,{秒} {分} {时} {日期}
- task2是延迟1s,每隔1S执行一次
- Quartz
quartz 是一个开源的分布式调度库,它基于java实现。
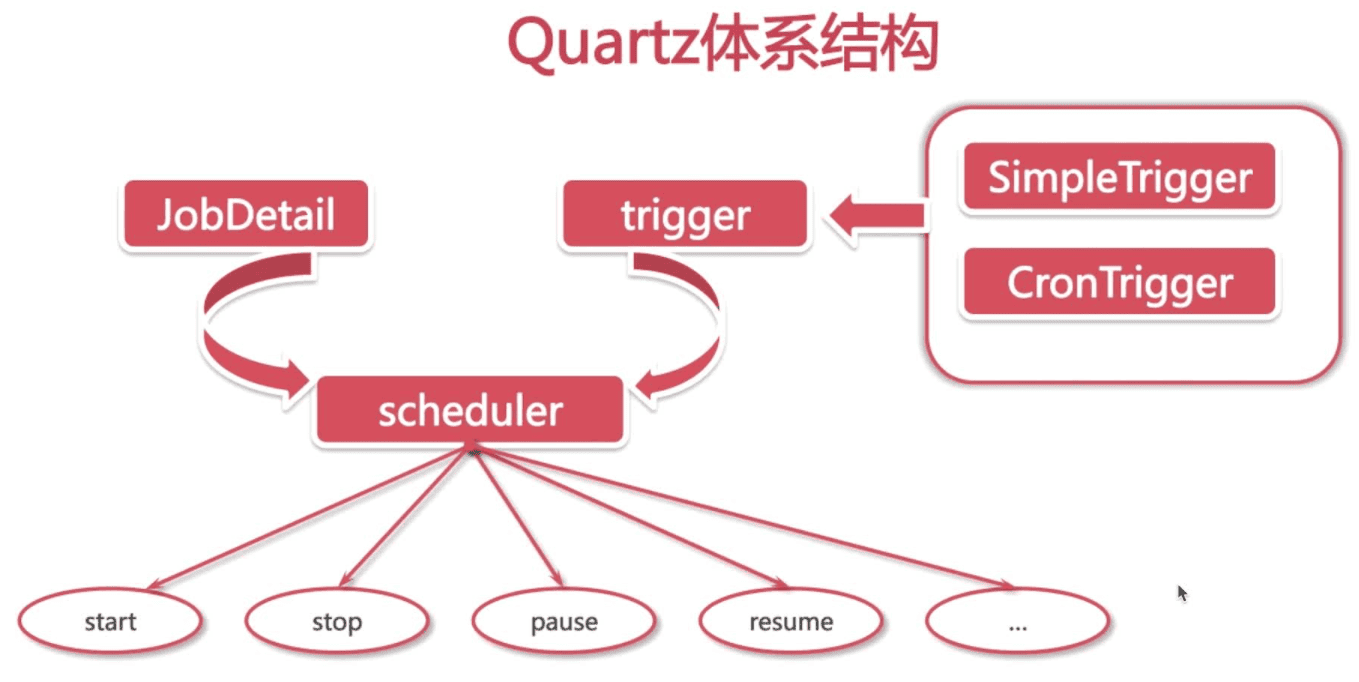
- Job 表示一个任务,要执行的具体内容。
- JobDetail 表示一个具体的可执行的调度程序,Job 是这个可执行程调度程序所要执行的内容,另外 JobDetail 还包含了这个任务调度的方案和策略。
- Trigger 代表一个调度参数的配置,什么时候去调。
- Scheduler 代表一个调度容器,一个调度容器中可以注册多个 JobDetail 和 Trigger。当 Trigger 与 JobDetail 组合,就可以被 Scheduler 容器调度了。
//创建调度器Schedule
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
//创建JobDetail实例,并与HelloWordlJob类绑定
JobDetail jobDetail = JobBuilder.newJob(HelloWorldJob.class).withIdentity("job1", "jobGroup1")
.build();
//创建触发器Trigger实例(立即执行,每隔1S执行一次)
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1", "triggerGroup1")
.startNow()
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1).repeatForever())
.build();
//开始执行
scheduler.scheduleJob(jobDetail, trigger);
scheduler.start();
常见的JOB实现方案?
基于上面Java任务演化出分布式Job方案:
- quartz
JDBCJobStore 支持集群所有触发器和job都存储在数据库中无论服务器停止和重启都可以恢复任务同时支持事务处理。

- elastic-job
elastic-job 是由当当网基于quartz 二次开发之后的分布式调度解决方案 , 由两个相对独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成 。
Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供分布式任务的协调服务。
Elastic-Job-Cloud使用Mesos + Docker(TBD)的解决方案,额外提供资源治理、应用分发以及进程隔离等服务
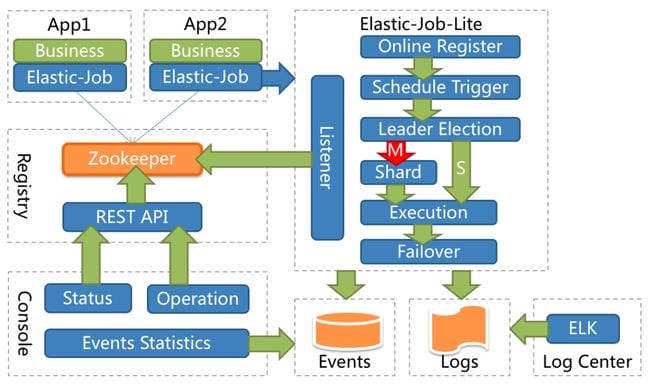
亮点:
- 基于quartz 定时任务框架为基础的,因此具备quartz的大部分功能
- 使用zookeeper做协调,调度中心,更加轻量级
- 支持任务的分片
- 支持弹性扩容 , 可以水平扩展 , 当任务再次运行时,会检查当前的服务器数量,重新分片,分片结束之后才会继续执行任务
- 失效转移,容错处理,当一台调度服务器宕机或者跟zookeeper断开连接之后,会立即停止作业,然后再去寻找其他空闲的调度服务器,来运行剩余的任务
- 提供运维界面,可以管理作业和注册中心。
- xxl-job
个轻量级分布式任务调度框架 ,主要分为 调度中心和执行器两部分 , 调度中心在启动初始化的时候,会默认生成执行器的RPC代理
对象(http协议调用), 执行器项目启动之后, 调度中心在触发定时器之后通过jobHandle 来调用执行器项目里面的代码,核心功能和elastic-job差不多
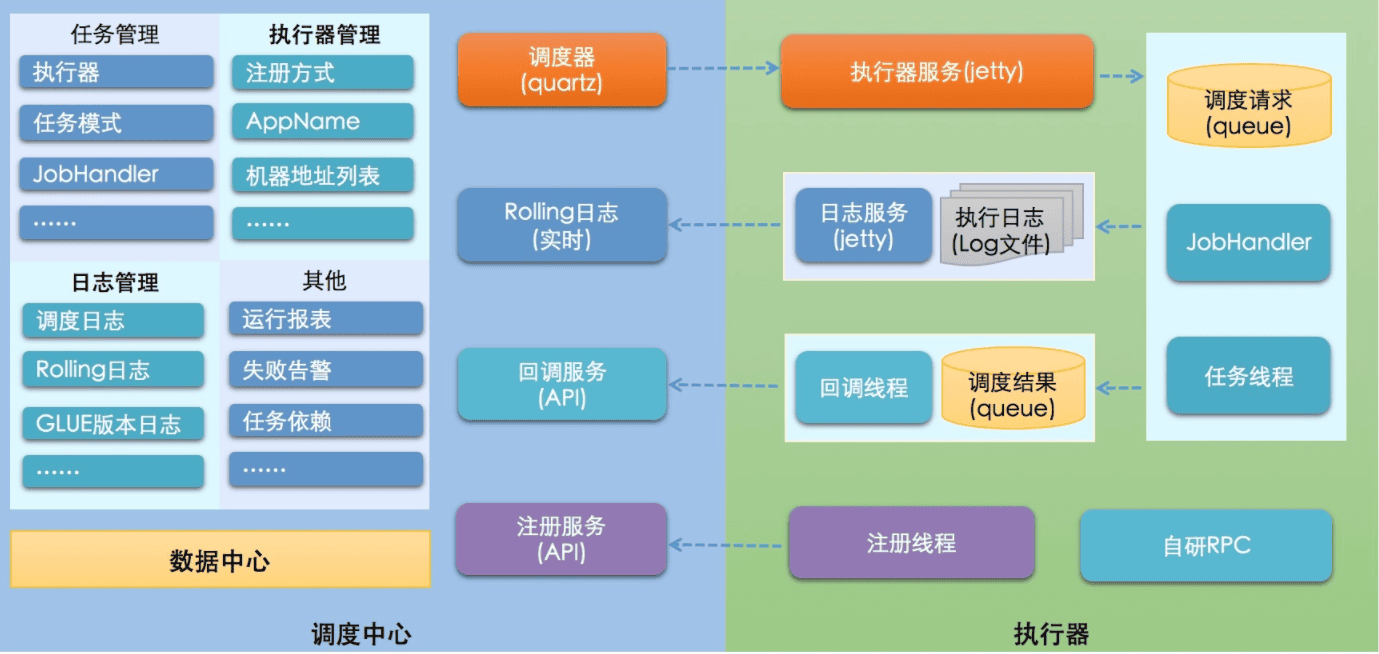
13.7 分布式会话
Cookie和Session有什么区别?
cookie和session的方案虽然分别属于客户端和服务端,但是服务端的session的实现对客户端的cookie有依赖关系的,服务端执行session机制时候会生成session的id值,这个id值会发送给客户端,客户端每次请求都会把这个id值放到http请求的头部发送给服务端,而这个id值在客户端会保存下来,保存的容器就是cookie,因此当我们完全禁掉浏览器的cookie的时候,服务端的session也会不能正常使用。
谈谈会话技术的发展?
- 单机 - Session + Cookie
- 多机器
- 在负载均衡侧 - Session 粘滞
- Session数据同步
- 多机器,集群 - session集中管理,比如redis;目前方案上用的最多的是SpringSession,早前也有用tomcat集成方式的。
- 无状态token,比如JWT
分布式会话有哪些解决方案?
- Session Stick
- Session Replication
- Session 数据集中存储
- Cookie Based
- JWT
什么是Session Stick?
方案即将客户端的每次请求都转发至同一台服务器,这就需要负载均衡器能够根据每次请求的会话标识(SessionId)来进行请求转发,如下图所示。
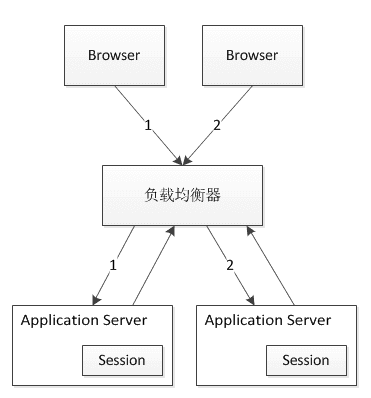
这种方案实现比较简单,对于Web服务器来说和单机的情况一样。但是可能会带来如下问题:
- 如果有一台服务器宕机或者重启,那么这台机器上的会话数据会全部丢失。
- 会话标识是应用层信息,那么负载均衡要将同一个会话的请求都保存到同一个Web服务器上的话,就需要进行应用层(第7层)的解析,这个开销比第4层大。
- 负载均衡器将变成一个有状态的节点,要将会话保存到具体Web服务器的映射。和无状态节点相比,内存消耗更大,容灾方面也会更麻烦。
PS:为什么这种方案到目前还有很多项目使用呢?因为不需要在项目代码侧改动,而是只需要在负载均衡侧改动。
什么是Session Replication?
Session Replication 的方案则不对负载均衡器做更改,而是在Web服务器之间增加了会话数据同步的功能,各个服务器之间通过同步保证不同Web服务器之间的Session数据的一致性,如下图所示。
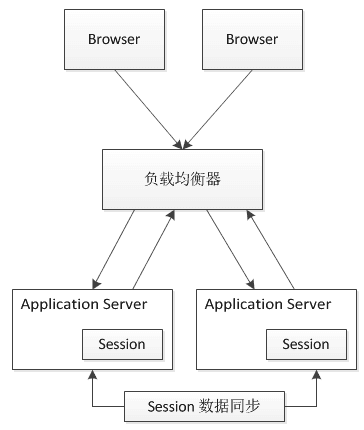
Session Replication 方案对负载均衡器不再有要求,但是同样会带来以下问题:
- 同步Session数据会造成额外的网络带宽的开销,只要Session数据有变化,就需要将新产生的Session数据同步到其他服务器上,服务器数量越多,同步带来的网络带宽开销也就越大。
- 每台Web服务器都需要保存全部的Session数据,如果整个集群的Session数量太多的话,则对于每台机器用于保存Session数据的占用会很严重。
什么是Session 数据集中存储?
Session 数据集中存储方案则是将集群中的所有Session集中存储起来,Web服务器本身则并不存储Session数据,不同的Web服务器从同样的地方来获取Session,如下图所示。
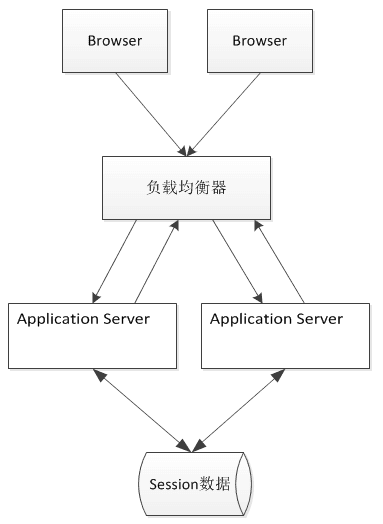
相对于Session Replication方案,此方案的Session数据将不保存在本机,并且Web服务器之间也没有了Session数据的复制,但是该方案存在的问题在于:
- 读写Session数据引入了网络操作,这相对于本机的数据读取来说,问题就在于存在时延和不稳定性,但是通信发生在内网,则问题不大。
- 如果集中存储Session的机器或集群出现问题,则会影响应用。
什么是Cookie Based Session?
Cookie Based 方案是将Session数据放在Cookie里,访问Web服务器的时候,再由Web服务器生成对应的Session数据,如下图所示。

但是Cookie Based 方案依然存在不足:
- Cookie长度的限制。这会导致Session长度的限制。
- 安全性。Seesion数据本来是服务端数据,却被保存在了客户端,即使可以加密,但是依然存在不安全性。
- 带宽消耗。这里不是指内部Web服务器之间的宽带消耗,而是数据中心的整体外部带宽的消耗。
- 性能影响。每次HTTP请求和响应都带有Seesion数据,对Web服务器来说,在同样的处理情况下,响应的结果输出越少,支持的并发就会越高。
什么是JWT?使用JWT的流程?对比传统的会话有啥区别?
JSON Web Token,一般用它来替换掉Session实现数据共享。
使用基于 Token 的身份验证方法,在服务端不需要存储用户的登录记录。大概的流程是这样的:
- 1、客户端通过用户名和密码登录服务器;
- 2、服务端对客户端身份进行验证;
- 3、服务端对该用户生成Token,返回给客户端;
- 4、客户端将Token保存到本地浏览器,一般保存到cookie中;
- 5、客户端发起请求,需要携带该Token;
- 6、服务端收到请求后,首先验证Token,之后返回数据。
如上图为Token实现方式,浏览器第一次访问服务器,根据传过来的唯一标识userId,服务端会通过一些算法,如常用的HMAC-SHA256算法,然后加一个密钥,生成一个token,然后通过BASE64编码一下之后将这个token发送给客户端;客户端将token保存起来,下次请求时,带着token,服务器收到请求后,然后会用相同的算法和密钥去验证token,如果通过,执行业务操作,不通过,返回不通过信息。
可以对比下图session实现方式,流程大致一致。
优点:
- 无状态、可扩展 :在客户端存储的Token是无状态的,并且能够被扩展。基于这种无状态和不存储Session信息,负载均衡器能够将用户信息从一个服务传到其他服务器上。
- 安全:请求中发送token而不再是发送cookie能够防止CSRF(跨站请求伪造)。
- 可提供接口给第三方服务:使用token时,可以提供可选的权限给第三方应用程序。
- 多平台跨域
对应用程序和服务进行扩展的时候,需要介入各种各种的设备和应用程序。 假如我们的后端api服务器a.com只提供数据,而静态资源则存放在cdn 服务器b.com上。当我们从a.com请求b.com下面的资源时,由于触发浏览器的同源策略限制而被阻止。
我们通过CORS(跨域资源共享)标准和token来解决资源共享和安全问题。
举个例子,我们可以设置b.com的响应首部字段为:
// 第一行指定了允许访问该资源的外域 URI。
Access-Control-Allow-Origin: http://a.com
// 第二行指明了实际请求中允许携带的首部字段,这里加入了Authorization,用来存放token。
Access-Control-Allow-Headers: Authorization, X-Requested-With, Content-Type, Accept
// 第三行用于预检请求的响应。其指明了实际请求所允许使用的 HTTP 方法。
Access-Control-Allow-Methods: GET, POST, PUT,DELETE
// 然后用户从a.com携带有一个通过了验证的token访问B域名,数据和资源就能够在任何域上被请求到。
13.8 常见系统设计
如何设计一个秒杀系统?
- 秒杀特点及思路?
短时间内,大量用户涌入,集中读和写有限的库存。
- 尽量将请求拦截在系统上游(越上游越好);
- 读多写少的多使用缓存(缓存抗读压力);
- 从分层角度理解?
层层拦截,将请求尽量拦截在系统上游,避免将锁冲落到数据库上。
- 第一层:客户端优化
产品层面,用户点击“查询”或者“购票”后,按钮置灰,禁止用户重复提交请求; JS层面,限制用户在x秒之内只能提交一次请求,比如微信摇一摇抢红包。 基本可以拦截80%的请求。
- 第二层:站点层面的请求拦截(nginx层,写流控模块)
怎么防止程序员写for循环调用,有去重依据么? IP? cookie-id? …想复杂了,这类业务都需要登录,用uid即可。在站点层面,对uid进行请求计数和去重,甚至不需要统一存储计数,直接站点层内存存储(这样计数会不准,但最简单,比如guava本地缓存)。一个uid,5秒只准透过1个请求,这样又能拦住99%的for循环请求。 对于5s内的无效请求,统一返回错误提示或错误页面。
这个方式拦住了写for循环发HTTP请求的程序员,有些高端程序员(黑客)控制了10w个肉鸡,手里有10w个uid,同时发请求(先不考虑实名制的问题,小米抢手机不需要实名制),这下怎么办,站点层按照uid限流拦不住了。
- 第三层:服务层拦截
方案一:写请求放到队列中,每次只透有限的写请求到数据层,如果成功了再放下一批,直到库存不够,队列里的写请求全部返回“已售完”。
方案二:或采用漏斗机制,只放一倍的流量进来,多余的返回“已售完”,把写压力转换成读压力。 读请求,用cache,redis单机可以抗10W QPS,用异步线程定时更新缓存里的库存值。
还有提示“模糊化”,比如火车余票查询,票剩了58张,还是26张,你真的关注么,其实我们只关心有票和无票。
- 第四层:数据库层
浏览器拦截了80%,站点层拦截了99.9%并做了页面缓存,服务层又做了写请求队列与数据缓存,每次透到数据库层的请求都是可控的。 db基本就没什么压力了,通过自身锁机制来控制,避免出现超卖。
- 从架构角度理解?
- 高性能
- 动静分离 秒杀过程中你是不需要刷新整个页面的,只有时间在不停跳动。这是因为一般都会对大流量的秒杀系统做系统的静态化改造,即数据意义上的动静分离。动静分离三步走:
- 数据拆分;
- 静态缓存;
- 数据整合。
- 热点优化 数据的热点优化与动静分离是不一样的,热点优化是基于二八原则对数据进行了纵向拆分,以便进行针对性地处理。热点识别和隔离不仅对“秒杀”这个场景有意义,对其他的高性能分布式系统也非常有参考价值。
- 系统优化
- 减少序列化:减少 Java 中的序列化操作可以很好的提升系统性能。序列化大部分是在 RPC 阶段发生,因此应该尽量减少 RPC 调用,一种可行的方案是将多个关联性较强的应用进行 “合并部署”,从而减少不同应用之间的 RPC 调用(微服务设计规范)
- 直接输出流数据:只要涉及字符串的I/O操作,无论是磁盘 I/O 还是网络 I/O,都比较耗费 CPU 资源,因为字符需要转换成字节,而这个转换又必须查表编码。所以对于常用数据,比如静态字符串,推荐提前编码成字节并缓存,具体到代码层面就是通过 OutputStream() 类函数从而减少数据的编码转换;另外,热点方法toString()不要直接调用ReflectionToString实现,推荐直接硬编码,并且只打印DO的基础要素和核心要素
- 裁剪日志异常堆栈:无论是外部系统异常还是应用本身异常,都会有堆栈打出,超大流量下,频繁的输出完整堆栈,只会加剧系统当前负载。可以通过日志配置文件控制异常堆栈输出的深度
- 去组件框架:极致优化要求下,可以去掉一些组件框架,比如去掉传统的 MVC 框架,直接使用 Servlet 处理请求。这样可以绕过一大堆复杂且用处不大的处理逻辑,节省毫秒级的时间,当然,需要合理评估你对框架的依赖程度
- 动静分离 秒杀过程中你是不需要刷新整个页面的,只有时间在不停跳动。这是因为一般都会对大流量的秒杀系统做系统的静态化改造,即数据意义上的动静分离。动静分离三步走:
- 高可用
- 流量削峰
- 答题:答题目前已经使用的非常普遍了,本质是通过在入口层削减流量,从而让系统更好地支撑瞬时峰值。
- MQ: 最为常见的削峰方案是使用消息队列,通过把同步的直接调用转换成异步的间接推送缓冲瞬时流量。
- 过滤
- Plan B: 为了保证系统的高可用,必须设计一个 Plan B 方案来进行兜底。
- 流量削峰
接口设计要考虑哪些方面?
讲讲几个要点:
- 接口版本化
- 命名规范
- 请求参数的规范性及处理的统一性
- 返回数据类型、返回码及信息提示的规范性
- 接口安全验证及权限的控制
- 请求接口日志的记录
- 良好的接口说明文档和测试程序
什么是接口幂等?如何保证接口的幂等性?
接口的幂等性实际上就是接口可重复调用,在调用方多次调用的情况下,接口最终得到的结果是一致的。有些接口可以天然的实现幂等性,比如查询接口,对于查询来说,你查询一次和两次,对于系统来说,没有任何影响,查出的结果也是一样。
除了查询功能具有天然的幂等性之外,增加、更新、删除都要保证幂等性。那么如何来保证幂等性呢?
- 全局唯一ID
如果使用全局唯一ID,就是根据业务的操作和内容生成一个全局ID,在执行操作前先根据这个全局唯一ID是否存在,来判断这个操作是否已经执行。如果不存在则把全局ID,存储到存储系统中,比如数据库、redis等。如果存在则表示该方法已经执行。
从工程的角度来说,使用全局ID做幂等可以作为一个业务的基础的微服务存在,在很多的微服务中都会用到这样的服务,在每个微服务中都完成这样的功能,会存在工作量重复。另外打造一个高可靠的幂等服务还需要考虑很多问题,比如一台机器虽然把全局ID先写入了存储,但是在写入之后挂了,这就需要引入全局ID的超时机制。
使用全局唯一ID是一个通用方案,可以支持插入、更新、删除业务操作。但是这个方案看起来很美但是实现起来比较麻烦,下面的方案适用于特定的场景,但是实现起来比较简单。
- 去重表
这种方法适用于在业务中有唯一标的插入场景中,比如在以上的支付场景中,如果一个订单只会支付一次,所以订单ID可以作为唯一标识。这时,我们就可以建一张去重表,并且把唯一标识作为唯一索引,在我们实现时,把创建支付单据和写入去去重表,放在一个事务中,如果重复创建,数据库会抛出唯一约束异常,操作就会回滚。
- 插入或更新
这种方法插入并且有唯一索引的情况,比如我们要关联商品品类,其中商品的ID和品类的ID可以构成唯一索引,并且在数据表中也增加了唯一索引。这时就可以使用InsertOrUpdate操作。在mysql数据库中如下:
insert into goods_category (goods_id,category_id,create_time,update_time)
values(#{goodsId},#{categoryId},now(),now())
on DUPLICATE KEY UPDATE
update_time=now()
- 多版本控制
这种方法适合在更新的场景中,比如我们要更新商品的名字,这时我们就可以在更新的接口中增加一个版本号,来做幂等
boolean updateGoodsName(int id,String newName,int version);
在实现时可以如下
update goods set name=#{newName},version=#{version} where id=#{id} and version<${version}
- 状态机控制
这种方法适合在有状态机流转的情况下,比如就会订单的创建和付款,订单的付款肯定是在之前,这时我们可以通过在设计状态字段时,使用int类型,并且通过值类型的大小来做幂等,比如订单的创建为0,付款成功为100。付款失败为99
在做状态机更新时,我们就这可以这样控制
update `order` set status=#{status} where id=#{id} and status<#{status}
14 微服务
14.1 Spring Cloud
什么是微服务?谈谈你对微服务的理解?
- 微服务
以前所有的代码都放在同一个工程中、部署在同一个服务器、同一项目的不同模块不同功能互相抢占资源,微服务就是将工程根据不同的业务规则拆分成微服务,部署在不同的服务器上,服务之间相互调用,java中有的微服务有dubbo(只能用来做微服务)、springcloud( 提供了服务的发现、断路器等)。
- 微服务的特点:
- 按业务划分为一个独立运行的程序,即服务单元
- 服务之间通过HTTP协议相互通信
- 自动化部署
- 可以用不同的编程语言
- 可以用不同的存储技术
- 服务集中化管理
- 微服务是一个分布式系统
- 微服务的优势
- 将一个复杂的业务拆分为若干小的业务,将复杂的业务简单化,新人只需要了解他所接管的服务的代码,减少了新人的学习成本。
- 由于微服务是分布式服务,服务于服务之间没有任何耦合。微服务系统的微服务单元具有很强的横向拓展能力。
- 服务于服务之间采用HTTP网络通信协议来通信,单个服务内部高度耦合,服务与服务之间完全独立,无耦合。这使得微服务可以采用任何的开发语言和技术来实现,提高开发效率、降低开发成本。
- 微服务是按照业务进行拆分的,并有坚实的服务边界,若要重写某一业务代码,不需了解所有业务,重写简单。
- 微服务的每个服务单元是独立部署的,即独立运行在某个进程中,微服务的修改和部署对其他服务没有影响。
- 微服务在CAP理论中采用的AP架构,具有高可用分区容错特点。高可用主要体现在系统7x24不间断服务,他要求系统有大量的服务器集群,从而提高系统的负载能力。分区容错也使得系统更加健壮。
- 微服务的不足
- 微服务的复杂度:构建一个微服务比较复杂,服务与服务之间通过HTTP协议或其他消息传递机制通信,开发者要选出最佳的通信机制,并解决网络服务差时带来的风险。 2.分布式事物:将事物分成多阶段提交,如果一阶段某一节点失败仍会导致数据不正确。如果事物涉及的节点很多,某一节点的网络出现异常会导致整个事务处于阻塞状态,大大降低数据库的性能。
- 服务划分:将一个完整的系统拆分成很多个服务,是一件非常困难的事,因为这涉及了具体的业务场景
- 服务部署:最佳部署容器Docker
- 微服务和SOA的关系
微服务相对于和ESB联系在一起的SOA轻便敏捷的多,微服务将复杂的业务组件化,也是一种面向服务思想的体现。对于微服务来说,它是SOA的一种体现,但是它比ESB实现的SOA更加轻便、敏捷和简单。
什么是Spring Cloud?
Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、智能路由、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。
Spring Cloud并没有重复制造轮子,它只是将各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
- SpringCloud的优点
- 耦合度比较低。不会影响其他模块的开发。
- 减轻团队的成本,可以并行开发,不用关注其他人怎么开发,先关注自己的开发。
- 配置比较简单,基本用注解就能实现,不用使用过多的配置文件。
- 微服务跨平台的,可以用任何一种语言开发。
- 每个微服务可以有自己的独立的数据库也有用公共的数据库。
- 直接写后端的代码,不用关注前端怎么开发,直接写自己的后端代码即可,然后暴露接口,通过组件进行服务通信。
- SpringCloud的缺点
- 部署比较麻烦,给运维工程师带来一定的麻烦。
- 针对数据的管理比麻烦,因为微服务可以每个微服务使用一个数据库。
- 系统集成测试比较麻烦
- 性能的监控比较麻烦。
springcloud中的组件有那些?
说出主要的组件:
- Spring Cloud Eureka,服务注册中心,特性有失效剔除、服务保护
- Spring Cloud Zuul,API服务网关,功能有路由分发和过滤
- Spring Cloud Config,分布式配置中心,支持本地仓库、SVN、Git、Jar包内配置等模式
- Spring Cloud Ribbon,客户端负载均衡,特性有区域亲和,重试机制
- Spring Cloud Hystrix,客户端容错保护,特性有服务降级、服务熔断、请求缓存、请求合并、依赖隔离
- Spring Cloud Feign,声明式服务调用本质上就是Ribbon+Hystrix
- Spring Cloud Stream,消息驱动,有Sink、Source、Processor三种通道,特性有订阅发布、消费组、消息分区
- Spring Cloud Bus,消息总线,配合Config仓库修改的一种Stream实现,
- Spring Cloud Sleuth,分布式服务追踪,需要搞清楚TraceID和SpanID以及抽样,如何与ELK整合
具体说说SpringCloud主要项目?
Spring Cloud的子项目,大致可分成两类,一类是对现有成熟框架"Spring Boot化"的封装和抽象,也是数量最多的项目;第二类是开发了一部分分布式系统的基础设施的实现,如Spring Cloud Stream扮演的就是kafka, ActiveMQ这样的角色。
- Spring Cloud Config Config能够管理所有微服务的配置文件
集中配置管理工具,分布式系统中统一的外部配置管理,默认使用Git来存储配置,可以支持客户端配置的刷新及加密、解密操作。
- Spring Cloud Netflix
Netflix OSS 开源组件集成,包括Eureka、Hystrix、Ribbon、Feign、Zuul等核心组件。
- Eureka:服务治理组件,包括服务端的注册中心和客户端的服务发现机制;
- Ribbon:负载均衡的服务调用组件,具有多种负载均衡调用策略;
- Hystrix:服务容错组件,实现了断路器模式,为依赖服务的出错和延迟提供了容错能力;
- Feign:基于Ribbon和Hystrix的声明式服务调用组件;
- Zuul:API网关组件,对请求提供路由及过滤功能。
- Spring Cloud Bus
- 用于传播集群状态变化的消息总线,使用轻量级消息代理链接分布式系统中的节点,可以用来动态刷新集群中的服务配置信息。
- 简单来说就是修改了配置文件,发送一次请求,所有客户端便会重新读取配置文件(需要利用中间插件MQ)。
- Spring Cloud Consul
Consul 是 HashiCorp 公司推出的开源工具,用于实现分布式系统的服务发现与配置。与其它分布式服务注册与发现的方案,Consul 的方案更“一站式”,内置了服务注册与发现框架、分布一致性协议实现、健康检查、Key/Value 存储、多数据中心方案,不再需要依赖其它工具(比如 ZooKeeper 等)。使用起来也较为简单。Consul 使用 Go 语言编写,因此具有天然可移植性(支持Linux、windows和Mac OS X);安装包仅包含一个可执行文件,方便部署,与 Docker 等轻量级容器可无缝配合。
- Spring Cloud Security
Spring Cloud Security提供了一组原语,用于构建安全的应用程序和服务,而且操作简便。可以在外部(或集中)进行大量配置的声明性模型有助于实现大型协作的远程组件系统,通常具有中央身份管理服务。它也非常易于在Cloud Foundry等服务平台中使用。在Spring Boot和Spring Security OAuth2的基础上,可以快速创建实现常见模式的系统,如单点登录,令牌中继和令牌交换。
- Spring Cloud Sleuth
在微服务中,通常根据业务模块分服务,项目中前端发起一个请求,后端可能跨几个服务调用才能完成这个请求(如下图)。如果系统越来越庞大,服务之间的调用与被调用关系就会变得很复杂,假如一个请求中需要跨几个服务调用,其中一个服务由于网络延迟等原因挂掉了,那么这时候我们需要分析具体哪一个服务出问题了就会显得很困难。Spring Cloud Sleuth服务链路跟踪功能就可以帮助我们快速的发现错误根源以及监控分析每条请求链路上的性能等等。
- Spring Cloud Stream
轻量级事件驱动微服务框架,可以使用简单的声明式模型来发送及接收消息,主要实现为Apache Kafka及RabbitMQ。
- Spring Cloud Task
Spring Cloud Task的目标是为Spring Boot应用程序提供创建短运行期微服务的功能。在Spring Cloud Task中,我们可以灵活地动态运行任何任务,按需分配资源并在任务完成后检索结果。Tasks是Spring Cloud Data Flow中的一个基础项目,允许用户将几乎任何Spring Boot应用程序作为一个短期任务执行。
- Spring Cloud Zookeeper
- SpringCloud支持三种注册方式Eureka, Consul(go语言编写),zookeeper
- Spring Cloud Zookeeper是基于Apache Zookeeper的服务治理组件。
- Spring Cloud Gateway
Spring cloud gateway是spring官方基于Spring 5.0、Spring Boot2.0和Project Reactor等技术开发的网关,Spring Cloud Gateway旨在为微服务架构提供简单、有效和统一的API路由管理方式,Spring Cloud Gateway作为Spring Cloud生态系统中的网关,目标是替代Netflix Zuul,其不仅提供统一的路由方式,并且还基于Filer链的方式提供了网关基本的功能,例如:安全、监控/埋点、限流等。
- Spring Cloud OpenFeign
Feign是一个声明性的Web服务客户端。它使编写Web服务客户端变得更容易。要使用Feign,我们可以将调用的服务方法定义成抽象方法保存在本地添加一点点注解就可以了,不需要自己构建Http请求了,直接调用接口就行了,不过要注意,调用方法要和本地抽象方法的签名完全一致。
Spring Cloud项目部署架构?

Spring Cloud 和dubbo区别?
- 服务调用方式:dubbo是RPC springcloud Rest Api
- 注册中心:dubbo 是zookeeper springcloud是eureka,也可以是zookeeper
- 服务网关,dubbo本身没有实现,只能通过其他第三方技术整合,springcloud有Zuul路由网关,作为路由服务器,进行消费者的请求分发,springcloud支持断路器,与git完美集成配置文件支持版本控制,事物总线实现配置文件的更新与服务自动装配等等一系列的微服务架构要素。
服务注册和发现是什么意思?Spring Cloud 如何实现?
当我们开始一个项目时,我们通常在属性文件中进行所有的配置。随着越来越多的服务开发和部署,添加和修改这些属性变得更加复杂。有些服务可能会下降,而某些位置可能会发生变化。手动更改属性可能会产生问题。 Eureka 服务注册和发现可以在这种情况下提供帮助。由于所有服务都在 Eureka 服务器上注册并通过调用 Eureka 服务器完成查找,因此无需处理服务地点的任何更改和处理。
什么是Eureka?
Eureka作为SpringCloud的服务注册功能服务器,他是服务注册中心,系统中的其他服务使用Eureka的客户端将其连接到Eureka Service中,并且保持心跳,这样工作人员可以通过Eureka Service来监控各个微服务是否运行正常。
Eureka怎么实现高可用?
集群吧,注册多台Eureka,然后把SpringCloud服务互相注册,客户端从Eureka获取信息时,按照Eureka的顺序来访问。
什么是Eureka的自我保护模式?
默认情况下,如果Eureka Service在一定时间内没有接收到某个微服务的心跳,Eureka Service会进入自我保护模式,在该模式下Eureka Service会保护服务注册表中的信息,不再删除注册表中的数据,当网络故障恢复后,Eureka Servic 节点会自动退出自我保护模式
DiscoveryClient的作用?
可以从注册中心中根据服务别名获取注册的服务器信息。
Eureka和ZooKeeper都可以提供服务注册与发现的功能,请说说两个的区别?
ZooKeeper中的节点服务挂了就要选举,在选举期间注册服务瘫痪,虽然服务最终会恢复,但是选举期间不可用的,选举就是改微服务做了集群,必须有一台主其他的都是从
Eureka各个节点是平等关系,服务器挂了没关系,只要有一台Eureka就可以保证服务可用,数据都是最新的。如果查询到的数据并不是最新的,就是因为Eureka的自我保护模式导致的
Eureka本质上是一个工程,而ZooKeeper只是一个进程
Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像ZooKeeper 一样使得整个注册系统瘫痪
ZooKeeper保证的是CP,Eureka保证的是AP
什么是网关?
网关相当于一个网络服务架构的入口,所有网络请求必须通过网关转发到具体的服务。
网关的作用是什么?
统一管理微服务请求,权限控制、负载均衡、路由转发、监控、安全控制黑名单和白名单等
什么是Spring Cloud Zuul(服务网关)?
Zuul是对SpringCloud提供的成熟对的路由方案,他会根据请求的路径不同,网关会定位到指定的微服务,并代理请求到不同的微服务接口,他对外隐蔽了微服务的真正接口地址。
- 三个重要概念:动态路由表,路由定位,反向代理:
- 动态路由表:Zuul支持Eureka路由,手动配置路由,这俩种都支持自动更新
- 路由定位:根据请求路径,Zuul有自己的一套定位服务规则以及路由表达式匹配
- 反向代理:客户端请求到路由网关,网关受理之后,在对目标发送请求,拿到响应之后在 给客户端
- 它可以和Eureka,Ribbon,Hystrix等组件配合使用,
- Zuul的应用场景:
- 对外暴露,权限校验,服务聚合,日志审计等
网关与过滤器有什么区别?
网关是对所有服务的请求进行分析过滤,过滤器是对单个服务而言。
常用网关框架有那些?
Nginx、Zuul、Gateway
Zuul与Nginx有什么区别?
Zuul是java语言实现的,主要为java服务提供网关服务,尤其在微服务架构中可以更加灵活的对网关进行操作。Nginx是使用C语言实现,性能高于Zuul,但是实现自定义操作需要熟悉lua语言,对程序员要求较高,可以使用Nginx做Zuul集群。
既然Nginx可以实现网关?为什么还需要使用Zuul框架?
Zuul是SpringCloud集成的网关,使用Java语言编写,可以对SpringCloud架构提供更灵活的服务。
ZuulFilter常用有那些方法?
- Run():过滤器的具体业务逻辑
- shouldFilter():判断过滤器是否有效
- filterOrder():过滤器执行顺序
- filterType():过滤器拦截位置
如何实现动态Zuul网关路由转发?
通过path配置拦截请求,通过ServiceId到配置中心获取转发的服务列表,Zuul内部使用Ribbon实现本地负载均衡和转发。
Zuul网关如何搭建集群?
使用Nginx的upstream设置Zuul服务集群,通过location拦截请求并转发到upstream,默认使用轮询机制对Zuul集群发送请求。
Ribbon是什么?
Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法
Ribbon客户端组件提供一系列完善的配置项,如连接超时,重试等。简单的说,就是在配置文件中列出后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器。我们也很容易使用Ribbon实现自定义的负载均衡算法。(有点类似Nginx)
Nginx与Ribbon的区别?
Nginx是反向代理同时可以实现负载均衡,nginx拦截客户端请求采用负载均衡策略根据upstream配置进行转发,相当于请求通过nginx服务器进行转发。Ribbon是客户端负载均衡,从注册中心读取目标服务器信息,然后客户端采用轮询策略对服务直接访问,全程在客户端操作。
Ribbon底层实现原理?
Ribbon使用discoveryClient从注册中心读取目标服务信息,对同一接口请求进行计数,使用%取余算法获取目标服务集群索引,返回获取到的目标服务信息。
@LoadBalanced注解的作用?
开启客户端负载均衡。
什么是断路器
当一个服务调用另一个服务由于网络原因或自身原因出现问题,调用者就会等待被调用者的响应 当更多的服务请求到这些资源导致更多的请求等待,发生连锁效应(雪崩效应)
断路器有三种状态
- 打开状态:一段时间内 达到一定的次数无法调用 并且多次监测没有恢复的迹象 断路器完全打开 那么下次请求就不会请求到该服务
- 半开状态:短时间内 有恢复迹象 断路器会将部分请求发给该服务,正常调用时 断路器关闭
- 关闭状态:当服务一直处于正常状态 能正常调用
什么是 Hystrix?
在分布式系统,我们一定会依赖各种服务,那么这些个服务一定会出现失败的情况,就会导致雪崩,Hystrix就是这样的一个工具,防雪崩利器,它具有服务降级,服务熔断,服务隔离,监控等一些防止雪崩的技术。
Hystrix有四种防雪崩方式:
- 服务降级:接口调用失败就调用本地的方法返回一个空
- 服务熔断:接口调用失败就会进入调用接口提前定义好的一个熔断的方法,返回错误信息
- 服务隔离:隔离服务之间相互影响
- 服务监控:在服务发生调用时,会将每秒请求数、成功请求数等运行指标记录下来。
什么是Feign?
Feign 是一个声明web服务客户端,这使得编写web服务客户端更容易
他将我们需要调用的服务方法定义成抽象方法保存在本地就可以了,不需要自己构建Http请求了,直接调用接口就行了,不过要注意,调用方法要和本地抽象方法的签名完全一致。
SpringCloud有几种调用接口方式?
Feign
RestTemplate
Ribbon和Feign调用服务的区别?
调用方式同:Ribbon需要我们自己构建Http请求,模拟Http请求然后通过RestTemplate发给其他服务,步骤相当繁琐
而Feign则是在Ribbon的基础上进行了一次改进,采用接口的形式,将我们需要调用的服务方法定义成抽象方法保存在本地就可以了,不需要自己构建Http请求了,直接调用接口就行了,不过要注意,调用方法要和本地抽象方法的签名完全一致。
什么是 Spring Cloud Bus?
- Spring Cloud Bus就像一个分布式执行器,用于扩展的Spring Boot应用程序的配置文件,但也可以用作应用程序之间的通信通道。
- Spring Cloud Bus 不能单独完成通信,需要配合MQ支持
- Spring Cloud Bus一般是配合Spring Cloud Config做配置中心的
- Springcloud config实时刷新也必须采用SpringCloud Bus消息总线
什么是Spring Cloud Config?
Spring Cloud Config为分布式系统中的外部配置提供服务器和客户端支持,可以方便的对微服务各个环境下的配置进行集中式管理。Spring Cloud Config分为Config Server和Config Client两部分。Config Server负责读取配置文件,并且暴露Http API接口,Config Client通过调用Config Server的接口来读取配置文件。
分布式配置中心有那些框架?
Apollo、zookeeper、springcloud config。
分布式配置中心的作用?
动态变更项目配置信息而不必重新部署项目。
SpringCloud Config 可以实现实时刷新吗?
springcloud config实时刷新采用SpringCloud Bus消息总线。
什么是Spring Cloud Gateway?
Spring Cloud Gateway是Spring Cloud官方推出的第二代网关框架,取代Zuul网关。网关作为流量的,在微服务系统中有着非常作用,网关常见的功能有路由转发、权限校验、限流控制等作用。
使用了一个RouteLocatorBuilder的bean去创建路由,除了创建路由RouteLocatorBuilder可以让你添加各种predicates和filters,predicates断言的意思,顾名思义就是根据具体的请求的规则,由具体的route去处理,filters是各种过滤器,用来对请求做各种判断和修改。
14.2 Kubernetes
什么是Kubernetes? Kubernetes与Docker有什么关系?
- 是什么?
Kubernetes是一个开源容器管理工具,负责容器部署,容器扩缩容以及负载平衡。作为Google的创意之作,它提供了出色的社区,并与所有云提供商合作。因此,我们可以说Kubernetes不是一个容器化平台,而是一个多容器管理解决方案。
众所周知,Docker提供容器的生命周期管理,Docker镜像构建运行时容器。但是,由于这些单独的容器必须通信,因此使用Kubernetes。因此,我们说Docker构建容器,这些容器通过Kubernetes相互通信。因此,可以使用Kubernetes手动关联和编排在多个主机上运行的容器。
- 有哪些特性?
- 自我修复: 在节点故障时可以删除失效容器,重新创建新的容器,替换和重新部署,保证预期的副本数量,kill掉健康检查失败的容器,并且在容器未准备好之前不会处理客户端情况,确保线上服务不会中断
- 弹性伸缩: 使用命令、UI或者k8s基于cpu使用情况自动快速扩容和缩容应用程序实例,保证应用业务高峰并发时的高可用性,业务低峰时回收资源,以最小成本运行服务
- 自动部署和回滚: k8s采用滚动更新策略更新应用,一次更新一个pod,而不是同时删除所有pod,如果更新过程中出现问题,将回滚恢复,确保升级不影响业务
- 服务发现和负载均衡: k8s为多个容器提供一个统一访问入口(内部IP地址和一个dns名称)并且负载均衡关联的所有容器,使得用户无需考虑容器IP问题
- 机密和配置管理: 管理机密数据和应用程序配置,而不需要把敏感数据暴露在径向力,提高敏感数据安全性,并可以将一些常用的配置存储在k8s中,方便应用程序调用
- 存储编排: 挂载外部存储系统,无论时来自本地存储、公有云(aws)、还是网络存储(nfs、GFS、ceph),都作为集群资源的一部分使用,极大提高存储使用灵活性
- 批处理: 提供一次性任务,定时任务:满足批量数据处理和分析的场景
Kubernetes的整体架构?
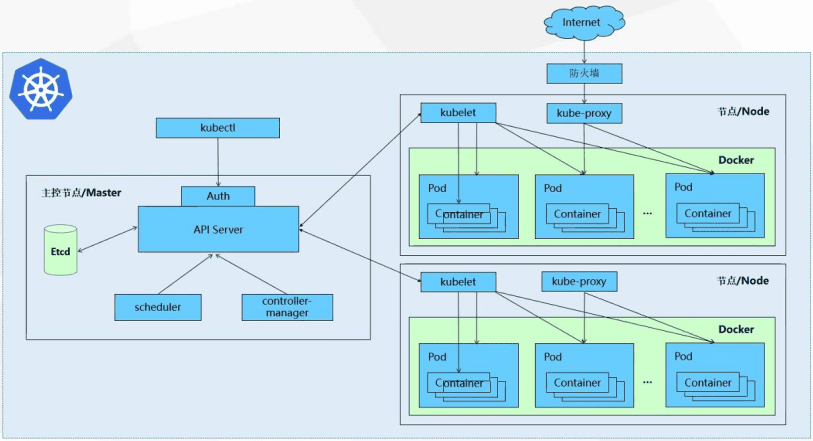
Kubernetes主要由以下几个核心组件组成:
- etcd:提供数据库服务保存了整个集群的状态
- kube-apiserver:提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制
- kube-controller-manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等
- cloud-controller-manager:是与底层云计算服务商交互的控制器
- kub-scheduler:负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上
- kubelet:负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;
- kube-proxy:负责为Service提供内部的服务发现和负载均衡,并维护网络规则
- container-runtime:是负责管理运行容器的软件,比如docker
除了核心组件,还有一些推荐的Add-ons:
- kube-dns负责为整个集群提供DNS服务
- Ingress Controller为服务提供外网入口
- Heapster提供资源监控
- Dashboard提供GUI
- Federation提供跨可用区的集群
- Fluentd-elasticsearch提供集群日志采集、存储与查询
Kubernetes中有哪些核心概念?
- Cluster、Master、Node
- Cluster
- Cluster(集群) 是计算、存储和网络资源的集合,Kubernetes 利用这些资源运行各种基于容器的应用。最简单的 Cluster 可以只有一台主机(它既是 Mater 也是 Node)
- Master
- Master 是 Cluster 的大脑,它的主要职责是调度,即决定将应用放在哪里运行。
- Master 运行 Linux 操作系统,可以是物理机或者虚拟机。
- 为了实现高可用,可以运行多个 Master。
- Node
- Node 的职责是运行容器应用。
- Node 由 Master 管理,Node 负责监控并汇报容器的状态,并根据 Master 的要求管理容器的生命周期。
- Node 运行在 Linux 操作系统,可以是物理机或者是虚拟机。
- Pod
- 基本概念
- Pod 是 Kubernetes 的最小工作单元。
- 每个 Pod 包含一个或多个容器。Pod 中的容器会作为一个整体被 Master 调度到一个 Node 上运行。
- 引入 Pod 的目的
可管理性: 有些容器天生就是需要紧密联系,一起工作。Pod 提供了比容器更高层次的抽象,将它们封装到一个部署单元中。Kubernetes 以 Pod 为最小单位进行调度、扩展、共享资源、管理生命周期。通信和资源共享: Pod 中的所有容器使用同一个网络 namespace,即相同的 IP 地址和 Port 空间。它们可以直接用 localhost 通信。同样的,这些容器可以共享存储,当 Kubernetes 挂载 volume 到 Pod,本质上是将 volume 挂载到 Pod 中的每一个容器。
- Pod 的使用方式
运行单一容器: one-container-per-Pod 是 Kubernetes 最常见的模型,这种情况下,只是将单个容器简单封装成 Pod。即便是只有一个容器,Kubernetes 管理的也是 Pod 而不是直接管理容器。运行多个容器: 对于那些联系非常紧密,而且需要直接共享资源的容器,应该放在一个 Pod 中。比如下面这个 Pod 包含两个容器:一个 File Puller,一个是 Web Server。File Puller 会定期从外部的 Content Manager 中拉取最新的文件,将其存放在共享的 volume 中。Web Server 从 volume 读取文件,响应 Consumer 的请求。这两个容器是紧密协作的,它们一起为 Consumer 提供最新的数据;同时它们也通过 volume 共享数据。所以放到一个 Pod 是合适的。
- Controller
基本概念
- Kubernetes 通常不会直接创建 Pod,而是通过 Controller 来管理 Pod 的。Controller 中定义了 Pod 的部署特性,比如有几个副本,在什么样的 Node 上运行等。为了满足不同的业务场景,Kubernetes 提供了多种 Controller,包括 Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job 等。
各个 Controller
Deployment: Deployment 是最常用的 Controller,比如我们可以通过创建 Deployment 来部署应用的。Deployment 可以管理 Pod 的多个副本,并确保 Pod 按照期望的状态运行。ReplicaSet: ReplicaSet 实现了 Pod 的多副本管理。使用 Deployment 时会自动创建 ReplicaSet,也就是说 Deployment 是通过 ReplicaSet 来管理 Pod 的多个副本,我们通常不需要直接使用 ReplicaSet。DaemonSet: DaemonSet 用于每个 Node 最多只运行一个 Pod 副本的场景。正如其名称所揭示的,DaemonSet 通常用于运行 daemon。StatefuleSet: StatefuleSet 能够保证 Pod 的每个副本在整个生命周期中名称是不变的。而其他 Controller 不提供这个功能,当某个 Pod 发生故障需要删除并重新启动时,Pod 的名称会发生变化。同时 StatefuleSet 会保证副本按照固定的顺序启动、更新或者删除。Job: Job 用于运行结束就删除的应用。而其他 Controller 中的 Pod 通常是长期持续运行。
- Service、Namespace
Service
- Deployment 可以部署多个副本,每个 Pod 都有自己的 IP。而 Pod 很可能会被频繁地销毁和重启,它们的 IP 会发生变化,用 IP 来访问 Deployment 副本不太现实。
- Service 定义了外界访问一组特定 Pod 的方式。Service 有自己的 IP 和端口,Service 为 Pod 提供了负载均衡。
Namespace
- Namespace 可以将一个物理的 Cluster 逻辑上划分成多个虚拟 Cluster,每个 Cluster 就是一个 Namespace。不同 Namespace 里的资源是完全隔离的。
- Kubernetes 默认创建了两个 Namespace:
- default:创建资源时如果不指定,将被放到这个 Namespace 中。
- kube-system:Kubernetes 自己创建的系统资源将放到这个 Namespace 中。
什么是Heapster?
Heapster是由每个节点上运行的Kubelet提供的集群范围的数据聚合器。此容器管理工具在Kubernetes集群上本机支持,并作为pod运行,就像集群中的任何其他pod一样。因此,它基本上发现集群中的所有节点,并通过机上Kubernetes代理查询集群中Kubernetes节点的使用信息。
什么是Minikube?
Minikube是一种工具,可以在本地轻松运行Kubernetes。这将在虚拟机中运行单节点Kubernetes群集。
什么是Kubectl?
Kubectl是一个平台,您可以使用该平台将命令传递给集群。因此,它基本上为CLI提供了针对Kubernetes集群运行命令的方法,以及创建和管理Kubernetes组件的各种方法。
kube-apiserver和kube-scheduler的作用是什么?
kube -apiserver遵循横向扩展架构,是主节点控制面板的前端。这将公开Kubernetes主节点组件的所有API,并负责在Kubernetes节点和Kubernetes主组件之间建立通信。
kube-scheduler负责工作节点上工作负载的分配和管理。因此,它根据资源需求选择最合适的节点来运行未调度的pod,并跟踪资源利用率。它确保不在已满的节点上调度工作负载。
请你说一下kubenetes针对pod资源对象的健康监测机制?
K8s中对于pod资源对象的健康状态检测,提供了三类probe(探针)来执行对pod的健康监测:
- livenessProbe探针
可以根据用户自定义规则来判定pod是否健康,如果livenessProbe探针探测到容器不健康,则kubelet会根据其重启策略来决定是否重启,如果一个容器不包含livenessProbe探针,则kubelet会认为容器的livenessProbe探针的返回值永远成功。
ReadinessProbe探针 同样是可以根据用户自定义规则来判断pod是否健康,如果探测失败,控制器会将此pod从对应service的endpoint列表中移除,从此不再将任何请求调度到此Pod上,直到下次探测成功。
startupProbe探针 启动检查机制,应用一些启动缓慢的业务,避免业务长时间启动而被上面两类探针kill掉,这个问题也可以换另一种方式解决,就是定义上面两类探针机制时,初始化时间定义的长一些即可。
K8s中镜像的下载策略是什么?
可通过命令kubectl explain pod.spec.containers来查看imagePullPolicy这行的解释。
K8s的镜像下载策略有三种:Always、Never、IFNotPresent;
- Always:镜像标签为latest时,总是从指定的仓库中获取镜像;
- Never:禁止从仓库中下载镜像,也就是说只能使用本地镜像;
- IfNotPresent:仅当本地没有对应镜像时,才从目标仓库中下载。
默认的镜像下载策略是:当镜像标签是latest时,默认策略是Always;当镜像标签是自定义时(也就是标签不是latest),那么默认策略是IfNotPresent。
image的状态有哪些?
- Running:Pod所需的容器已经被成功调度到某个节点,且已经成功运行,
- Pending:APIserver创建了pod资源对象,并且已经存入etcd中,但它尚未被调度完成或者仍然处于仓库中下载镜像的过程
- Unknown:APIserver无法正常获取到pod对象的状态,通常是其无法与所在工作节点的kubelet通信所致。
如何控制滚动更新过程?
可以通过下面的命令查看到更新时可以控制的参数:
[root@master yaml]# kubectl explain deploy.spec.strategy.rollingUpdate
- maxSurge :此参数控制滚动更新过程,副本总数超过预期pod数量的上限。可以是百分比,也可以是具体的值。默认为1。 (上述参数的作用就是在更新过程中,值若为3,那么不管三七二一,先运行三个pod,用于替换旧的pod,以此类推)
- maxUnavailable:此参数控制滚动更新过程中,不可用的Pod的数量。 (这个值和上面的值没有任何关系,举个例子:我有十个pod,但是在更新的过程中,我允许这十个pod中最多有三个不可用,那么就将这个参数的值设置为3,在更新的过程中,只要不可用的pod数量小于或等于3,那么更新过程就不会停止)。
DaemonSet资源对象的特性?
DaemonSet这种资源对象会在每个k8s集群中的节点上运行,并且每个节点只能运行一个pod,这是它和deployment资源对象的最大也是唯一的区别。所以,在其yaml文件中,不支持定义replicas,除此之外,与Deployment、RS等资源对象的写法相同。
它的一般使用场景如下:
- 在去做每个节点的日志收集工作;
- 监控每个节点的的运行状态;
说说你对Job这种资源对象的了解?
Job与其他服务类容器不同,Job是一种工作类容器(一般用于做一次性任务)。使用常见不多,可以忽略这个问题。
#提高Job执行效率的方法:
spec:
parallelism: 2 #一次运行2个
completions: 8 #最多运行8个
template:
metadata:
pod的重启策略是什么?
可以通过命令kubectl explain pod.spec查看pod的重启策略。(restartPolicy字段)
- Always:但凡pod对象终止就重启,此为默认策略。
- OnFailure:仅在pod对象出现错误时才重启
描述一下pod的生命周期有哪些状态?
- Pending:表示pod已经被同意创建,正在等待kube-scheduler选择合适的节点创建,一般是在准备镜像;
- Running:表示pod中所有的容器已经被创建,并且至少有一个容器正在运行或者是正在启动或者是正在重启;
- Succeeded:表示所有容器已经成功终止,并且不会再启动;
- Failed:表示pod中所有容器都是非0(不正常)状态退出;
- Unknown:表示无法读取Pod状态,通常是kube-controller-manager无法与Pod通信。
创建一个pod的流程是什么?
1) 客户端提交Pod的配置信息(可以是yaml文件定义好的信息)到kube-apiserver; 2) Apiserver收到指令后,通知给controller-manager创建一个资源对象; 3) Controller-manager通过api-server将pod的配置信息存储到ETCD数据中心中; 4) Kube-scheduler检测到pod信息会开始调度预选,会先过滤掉不符合Pod资源配置要求的节点,然后开始调度调优,主要是挑选出更适合运行pod的节点,然后将pod的资源配置单发送到node节点上的kubelet组件上。 5) Kubelet根据scheduler发来的资源配置单运行pod,运行成功后,将pod的运行信息返回给scheduler,scheduler将返回的pod运行状况的信息存储到etcd数据中心。
删除一个Pod会发生什么事情?
Kube-apiserver会接受到用户的删除指令,默认有30秒时间等待优雅退出,超过30秒会被标记为死亡状态,此时Pod的状态Terminating,kubelet看到pod标记为Terminating就开始了关闭Pod的工作;
关闭流程如下:
- pod从service的endpoint列表中被移除;
- 如果该pod定义了一个停止前的钩子,其会在pod内部被调用,停止钩子一般定义了如何优雅的结束进程;
- 进程被发送TERM信号(kill -14)
- 当超过优雅退出的时间后,Pod中的所有进程都会被发送SIGKILL信号(kill -9)。
K8s的Service是什么?
Pod每次重启或者重新部署,其IP地址都会产生变化,这使得pod间通信和pod与外部通信变得困难,这时候,就需要Service为pod提供一个固定的入口。
Service的Endpoint列表通常绑定了一组相同配置的pod,通过负载均衡的方式把外界请求分配到多个pod上
k8s是怎么进行服务注册的?
Pod启动后会加载当前环境所有Service信息,以便不同Pod根据Service名进行通信。
k8s集群外流量怎么访问Pod?
可以通过Service的NodePort方式访问,会在所有节点监听同一个端口,比如:30000,访问节点的流量会被重定向到对应的Service上面。
k8s数据持久化的方式有哪些?
- EmptyDir(空目录):
没有指定要挂载宿主机上的某个目录,直接由Pod内保部映射到宿主机上。类似于docker中的manager volume。
主要使用场景:
- 只需要临时将数据保存在磁盘上,比如在合并/排序算法中;
- 作为两个容器的共享存储,使得第一个内容管理的容器可以将生成的数据存入其中,同时由同一个webserver容器对外提供这些页面。
emptyDir的特性: 同个pod里面的不同容器,共享同一个持久化目录,当pod节点删除时,volume的数据也会被删除。如果仅仅是容器被销毁,pod还在,则不会影响volume中的数据。 总结来说:emptyDir的数据持久化的生命周期和使用的pod一致。一般是作为临时存储使用。
- Hostpath:
将宿主机上已存在的目录或文件挂载到容器内部。类似于docker中的bind mount挂载方式。
这种数据持久化方式,运用场景不多,因为它增加了pod与节点之间的耦合。
一般对于k8s集群本身的数据持久化和docker本身的数据持久化会使用这种方式,可以自行参考apiService的yaml文件,位于:/etc/kubernetes/main…目录下。
- PersistentVolume(简称PV):
基于NFS服务的PV,也可以基于GFS的PV。它的作用是统一数据持久化目录,方便管理。
在一个PV的yaml文件中,可以对其配置PV的大小,
指定PV的访问模式:
- ReadWriteOnce:只能以读写的方式挂载到单个节点;
- ReadOnlyMany:能以只读的方式挂载到多个节点;
- ReadWriteMany:能以读写的方式挂载到多个节点。,
以及指定pv的回收策略(这里的回收策略指的是在PV被删除后,在这个PV下所存储的源文件是否删除):
- recycle:清除PV的数据,然后自动回收;
- Retain:需要手动回收;
- delete:删除云存储资源,云存储专用;
若需使用PV,那么还有一个重要的概念:PVC,PVC是向PV申请应用所需的容量大小,K8s集群中可能会有多个PV,PVC和PV若要关联,其定义的访问模式必须一致。定义的storageClassName也必须一致,若群集中存在相同的(名字、访问模式都一致)两个PV,那么PVC会选择向它所需容量接近的PV去申请,或者随机申请。
Replica Set 和 Replication Controller 之间有什么区别?
Replica Set 和 Replication Controller 几乎完全相同。它们都确保在任何给定时间运行指定数量的 Pod 副本。不同之处在于复制 Pod 使用的选择器。Replica Set 使用基于集合的选择器,而 Replication Controller 使用基于权限的选择器。
Equity-Based 选择器:这种类型的选择器允许按标签键和值进行过滤。因此,在外行术语中,基于 Equity 的选择器将仅查找与标签具有完全相同短语的 Pod。示例:假设您的标签键表示 app = nginx,那么使用此选择器,您只能查找标签应用程序等于 nginx 的那些 Pod。
Selector-Based 选择器:此类型的选择器允许根据一组值过滤键。因此,换句话说,基于 Selector 的选择器将查找已在集合中提及其标签的 Pod。示例:假设您的标签键在(nginx、NPS、Apache)中显示应用程序。然后,使用此选择器,如果您的应用程序等于任何 nginx、NPS或 Apache,则选择器将其视为真实结果。
其它
基础篇 基础篇主要面向的初级、中级开发工程师职位,主要考察对k8s本身的理解。
kubernetes包含几个组件。各个组件的功能是什么。组件之间是如何交互的。 k8s的pause容器有什么用。是否可以去掉。 k8s中的pod内几个容器之间的关系是什么。 一个经典pod的完整生命周期。 k8s的service和ep是如何关联和相互影响的。 详述kube-proxy原理,一个请求是如何经过层层转发落到某个pod上的整个过程。请求可能来自pod也可能来自外部。 rc/rs功能是怎么实现的。详述从API接收到一个创建rc/rs的请求,到最终在节点上创建pod的全过程,尽可能详细。另外,当一个pod失效时,kubernetes是如何发现并重启另一个pod的? deployment/rs有什么区别。其使用方式、使用条件和原理是什么。 cgroup中的cpu有哪几种限制方式。k8s是如何使用实现request和limit的。
拓展实践篇 拓展实践篇主要面向的高级开发工程师、架构师职位,主要考察实践经验和技术视野。
设想一个一千台物理机,上万规模的容器的kubernetes集群,请详述使用kubernetes时需要注意哪些问题?应该怎样解决?(提示可以从高可用,高性能等方向,覆盖到从镜像中心到kubernetes各个组件等) 设想kubernetes集群管理从一千台节点到五千台节点,可能会遇到什么样的瓶颈。应该如何解决。 kubernetes的运营中有哪些注意的要点。 集群发生雪崩的条件,以及预防手段。 设计一种可以替代kube-proxy的实现 sidecar的设计模式如何在k8s中进行应用。有什么意义。 灰度发布是什么。如何使用k8s现有的资源实现灰度发布。 介绍k8s实践中踩过的比较大的一个坑和解决方式。
14.3 Service Mesh
什么是Service Mesh(服务网格)?
Service Mesh是专用的基础设施层,轻量级高性能网络代理。提供安全的、快速的、可靠地服务间通讯,与实际应用部署一起,但对应用透明。
为了帮助理解, 下图展示了服务网格的典型边车部署方式:
https://www.jianshu.com/p/cc5b54ad8d5f
什么是Istio?
Istio的架构?
15 DevOps
15.1 Linux
什么是Linux?
Linux是一种基于UNIX的操作系统,最初是由Linus Torvalds引入的。它基于Linux内核,可以运行在由Intel,MIPS,HP,IBM,SPARC和Motorola制造的不同硬件平台上。Linux中另一个受欢迎的元素是它的吉祥物,一个名叫Tux的企鹅形象。
UNIX和LINUX有什么区别?
Unix最初是作为Bell Laboratories的专有操作系统开始的,后来产生了不同的商业版本。另一方面,Linux是免费的,开源的,旨在为大众提供非适当的操作系统。
什么是BASH?
BASH是Bourne Again SHell的缩写。它由Steve Bourne编写,作为原始Bourne Shell(由/ bin / sh表示)的替代品。它结合了原始版本的Bourne Shell的所有功能,以及其他功能,使其更容易使用。从那以后,它已被改编为运行Linux的大多数系统的默认shell。
什么是Linux内核?
Linux内核是一种低级系统软件,其主要作用是为用户管理硬件资源。它还用于为用户级交互提供界面。
什么是LILO?
LILO是Linux的引导加载程序。它主要用于将Linux操作系统加载到主内存中,以便它可以开始运行。
什么是交换空间?
交换空间是Linux使用的一定空间,用于临时保存一些并发运行的程序。当RAM没有足够的内存来容纳正在执行的所有程序时,就会发生这种情况。
Linux的基本组件是什么?
就像任何其他典型的操作系统一样,Linux拥有所有这些组件:内核,shell和GUI,系统实用程序和应用程序。Linux比其他操作系统更具优势的是每个方面都附带其他功能,所有代码都可以免费下载。
Linux系统安装多个桌面环境有帮助吗?
通常,一个桌面环境,如KDE或Gnome,足以在没有问题的情况下运行。尽管系统允许从一个环境切换到另一个环境,但这对用户来说都是优先考虑的问题。有些程序在一个环境中工作而在另一个环境中无法工作,因此它也可以被视为选择使用哪个环境的一个因素。
BASH和DOS之间的基本区别是什么?
BASH和DOS控制台之间的主要区别在于3个方面:
BASH命令区分大小写,而DOS命令则不区分; 在BASH下,/ character是目录分隔符,\作为转义字符。在DOS下,/用作命令参数分隔符,\是目录分隔符 DOS遵循命名文件中的约定,即8个字符的文件名后跟一个点,扩展名为3个字符。BASH没有遵循这样的惯例。
GNU项目的重要性是什么?
这种所谓的自由软件运动具有多种优势,例如可以自由地运行程序以及根据你的需要自由学习和修改程序。它还允许你将软件副本重新分发给其他人,以及自由改进软件并将其发布给公众。
描述root帐户?
root帐户就像一个系统管理员帐户,允许你完全控制系统。你可以在此处创建和维护用户帐户,为每个帐户分配不同的权限。每次安装Linux时都是默认帐户。
如何在发出命令时打开命令提示符?
要打开默认shell(可以找到命令提示符的位置),请按Ctrl-Alt-F1。这将提供命令行界面(CLI),你可以根据需要从中运行命令。
如何知道Linux使用了多少内存?
在命令shell中,使用“concatenate”命令:cat / proc / meminfo获取内存使用信息。你应该看到一行开始像Mem:64655360等。这是Linux认为它可以使用的总内存。
你也可以使用命令
free - m
vmstat
top
htop
找到当前的内存使用情况
Linux系统下交换分区的典型大小是多少?
交换分区的首选大小是系统上可用物理内存量的两倍。如果无法做到这一点,则最小大小应与安装的内存量相同。
什么是符号链接?
符号链接的行为类似于Windows中的快捷方式。这些链接指向程序,文件或目录。它还允许你即时访问它,而无需直接转到整个路径名。
Ctrl + Alt + Del组合键是否适用于Linux?
是的,它确实。就像Windows一样,你可以使用此组合键来执行系统重启。一个区别是你不会收到任何确认消息,因此,立即重启。
如何引用连接打印机等设备的并行端口?
在Windows下,你将并行端口称为LPT端口,而在Linux下,你将其称为/ dev / lp。因此,LPT1,LPT2和LPT3在Linux下称为/ dev / lp0,/ dev / lp1或/ dev / lp2。
硬盘驱动器和软盘驱动器等驱动器是否用驱动器号表示?
在Linux中,每个驱动器和设备都有不同的名称。例如,软盘驱动器称为/ dev / fd0和/ dev / fd1。IDE / EIDE硬盘驱动器称为/ dev / hda,/ dev / hdb,/ dev / hdc等。
如何在Linux下更改权限?
假设你是系统管理员或文件或目录的所有者,则可以使用chmod命令授予权限。使用+符号添加权限或 - 符号拒绝权限,以及以下任何字母:u(用户),g(组),o(其他),a(所有),r(读取),w(写入)和x(执行)。例如,命令chmod go + rw FILE1.TXT授予对文件FILE1.TXT的读写访问权限,该文件分配给组和其他组。
在Linux中,为不同的串口分配了哪些名称?
串行端口标识为/ dev / ttyS0到/ dev / ttyS7。这些是Windows中COM1到COM8的等效名称。
如何在Linux下访问分区?
Linux在驱动器标识符的末尾分配数字。例如,如果第一个IDE硬盘驱动器有三个主分区,则它们将命名/编号,/ dev / hda1,/ dev / hda2和/ dev / hda3。
什么是硬链接?
硬链接直接指向磁盘上的物理文件,而不指向路径名。这意味着如果重命名或移动原始文件,链接将不会中断,因为链接是针对文件本身的,而不是文件所在的路径。
Linux下文件名的最大长度是多少?
任何文件名最多可包含255个字符。此限制不包括路径名,因此整个路径名和文件名可能会超过255个字符。
什么是以点开头的文件名?
通常,以点开头的文件名是隐藏文件。这些文件可以是包含重要数据或设置信息的配置文件。将这些文件设置为隐藏会使其不太可能被意外删除。
解释虚拟桌面?
这可以作为最小化和最大化当前桌面上不同窗口的替代方案。当你可以打开一个或多个程序时,使用虚拟桌面可以清除桌面。你可以简单地在虚拟桌面之间进行随机播放,而不是在每个程序中保持完整的程序,而不是最小化/恢复所有这些程序。
如何在Linux下跨不同的虚拟桌面共享程序?
要在不同的虚拟桌面之间共享程序,请在程序窗口的左上角查找看起来像图钉的图标。按此按钮将“固定”该应用程序到位,使其显示在所有虚拟桌面上,位于屏幕上的相同位置。
无名(空)目录代表什么?
此空目录名称用作Linux文件系统的无名基础。这用作所有其他目录,文件,驱动器和设备的附件。
什么是pwd命令?
pwd命令是print working directory命令的缩写。
PWD
/home/guru99/myDir
什么是守护进程?
守护进程是提供基本操作系统下可能无法使用的多种功能的服务。其主要任务是监听服务请求,同时对这些请求采取行动。服务完成后,它将断开连接并等待进一步的请求。
如何从一个桌面环境切换到另一个桌面环境,例如从KDE切换到Gnome?
假设你已安装这两个环境,只需从图形界面注销即可。然后在登录屏幕上,键入你的登录ID和密码,并选择要加载的会话类型。在你将其更改为其他选项之前,此选项将保持默认状态。
Linux下的权限有哪些?
Linux下有3种权限:
- 读取:用户可以读取文件或列出目录
- 写入:用户可以写入新文件到目录的文件
- 执行:用户可以运行文件或查找特定文件一个目录
区分大小写如何影响命令的使用方式?
当我们讨论区分大小写时,只有当每个字符按原样编码时,命令才被认为是相同的,包括小写和大写字母。这意味着CD,CD和Cd是三个不同的命令。使用大写字母输入命令,它应该是小写的,将产生不同的输出。
是否可以使用快捷方式获取长路径名?
就在这里。称为文件名扩展的功能允许你使用TAB键执行此操作。例如,如果你有一个名为/ home / iceman / assignments目录的路径,则键入如下:/ ho [tab] / ice [tab] / assi [tab]。但是,这假设路径是唯一的,并且你正在使用的shell支持此功能。
什么是重定向?
重定向是将数据从一个输出定向到另一个输出的过程。它还可以用于将输出作为输入定向到另一个进程。
什么是grep命令?
grep使用基于模式的搜索的搜索命令。它使用与命令行一起指定的选项和参数,并在搜索所需的文件输出时应用此模式。
当发出的命令与上次使用时产生的结果不同时,会出现什么问题?
从看似相同的命令获得不同结果的一个非常可能的原因与区分大小写问题有关。由于Linux区分大小写,因此先前使用的命令可能以与当前格式不同的格式输入。例如,要列出目录中的所有文件,应键入命令ls,而不是LS。如果没有存在该确切名称的程序,则键入LS将导致错误消息,或者如果存在名为LS的程序执行另一个功能,则可能产生不同的输出。
/ usr / local的内容是什么?
它包含本地安装的文件。此目录在文件存储在网络上的环境中很重要。具体来说,本地安装的文件将转至/ usr / local / bin,/ usr / local / lib等。此目录的另一个应用是它用于从源安装的软件包,或未正式随分发一起提供的软件。
你如何终止正在进行的流程?
系统中的每个进程都由唯一的进程ID或pid标识。使用kill命令后跟pid来终止该进程。
要立即终止所有进程,请使用kill 0。
如何在命令行提示符中插入注释?
通过在实际注释文本之前键入#符号来创建注释。这告诉shell完全忽略后面的内容。例如“#这只是shell将忽略的注释。”
什么是命令分组以及它是如何工作的?
你可以使用括号对命令进行分组。例如,如果要将当前日期和时间以及名为OUTPUT的文件的内容发送到名为MYDATES的第二个文件,可以按如下方式应用命令分组:(date cat OUTPUT)> MYDATES
如何从单个命令行条目执行多个命令或程序?
你可以通过使用分号符号分隔每个命令或程序来组合多个命令。例如,你可以在单个条目中发出这样一系列命令:
ls –l cd .. ls –a MYWORK which is equivalent to 3 commands: ls -l cd.. ls -a MYWORK
**请注意,这将按指定的顺序依次执行。
编写一个命令,查找扩展名为“c”的文件,并在其中出现字符串“apple”?
find ./ -name "*.c" | xargs grep –i "apple"
编写一个显示所有.txt文件的命令,包括其个人权限。
ls -al * .txt
解释如何为Git控制台着色?
要为Git控制台着色,可以使用命令git config-global color.ui auto。在命令中,color.ui变量设置变量的默认值,例如color.diff和color.grep。
如何在Linux中将一个文件附加到另一个文件?
要在Linux中将一个文件附加到另一个文件,你可以使用命令cat file2 >> file 1. operator >>附加指定文件的输出或创建文件(如果未创建)。而另一个命令cat文件1文件2>文件3将两个或多个文件附加到一个文件。
解释如何使用终端找到文件?
要查找文件,你必须使用命令,查找。-name“process.txt”。它将查找名为process.txt的文件的当前目录。
解释如何使用终端创建文件夹?
要创建文件夹,你必须使用命令mkdir。它将是这样的:〜$ mkdir Guru99
解释如何使用终端查看文本文件?
要查看文本文件,请使用命令cd转到文本文件所在的特定文件夹,然后键入less filename.txt。
解释如何在Ubuntu LAMP堆栈上启用curl?
要在Ubuntu上启用curl,首先安装libcurl,完成后使用以下命令sudo /etc/init .d / apache2 restart或sudo service apache2 restart。
解释如何在Ubuntu中启用root日志记录?
启用root日志记录的命令是
#sudo sh-c'echo“greater-show-manual-login = true”>> / etc / lightdm / lightdm.conf'
如何在启动Linux服务器的同时在后台运行Linux程序?
通过使用nohup。它将停止接收NOHUP信号的进程,从而终止它,你注销了调用的程序。并在后台运行该过程。
解释如何在Linux中卸载库?
要在Linux中卸载库,可以使用命令
sudo apt-get remove library_name
15.2 Docker
什么是虚拟化技术?
在计算机技术中,虚拟化(Virtualization)是一种资源管理技术。它是将计算机的各种实体资源,如:服务器、网络、内存及存储等,予以抽象、转换后呈现出来,打破实体结构间的不可切割的障碍,使用户可以用更好的方式来利用这些资源。
虚拟化的目的是为了在同一个主机上运行多个系统或应用,从而提高系统资源的利用率,并带来降低成本、方便管理和容错容灾等好处。
- 硬件虚拟化
硬件虚拟化就是硬件物理平台本身提供了对特殊指令的截获和重定向的支持。支持虚拟化的硬件,也是一些基于硬件实现软件虚拟化技术的关键。在基于硬件实现软件虚拟化的技术中,在硬件是实现虚拟化的基础,硬件(主要是CPU)会为虚拟化软件提供支持,从而实现硬件资源的虚拟化。
- 软件虚拟化
软件虚拟化就是利用软件技术,在现有的物理平台上实现对物理平台访问的截获和模拟。在软件虚拟化技术中,有些技术不需要硬件支持,如:QEMU;而有些软件虚拟化技术,则依赖硬件支持,如:VMware、KVM。
什么是Docker?
Docker是一个开源的应用容器引擎,它让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到安装了任何 Linux 发行版本的机器上。Docker基于LXC来实现类似VM的功能,可以在更有限的硬件资源上提供给用户更多的计算资源。与同VM等虚拟化的方式不同,LXC不属于全虚拟化、部分虚拟化或半虚拟化中的任何一个分类,而是一个操作系统级虚拟化。
Docker是直接运行在宿主操作系统之上的一个容器,使用沙箱机制完全虚拟出一个完整的操作,容器之间不会有任何接口,从而让容器与宿主机之间、容器与容器之间隔离的更加彻底。每个容器会有自己的权限管理,独立的网络与存储栈,及自己的资源管理能,使同一台宿主机上可以友好的共存多个容器。
Docker借助Linux的内核特性,如:控制组(Control Group)、命名空间(Namespace)等,并直接调用操作系统的系统调用接口。从而降低每个容器的系统开销,并实现降低容器复杂度、启动快、资源占用小等特征。
Docker和虚拟机的区别?
虚拟机Virtual Machine与容器化技术(代表Docker)都是虚拟化技术,两者的区别在于虚拟化的程度不同。
- 举个例子
- 服务器:比作一个大型的仓管基地,包含场地与零散的货物——相当于各种服务器资源。
- 虚拟机技术:比作仓库,拥有独立的空间堆放各种货物或集装箱,仓库之间完全独立——仓库相当于各种系统,独立的应用系统和操作系统。
- Docker:比作集装箱,操作各种货物的打包——将各种应用程序和他们所依赖的运行环境打包成标准的容器,容器之间隔离。
- 基于一个图解释
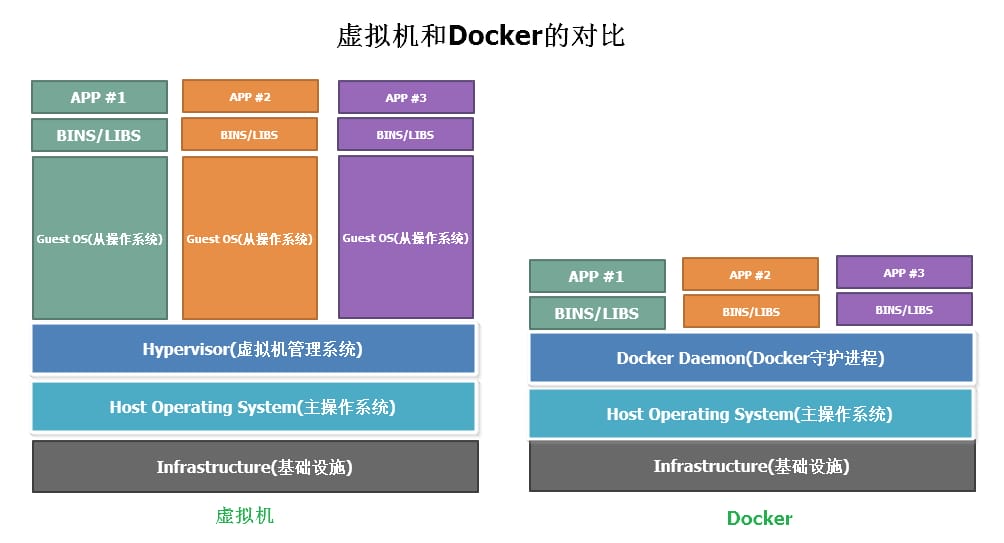
- 虚拟机管理系统(Hypervisor)。利用Hypervisor,可以在主操作系统之上运行多个不同的从操作系统。类型1的Hypervisor有支持MacOS的HyperKit,支持Windows的Hyper-V以及支持Linux的KVM。类型2的Hypervisor有VirtualBox和VMWare。
- Docker守护进程(Docker Daemon)。Docker守护进程取代了Hypervisor,它是运行在操作系统之上的后台进程,负责管理Docker容器。
- vm多了一层guest OS,虚拟机的Hypervisor会对硬件资源也进行虚拟化,而容器Docker会直接使用宿主机的硬件资源
- 基于虚拟化角度
- 隔离性 由于vm对操作系统也进行了虚拟化,隔离的更加彻底。而Docker共享宿主机的操作系统,隔离性较差。
- 运行效率 由于vm的隔离操作,导致生成虚拟机的速率大大低于容器Docker生成的速度,因为Docker直接利用宿主机的系统内核。因为虚拟机增加了一层虚拟硬件层,运行在虚拟机上的应用程序在进行数值计算时是运行在Hypervisor虚拟的CPU上的;另外一方面是由于计算程序本身的特性导致的差异。虚拟机虚拟的cpu架构不同于实际cpu架构,数值计算程序一般针对特定的cpu架构有一定的优化措施,虚拟化使这些措施作废,甚至起到反效果。
- 资源利用率 在资源利用率上虚拟机由于隔离更彻底,因此利用率也会相对较低。
Docker的架构?
Docker 使用客户端-服务器 (C/S) 架构模式,使用远程API来管理和创建Docker容器。
- Docker 客户端(Client) : Docker 客户端通过命令行或者其他工具使用 Docker SDK (https://docs.docker.com/develop/sdk/) 与 Docker 的守护进程通信。
- Docker 主机(Host) :一个物理或者虚拟的机器用于执行 Docker 守护进程和容器。
Docker 包括三个基本概念:
- 镜像(Image):Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。
- 容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
- 仓库(Repository):仓库可看着一个代码控制中心,用来保存镜像。
Docker镜像相关操作有哪些?
# 查找镜像
docker search mysql
# 拉取镜像
docker pull mysql
# 删除镜像
docker rmi hello-world
# 更新镜像
docker commit -m="update test" -a="pdai" 0a1556ca3c27 pdai/ubuntu:v1.0.1
# 生成镜像
docker build -t pdai/ubuntu:v2.0.1 .
# 镜像标签
docker tag a733d5a264b5 pdai/ubuntu:v3.0.1
# 镜像导出
docker save > pdai-ubuntu-v2.0.2.tar 57544a04cd1a
# 镜像导入
docker load < pdai-ubuntu-v2.0.2.tar
Docker容器相关操作有哪些?
# 容器查看
docker ps -a
# 容器启动
docker run -it pdai/ubuntu:v2.0.1 /bin/bash
# 容器停止
docker stop f5332ebce695
# 容器再启动
docker start f5332ebce695
# 容器重启
docker restart f5332ebce695
# 容器导出
docker export f5332ebce695 > ubuntu-pdai-v2.tar
# 容器导入
docker import ubuntu-pdai-v2.tar pdai/ubuntu:v2.0.2
# 容器强制停止并删除
docker rm -f f5332ebce695
# 容器清理
docker container prune
# 容器别名操作
docker run -itd --name pdai-ubuntu-202 pdai/ubuntu:v2.0.2 /bin/bash
如何查看Docker容器的日志?
#例:实时查看docker容器名为user-uat的最后10行日志
docker logs -f -t --tail 10 user-uat
#例:查看指定时间后的日志,只显示最后100行:
docker logs -f -t --since="2018-02-08" --tail=100 user-uat
#例:查看最近30分钟的日志:
docker logs --since 30m user-uat
#例:查看某时间之后的日志:
docker logs -t --since="2018-02-08T13:23:37" user-uat
#例:查看某时间段日志:
docker logs -t --since="2018-02-08T13:23:37" --until "2018-02-09T12:23:37" user-uat
#例:将错误日志写入文件:
docker logs -f -t --since="2018-02-18" user-uat | grep error >> logs_error.txt
如何启动Docker容器?参数含义?
[root@pdai docker-test]# docker run -itd pdai/ubuntu:v2.0.1 /bin/bash
-it可以连写的,表示-i -t-t: 在新容器内指定一个伪终端或终端。-i: 允许你对容器内的标准输入 (STDIN) 进行交互-d: 后台模式
如何进入Docker后台模式?有什么区别?
- 第一种:
docker attach
[root@pdai ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f5332ebce695 pdai/ubuntu:v2.0.1 "/bin/bash" 38 minutes ago Up 2 seconds 22/tcp, 80/tcp jolly_kepler
[root@pdai ~]# docker attach f5332ebce695
root@f5332ebce695:/# echo 'pdai'
pdai
root@f5332ebce695:/# exit
exit
[root@pdai ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
看到没,使用docker attach进入后,exit便容器也停止了。
- 第二种:
docker exec
[root@pdai ~]# docker exec -it f5332ebce695 /bin/bash
Error response from daemon: Container f5332ebce69520fba353f035ccddd4bd42055fbd1e595f916ba7233e26476464 is not running
[root@pdai ~]# docker restart f5332ebce695
f5332ebce695
[root@pdai ~]# docker exec -it f5332ebce695 /bin/bash
root@f5332ebce695:/# exit
exit
[root@pdai ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f5332ebce695 pdai/ubuntu:v2.0.1 "/bin/bash" 42 minutes ago Up 8 seconds 22/tcp, 80/tcp jolly_kepler
注意:
- 我特意在容器停止状态下执行了
docker exec,是让你看到docker exec是在容器启动状态下用的,且注意下错误信息; - 推荐大家使用
docker exec命令,因为此退出容器终端,不会导致容器的停止。
15.3 CI/CD
什么是CI?
CI的英文名称是Continuous Integration,中文翻译为:持续集成。
CI中,开发人员将会频繁地向主干提交代码,这些新提交的代码在最终合并到主干前,需要经过编译和自动化测试流进行验证。 持续集成(CI)是在源代码变更后自动检测、拉取、构建和(在大多数情况下)进行单元测试的过程。持续集成的目标是快速确保开发人员新提交的变更是好的,并且适合在代码库中进一步使用。CI的流程执行和理论实践让我们可以确定新代码和原有代码能否正确地集成在一起。
通俗点讲就是:通过持续集成, 开发人员能够在任何时候多次向仓库提交作品,而不是独立地开发每个功能模块并在开发周期结束时一一提交。这里的一个重要思想就是让开发人员更快更、频繁地做到这一点,从而降低集成的开销。 实际情况中,开发人员在集成时经常会发现新代码和已有代码存在冲突。 如果集成较早并更加频繁,那么冲突将更容易解决且执行成本更低。当然,这里也有一些权衡,这个流程不提供额外的质量保障。 事实上,许多组织发现这样的集成方式开销更大,因为它们依赖人工确保新代码不会引起新的 bug 或者破坏现有代码。 为了减少集成期间的摩擦,持续集成依赖于测试套件和自动化测试。 然而,要认识到自动化测试和持续测试是完全不同的这一点很重要。
CI 的目标是将集成简化成一个简单、易于重复的日常开发任务, 这样有助于降低总体的构建成本并在开发周期的早期发现缺陷。 要想有效地使用 CI 必须转变开发团队的习惯,要鼓励频繁迭代构建, 并且在发现 bug 的早期积极解决。
什么是CD?
这里的CD可对应多个英文名称,持续交付Continuous Delivery和持续部署Continuous Deployment。下面我们分别来看看上面是持续交付和持续部署。
- 持续交付
持续交付(CD)实际上是 CI 的扩展,其中软件交付流程进一步自动化,以便随时轻松地部署到生成环境中。 成熟的持续交付方案也展示了一个始终可部署的代码库。使用 CD 后,软件发布将成为一个没有任何紧张感的例行事件。 开发团队可以在日常开发的任何时间进行产品级的发布,而不需要详细的发布方案或者特殊的后期测试。
完成 CI 中构建及单元测试和集成测试的自动化流程后,持续交付可自动将已验证的代码发布到存储库。为了实现高效的持续交付流程,务必要确保 CI 已内置于开发管道。持续交付的目标是拥有一个可随时部署到生产环境的代码库。
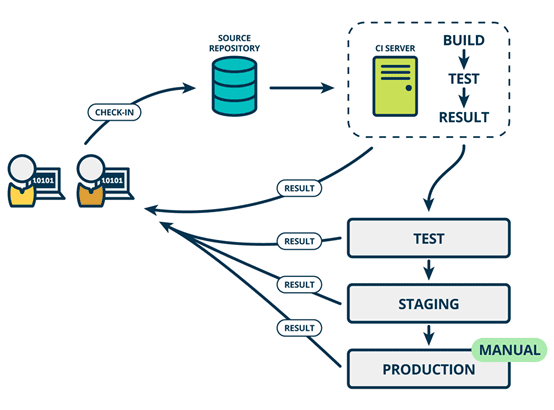
在持续交付中,每个阶段(从代码更改的合并,到生产就绪型构建版本的交付)都涉及测试自动化和代码发布自动化。在流程结束时,运维团队可以快速、轻松地将应用部署到生产环境中或发布给最终使用的用户。
CD 集中依赖于部署流水线,团队通过流水线自动化测试和部署过程。此流水线是一个自动化系统, 可以针对构建执行一组渐进的测试套件。CD 具有高度的自动化,并且在一些云计算环境中也易于配置。在流水线的每个阶段,如果构建无法通过关键测试会向团队发出警报。否则,将继续进入下一个测试, 并在连续通过测试后自动进入下一个阶段。流水线的最后一个部分会将构建部署到和生产环境等效的环境中。 这是一个整体的过程,因为构建、部署和环境都是一起执行和测试的,它能让构建在实际的生产环境可部署和可验证。
- 持续部署
持续部署扩展了持续交付,以便软件构建在通过所有测试时自动部署。在这样的流程中, 不需要人为决定何时及如何投入生产环境。CI/CD 系统的最后一步将在构建后的组件/包退出流水线时自动部署。 此类自动部署可以配置为快速向客户分发组件、功能模块或修复补丁,并准确说明当前提供的内容。采用持续部署的组织可以将新功能快速传递给用户,得到用户对于新版本的快速反馈,并且可以迅速处理任何明显的缺陷。 用户对无用或者误解需求的功能的快速反馈有助于团队规划投入,避免将精力集中于不容易产生回报的地方。
随着 DevOps 的发展,新的用来实现 CI/CD 流水线的自动化工具也在不断涌现。这些工具通常能与各种开发工具配合, 包括像 GitHub 这样的代码仓库和 Jira 这样的 bug 跟踪工具。此外,随着 SaaS 这种交付方式变得更受欢迎, 许多工具都可以在现代开发人员运行应用程序的云环境中运行,例如 GCP 和 AWS。但是对于一个成熟的CI/CD管道(Pipeline)来说,最后的阶段是持续部署。作为持续交付——自动将生产就绪型构建版本发布到代码存储库——的延伸,持续部署可以自动将应用发布到生产环境。
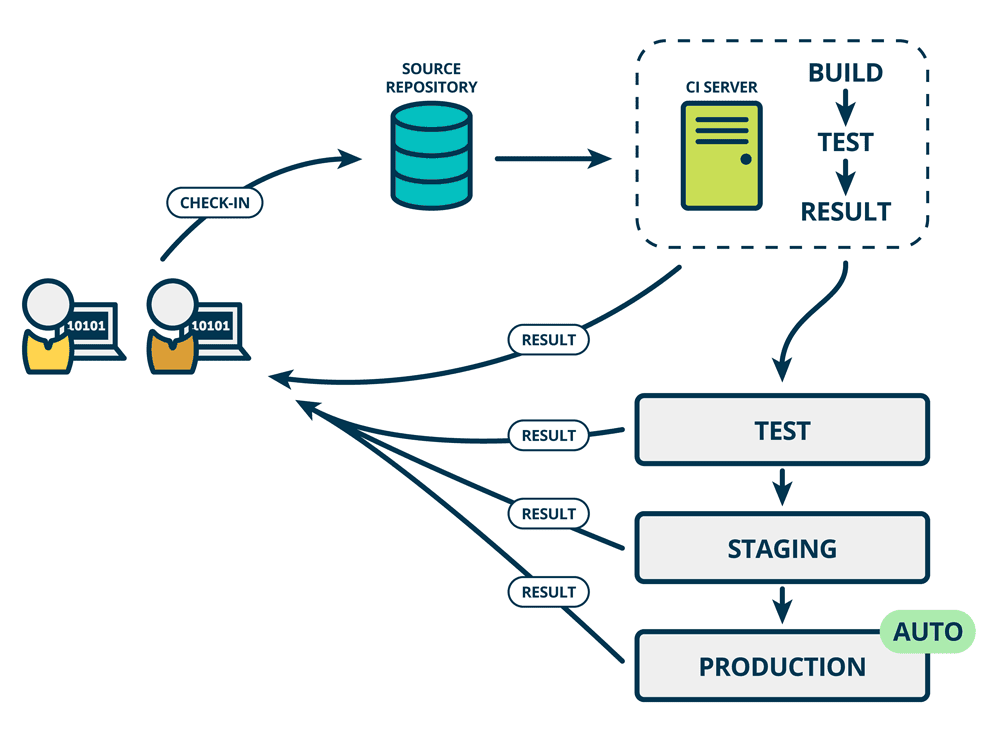
什么是CI/CD的管道?
CI / CD管道是与自动化工具和改进的工作流程集成的部署管道。 如果执行得当,它将最大程度地减少人为错误,并增强整个SDLC的反馈循环,使团队可以在更短的时间内交付较小的发行版。

典型的CI / CD管道必须包括以下阶段:
- 构建阶段
- 测试阶段
- 部署阶段
- 自动化测试阶段
- 部署到生产
如何理解DevOPS?
DevOps是Development和Operations的组合,是一种方法论,是一组过程、方法与系统的统称,用于促进应用开发、应用运维和质量保障(QA)部门之间的沟通、协作与整合。以期打破传统开发和运营之间的壁垒和鸿沟。
CI、CD和DevOps之间的关系 :
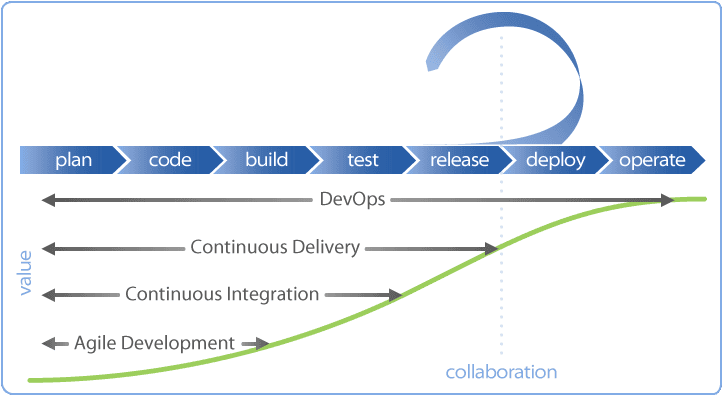
在完全部署到所有用户之前,有哪些方法可以测试部署?
由于必须回滚/撤消对所有用户的部署可能是一种代价高昂的情况(无论是技术上还是用户的感知),已经有许多技术允许“尝试”部署新功能并在发现问题时轻松“撤消”它们。这些包括:
- 蓝/绿测试/部署
在这种部署软件的方法中,维护了两个相同的主机环境 —— 一个“蓝色” 和一个“绿色”。(颜色并不重要,仅作为标识。)对应来说,其中一个是“生产环境”,另一个是“预发布环境”。
在这些实例的前面是调度系统,它们充当产品或应用程序的客户“网关”。通过将调度系统指向蓝色或绿色实例,可以将客户流量引流到期望的部署环境。通过这种方式,切换指向哪个部署实例(蓝色或绿色)对用户来说是快速,简单和透明的。
当新版本准备好进行测试时,可以将其部署到非生产环境中。在经过测试和批准后,可以更改调度系统设置以将传入的线上流量指向它(因此它将成为新的生产站点)。现在,曾作为生产环境实例可供下一次候选发布使用。
同理,如果在最新部署中发现问题并且之前的生产实例仍然可用,则简单的更改可以将客户流量引流回到之前的生产实例 —— 有效地将问题实例“下线”并且回滚到以前的版本。然后有问题的新实例可以在其它区域中修复。
- 金丝雀测试/部署
在某些情况下,通过蓝/绿发布切换整个部署可能不可行或不是期望的那样。另一种方法是为金丝雀测试/部署。在这种模型中,一部分客户流量被重新引流到新的版本部署中。例如,新版本的搜索服务可以与当前服务的生产版本一起部署。然后,可以将 10% 的搜索查询引流到新版本,以在生产环境中对其进行测试。
如果服务那些流量的新版本没问题,那么可能会有更多的流量会被逐渐引流过去。如果仍然没有问题出现,那么随着时间的推移,可以对新版本增量部署,直到 100% 的流量都调度到新版本。这有效地“更替”了以前版本的服务,并让新版本对所有客户生效。
- 功能开关
对于可能需要轻松关掉的新功能(如果发现问题),开发人员可以添加功能开关。这是代码中的 if-then 软件功能开关,仅在设置数据值时才激活新代码。此数据值可以是全局可访问的位置,部署的应用程序将检查该位置是否应执行新代码。如果设置了数据值,则执行代码;如果没有,则不执行。
这为开发人员提供了一个远程“终止开关”,以便在部署到生产环境后发现问题时关闭新功能。
- 暗箱发布
在暗箱发布中,代码被逐步测试/部署到生产环境中,但是用户不会看到更改(因此名称中有暗箱一词)。例如,在生产版本中,网页查询的某些部分可能会重定向到查询新数据源的服务。开发人员可收集此信息进行分析,而不会将有关接口,事务或结果的任何信息暴露给用户。
这个想法是想获取候选版本在生产环境负载下如何执行的真实信息,而不会影响用户或改变他们的经验。随着时间的推移,可以调度更多负载,直到遇到问题或认为新功能已准备好供所有人使用。实际上功能开关标志可用于这种暗箱发布机制。
什么是持续测试?
持续测试是一个过程,它将自动化测试作为软件交付通道中内嵌的一部分,以尽快获得软件发布后业务风险的反馈。
持续测试与自动化测试的侧重点?
- 自动化测试旨在生成一组与用户故事或应用程序要求相关的通过/失败的数据点。
- 持续测试侧重于业务风险,并提供有关软件是否可以发布的判断。要实现这一转变,我们需要停止询问“我们是否已完成测试?”而是集中精力在“发布版本是否具有可接受的业务风险级别?”
为什么我们需要持续测试?
今天,整个行业的变化要求测试更多,同时使自动化测试更难实现(至少使用传统工具和方法):
- 应用程序体系结构越来越分散和复杂,包含云,API,微服务等,并在单个业务事务中创建几乎无限的不同协议和技术组合。
- 由于Agile,DevOps和持续交付,许多应用程序现在每两周发布一次,每天发布数千次。因此,可用于测试设计,维护和特别是执行的时间大大减少。
既然软件是业务的主要接口,那么应用程序故障就是业务失败, 如果它影响用户体验,即使是看似微不足道的小故障也会产生严重后果。因此,与应用相关的风险已成为即使是非技术性商业领袖的主要关注点。
如何做版本管理?
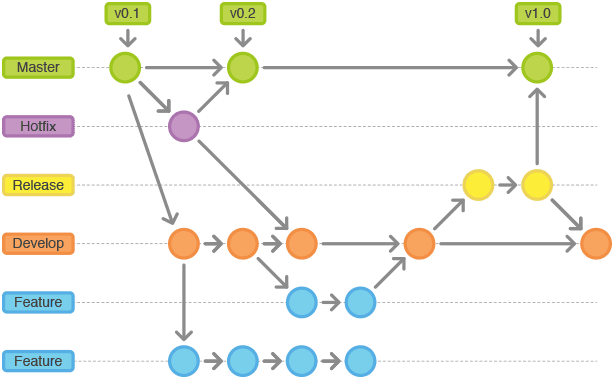
- Master 分支 主分支,这个分支最近发布到生产环境的代码,最近发布的Release, 这个分支只能从其他分支合并,不能在这个分支直接修改
- Develop 分支 这个分支是我们是我们的主开发分支,包含所有要发布到下一个Release的代码,这个主要合并与其他分支,比如Feature分支
- Feature 分支 这个分支主要是用来开发一个新的功能,一旦开发完成,我们合并回Develop分支进入下一个Release
- Release 分支 当你需要发布一个新Release的时候,我们基于Develop分支创建一个Release分支,完成Release后,我们合并到Master和Develop分支
- Hotfix 分支 当我们在Production发现新的Bug时候,我们需要创建一个Hotfix, 完成Hotfix后,我们合并回Master和Develop分支,所以Hotfix的改动会进入下一个Release
15.4 监控体系
为什么要有监控系统? 谈谈你对监控的理解?
监控的目标?
- 发现问题:当系统发生故障报警,我们会收到故障报警的信息。
- 定位问题:故障邮件一般都会写某某主机故障、具体故障的内容,我们需要对报警内容进行分析。比如一台服务器连不上,我们就需要考虑是网络问题、还是负载太高导致长时间无法连接,又或者某开发触发了防火墙禁止的相关策略等,我们就需要去分析故障具体原因。
- 解决问题:当然我们了解到故障的原因后,就需要通过故障解决的优先级去解决该故障。
- 总结问题:当我们解决完重大故障后,需要对故障原因以及防范进行总结归纳,避免以后重复出现。
具体而言?
- 对系统不间断的实时监控:实际上是对系统不间断的实时监控(这就是监控);
- 实时反馈系统当前状态:我们监控某个硬件、或者某个系统,都是需要能实时看到当前系统的状态,是正常、异常、或者故障。
- 保证服务可靠性安全性:我们监控的目的就是要保证系统、服务、业务正常运行
- 保证业务持续稳定运行:如果我们的监控做得很完善,即使出现故障,能第一时间接收到故障报警,在第一时间处理解决,从而保证业务持续性的稳定运行。
监控体系监控哪些内容?
1、硬件监控 通过SNMP来进行路由器交换机的监控(这些可以跟一些厂商沟通来了解如何做)、服务器的温度以及其它,可以通过IPMI来实现。当然如果没有硬件全都是云,直接跳过这一步骤。
2、系统监控 如CPU的负载,上下文切换、内存使用率、磁盘读写、磁盘使用率、磁盘inode使用率。当然这些都是需要配置触发器,因为默认太低会频繁报警。
3、服务监控 比如公司用的LNMP架构,Nginx自带Status模块、PHP也有相关的Status、MySQL的话可以通过Percona官方工具来进行监控。Redis这些通过自身的info获取信息进行过滤等。方法都类似。要么服务自带。要么通过脚本来实现想监控的内容,以及报警和图形功能。
4、网络监控 如果是云主机又不是跨机房,那么可以选择不监控网络。当然你说我们是跨机房以及如何如何,推荐使用smokeping来做网络相关的监控,或者直接交给你们的网络工程师来做,因为术业有专攻。
5、安全监控 如果是云主机可以考虑使用自带的安全防护。当然也可以使用iptables。如果是硬件,那么推荐使用硬件防火墙。使用云可以购买防DDOS,避免出现故障导致down机一天。如果是系统,那么权限、密码、备份、恢复等基础方案要做好。Web同时也可以使用Nginx+Lua来实现一个Web层面的防火墙。当然也可以使用集成好的OpenResty。
6、Web监控 Web监控的话题其实还是很多。比如可以使用自带的Web监控来监控页面相关的延迟、js响应时间、下载时间、等等。这里我推荐使用专业的商业软件监控宝或听云来实现。毕竟人家全国各地都有机房(如果本身是多机房那就另说了)。
7、日志监控 如果是Web的话可以使用监控Nginx的50x、40x的错误日志,PHP的ERROR日志。其实这些需求无非是,收集、存储、查询、展示,我们其实可以使用开源的ELKStack来实现。Logstash(收集)、Elasticsearch(存储+搜索)、Kibana(展示)。
8、业务监控 上面做了那么多,其实最终还是保证业务的运行。这样我们做的监控才有意义。所以业务层面这块的监控需要和开发以及总监开会讨论,监控比较重要的业务指标,(需要开会确认)然后通过简单的脚本就可以实现,最后设置触发器即可 。
9、流量分析 平时我们分析日志都是拿awk sed xxx一堆工具来实现。这样对我们统计IP、PV、UV不是很方便。那么可以使用百度统计、Google统计、商业,让开发嵌入代码即可。为了避免隐私也可以使用Piwik来做相关的流量分析。
10、可视化 通过Screen以及引入一些第三方的库来美化界面,同时我们也需要知道,订单量突然增加、突然减少。或者说突然来了一大波流量,这流量从哪儿来,是不是推广了,还是被攻击了。可以结合监控平来梳理各个系统之间的业务关系。
11、自动化监控 如上我们做了那么多的工作,当然不能是一台一台的来加key实现。可以通过Zabbix的主动模式以及被动模式来实现。当然最好还是通过API来实现。
监控一般采用什么样的流程?
- 采集 通过SNMP、Agent、ICMP、SSH、IPMI等对系统进行数据采集
- 存储 各类数据库服务,MySQL、PostgreSQL, 时序库等
- 分析 提供图形及时间线情况信息,方便我们定位故障所在
- 展示 指标信息、指标趋势展示
- 报警 电话、邮件、微信、短信、报警升级机制
- 处理 故障级别判定,找响应人员进行快速处理
16 其它
16.1 设计模式
16.2 开源协议
说说常见的开源协议?
最流行的六种:MIT、Apache、BSD、GPL和LGPL、Mozilla。
GPL协议、LGPL协议与BSD协议的法律区别?
简而言之,GPL协议就是一个开放源代码协议,软件的初始开发者使用了GPL协议并公开软件的源程序后,后续使用该软件源程序开发软件者亦应当根据GPL协议把自己编写的源程序进行公开。GPL协议要求的关键在于开放源程序,但并不排斥软件作者向用户收费。虽然如此,很多大公司对GPL协议还是又爱又恨,爱的是这个协议项下的软件历经众多程序员千锤百炼的修改,已经非常成熟完善,恨的是必须开放自己后续的源程序,导致竞争对手也可以根据自己修改的源程序开发竞争产品。
正因大公司对GPL协议在商业上存在顾虑,因此,另两种协议被采用的更多,第一种是LGPL(亦称GPL V2)协议,可以翻译为更宽松的GPL协议。与GPL协议的区别为,后者如果只是对LGPL软件的程序库的程序进行调用而不是包含其源代码时,相关的源程序无需开源。调用和包含的区别类似在互联网网网页上对他人网页内容的引用: 如果把他人的内容全部或部分复制到自己的网页上,就类似包含,如果只是贴一个他人网页的网址链接而不引用内容,就类似调用。有了这个协议,很多大公司就可以把很多自己后续开发内容的源程序隐藏起来。
第二种是BSD协议(类似的还有MIT协议)。BSD协议鼓励软件的作者公开自己后续开发的源代码,但不强求。在BSD协议项下开发的软件,原始的源程序是开放源代码的,但使用者修改以后,可以自行选择发布源程序或者二进制程序(即目标程序),当然,使用者有义务把自己原来使用的源程序与BSD协议在软件对外发布时一并发布。因为比较灵活,所以BSD深受大公司的欢迎。
MongoDB修改开源协议?
2018年10月,MongoDB宣布其开源许可证将从GNU AGPLv3,切换到SSPL,新许可证将适用于新版本的MongoDB Community Server以及打过补丁的旧版本。
根据 MongoDB 之前的 GNU AGPLv3 协议,想要将 MongoDB 作为公共服务运行的公司必须将他们的软件开源,或需要从 MongoDB 获得商业许可,”该公司解释说,“然而,MongoDB 的普及使一些组织在违反 GNU AGPLv3 协议的边缘疯狂试探,甚至直接违反了协议。”
尽管 SSPL 与 GNU AGPLv3 没有什么不同,但 SSPL 会明确要求托管 MongoDB 实例的云计算公司要么从 MongoDB 获取商业许可证,要么向社区开源其服务代码。
随后Red Hat宣布,将不会在Red Hat Enterprise Linux或Fedora中使用MongoDB。事实上,MongoDB修改开源协议之后,Red Hat并不是首家弃用的Linux社区。2018年12月5日,Linux发行版Debian在邮件列表中讨论并决定不使用SSPL协议下的软件。2019年1月,Fedora Legal也对SSPL v1协议做出了相关决定,Fedora已确定服务器端公共许可证v1(SSPL)不是自由软件许可证。
16.3 软件理论
什么是CAP理论?
CAP原理指的是,在分布式系统中这三个要素最多只能同时实现两点,不可能三者兼顾。因此在进行分布式架构设计时,必须做出取舍。而对于分布式数据系统,分区容忍性是基本要求,否则就失去了价值。因此设计分布式数据系统,就是在一致性和可用性之间取一个平衡。对于大多数Web应用,其实并不需要强一致性,因此牺牲一致性而换取高可用性,是目前多数分布式数据库产品的方向。
- 一致性(Consistency):数据在多个副本之间是否能够保持一致的特性。(当一个系统在一致状态下更新后,应保持系统中所有数据仍处于一致的状态)
- 可用性(Availability):系统提供的服务必须一直处于可用状态,对每一个操作的请求必须在有限时间内返回结果。
- 分区容错性(Tolerance of network Partition):分布式系统在遇到网络分区故障时,仍然需要保证对外提供一致性和可用性的服务,除非整个网络都发生故障。
为什么只能同时满足两个?
例如,服务器中原本存储的value=0,当客户端A修改value=1时,为了保证数据的一致性,要写到3个服务器中,当服务器C故障时,数据无法写入服务器C,则导致了此时服务器A、B和C的value是不一致的。这时候要保证分区容错性,即当服务器C故障时,仍然能保持良好的一致性和可用性服务,则Consistency和Availability不能同时满足。为什么呢?
如果满足了一致性,则客户端A的写操作value=1不能成功,这时服务器中所有value=0。 如果满足可用性,即所有客户端都可以提交操作并得到返回的结果,则此时允许客户端A写入服务器A和B,客户端C将得到未修改之前的value=0结果。
什么是BASE理论?
- Basically Available(基本可用)分布式系统在出现不可预知故障的时候,允许损失部分可用性
- Soft state(软状态)软状态也称为弱状态,和硬状态相对,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
- Eventually consistent(最终一致性)最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性
CAP 与 BASE 关系?
BASE是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的结论,是基于CAP定理逐步演化而来的,其核心思想是即使无法做到强一致性(Strong consistency),更具体地说,是对 CAP 中 AP 方案的一个补充。其基本思路就是:通过业务,牺牲强一致性而获得可用性,并允许数据在一段时间内是不一致的,但是最终达到一致性状态。
CAP 与 ACID 关系?
ACID 是传统数据库常用的设计理念,追求强一致性模型。BASE 支持的是大型分布式系统,提出通过牺牲强一致性获得高可用性。
ACID 和 BASE 代表了两种截然相反的设计哲学,在分布式系统设计的场景中,系统组件对一致性要求是不同的,因此 ACID 和 BASE 又会结合使用。
什么是SOLID原则?
- S单一职责SRP Single-Responsibility Principle
一个类,最好只做一件事,只有一个引起它的变化。单一职责原则可以看做是低耦合,高内聚在面向对象原则的引申,将职责定义为引起变化的原因,以提高内聚性减少引起变化的原因。
比如: SpringMVC 中Entity,DAO,Service,Controller, Util等的分离。
- O开放封闭原则OCP Open - Closed Principle
对扩展开放,对修改关闭(设计模式的核心原则)
比如: 设计模式中模板方法模式和观察者模式都是开闭原则的极好体现
- L里氏替换原则LSP Liskov Substitution Principle
任何基类可以出现的地方,子类也可以出现;这一思想表现为对继承机制的约束规范,只有子类能够替换其基类时,才能够保证系统在运行期内识别子类,这是保证继承复用的基础。
比如:正方形是长方形是理解里氏代换原则的经典例子。(讲的是基类和子类的关系,只有这种关系存在时,里氏代换原则才存在)
- I接口隔离法则ISL Interface Segregation Principle
客户端不应该依赖那些它不需要的接口。(接口隔离原则是指使用多个专门的接口,而不使用单一的总接口; 这个法则与迪米特法则是相通的)
- D依赖倒置原则DIP Dependency-Inversion Principle
要依赖抽象,而不要依赖具体的实现, 具体而言就是高层模块不依赖于底层模块,二者共同依赖于抽象。抽象不依赖于具体, 具体依赖于抽象。
什么是合成/聚合复用原则?
Composite/Aggregate ReusePrinciple ,CARP: 要尽量使用对象组合,而不是继承关系达到软件复用的目的。
组合/聚合可以使系统更加灵活,类与类之间的耦合度降低,一个类的变化对其他类造成的影响相对较少,因此一般首选使用组合/聚合来实现复用;其次才考虑继承,在使用继承时,需要严格遵循里氏代换原则,有效使用继承会有助于对问题的理解,降低复杂度,而滥用继承反而会增加系统构建和维护的难度以及系统的复杂度,因此需要慎重使用继承复用。
此原则和里氏代换原则氏相辅相成的,两者都是具体实现"开-闭"原则的规范。违反这一原则,就无法实现"开-闭"原则。
什么是迪米特法则?
Law of Demeter,LoD: 系统中的类,尽量不要与其他类互相作用,减少类之间的耦合度.
又叫最少知识原则(Least Knowledge Principle或简写为LKP).
- 不要和“陌生人”说话。英文定义为: Don't talk to strangers.
- 只与你的直接朋友通信。英文定义为: Talk only to your immediate friends.
比如:外观模式Facade(结构型)
什么是康威定律?
康威在一篇文章中描述: 设计系统的组织,其产生的设计等同于组织之内、组织之间的沟通结构。
- 定律一: 组织沟通方式会通过系统设计表达出来,就是说架构的布局和组织结构会有相似。
- 定律二: 时间再多一件事情也不可能做的完美,但总有时间做完一件事情。一口气吃不成胖子,先搞定能搞定的。
- 定律三: 线型系统和线型组织架构间有潜在的异质同态特性。种瓜得瓜,做独立自治的子系统减少沟通成本。
- 定律四: 大的系统组织总是比小系统更倾向于分解。合久必分,分而治之。
16.4 软件成熟度模型
什么是CMM?
由美国卡内基梅隆大学的软件工程研究所(SEI)创立的CMM(Capability Maturity Model 软件能力成熟度模型)认证评估,在过去的十几年中,对全球的软件产业产生了非常深远的影响。CMM共有五个等级,分别标志着软件企业能力成熟度的五个层次。从低到高,软件开发生产计划精度逐级升高,单位工程生产周期逐级缩短,单位工程成本逐级降低。据SEI统计,通过评估的软件公司对项目的估计与控制能力约提升40%到50%;生产率提高10%到20%,软件产品出错率下降超过1/3。
对一个软件企业来说,达到CMM2就基本上进入了规模开发,基本具备了一个现代化软件企业的基本架构和方法,具备了承接外包项目的能力。CMM3评估则需要对大软件集成的把握,包括整体架构的整合。一般来说,通过CMM认证的级别越高,其越容易获得用户的信任,在国内、国际市场上的竞争力也就越强。因此,是否能够通过CMM认证也成为国际上衡量软件企业工程开发能力的一个重要标志。
CMM是目前世界公认的软件产品进入国际市场的通行证,它不仅仅是对产品质量的认证,更是一种软件过程改善的途径。参与CMM评估的博科负责人表示,通过CMM的评估认证不是目标,它只是推动软件企业在产品的研发、生产、服务和管理上不断成熟和进步的手段,是一种持续提升和完善企业自身能力的过程。此次由美国PIA咨询公司负责评估并最终通过CMM3认证,标志着博科在质量管理的能力已经上升到一个新的高度。
什么是CMMI5 呢?
CMMI全称是Capability Maturity Model Integration, 即软件能力成熟度模型集成模型,是由美国国防部与卡内基-梅隆大学和美国国防工业协会共同开发和研制的。CMMI是一套融合多学科的、可扩充的产品集合, 其研制的初步动机是为了利用两个或多个单一学科的模型实现一个组织的集成化过程改进
CMMI分为五个等级,二十五个过程区域(PA)。
1. 初始级 软件过程是无序的,有时甚至是混乱的,对过程几乎没有定义,成功取决于个人努力。管理是反应式的。
2. 已管理级 建立了基本的项目管理过程来跟踪费用、进度和功能特性。制定了必要的过程纪律,能重复早先类似应用项目取得的成功经验。
3. 已定义级 已将软件管理和工程两方面的过程文档化、标准化,并综合成该组织的标准软件过程。所有项目均使用经批准、剪裁的标准软件过程来开发和维护软件,软件产品的生产在整个软件过程是可见的。
4. 量化管理级 分析对软件过程和产品质量的详细度量数据,对软件过程和产品都有定量的理解与控制。管理有一个作出结论的客观依据,管理能够在定量的范围内预测性能。
5. 优化管理级 过程的量化反馈和先进的新思想、新技术促使过程持续不断改进。
每个等级都被分解为过程域,特殊目标和特殊实践,通用目标、通用实践和共同特性:
每个等级都有几个过程区域组成,这几个过程域共同形成一种软件过程能力。每个过程域,都有一些特殊目标和通用目标,通过相应的特殊实践和通用实践来实现这些目标。当一个过程域的所有特殊实践和通用实践都按要求得到实施,就能实现该过程域的目标。
CMMI与CMM的区别呢?
CMM是指“能力成熟度模型”,其英文全称为Capability Maturity Model for Software;
CMMI 是指“能力成熟度模型集成”,全称为:Capability Maturity Model Integration;
CMMI是系统工程和软件工程的集成成熟度模型,CMMI更适合于信息系统集成企业。CMMI是在CMM基础上发展起来的,它继承并发扬了CMM的优良特性,借鉴了其他模型的优点,融入了新的理论和实际研究成果。它不仅能够应用在软件工程领域,而且可以用于系统工程及其他工程领域。
CMM与ISO9000的主要区别?
1.CMM是专门针对软件产品开发和服务的,而ISO9000涉及的范围则相当宽。
2.CMM强调软件开发过程的成熟度,即过程的不断改进和提高。而ISO9000则强调可接收的质量体系的最低标准。
16.5 等级保护
为什么是做等级保护?
- 法律法规要求
《网络安全法》明确规定信息系统运营、使用单位应当按照网络安全等级保护制度要求,履行安全保护义务,如果拒不履行,将会受到相应处罚。
第二十一条:国家实行网络安全等级保护制度。网络运营者应当按照网络安全等级保护制度的要求,履行下列安全保护义务,保障网络免受干扰、破坏或者未经授权的访问,防止网络数据泄露或者被窃取、篡改。
- 行业要求
在金融、电力、广电、医疗、教育等行业,主管单位明确要求从业机构的信息系统(APP)要开展等级保护工作。
- 企业系统安全的需求
信息系统运营、使用单位通过开展等级保护工作可以发现系统内部的安全隐患与不足之处,可通过安全整改提升系统的安全防护能力,降低被攻击的风险。
简单来说,《网络安全法》一直对网站、信息系统、APP有等级保护要求,中小型企业通常是行业要求才意识到问题。
等级保护分为哪些等级?
- 第一级 自主保护级:
(无需备案,对测评周期无要求)此类信息系统受到破坏后,会对公民、法人和其他组织的合法权益造成一般损害,不损害国家安全、社会秩序和公共利益。
- 第二级 指导保护级:
(公安部门备案,建议两年测评一次)此类信息系统受到破坏后,会对公民、法人和其他组织的合法权益造成严重损害。会对社会秩序、公共利益造成一般损害,不损害国家安全。
- 第三级 监督保护级:
(公安部门备案,要求每年测评一次)此类信息系统受到破坏后,会对国家安全、社会秩序造成损害,对公共利益造成严重损害,对公民、法人和其他组织的合法权益造成特别严重的损害。
- 第四级 强制保护级:
(公安部门备案,要求半年一次)此类信息系统受到破坏后,会对国家安全造成严重损害,对社会秩序、公共利益造成特别严重损害。
- 第五级 专控保护级:
(公安部门备案,依据特殊安全需求进行)此类信息系统受到破坏后会对国家安全造成特别严重损害。
怎么做等级保护?
- 等级保护通常需要5个步骤:
- 定级(企业自主定级-专家评审-主管部门审核-公安机关审核)
- 备案(企业提交备案材料-公安机关审核-发放备案证明)
- 测评(等级测评-三级每年测评一次)
- 建设整改(安全建设-安全整改)
- 监督检查(公安机关每年监督检查)
- 企业自己如何做等级保护?
在定级备案的步骤,一级不需要备案仅需企业自主定级。二级、三级是大部分普通企业的信息系统定级。四级、五级普通企业不会涉及,通常是与国家相关(如等保四级-涉及民生的,如铁路、能源、电力等)的重要系统。根据地区不同备案文件修改递交通常需要1个月左右的时间。
定级备案后,寻找本地区测评机构进行等级测评。
根据测评评分(GBT22239-2019信息安全技术网络安全等级保护基本要求。具体分数需要测评后才能给出)对信息系统(APP)进行安全整改,如果企业没有专业的安全团队,需要寻找安全公司进行不同项目的整改。等级保护2.0三级有211项内容,通常企业需要根据自身情况采购安全产品完成整改。
进行安全建设整改后,通过测评。当地公安机关会进行监督检查包含定级备案测评、测评后抽查。
整个流程企业自行做等级保护,顺利的话3-4个月完成,如果不熟悉需要半年甚至更久。
等保三的基本要求?
说说等级保护三级的技术要求,主要包含五个部门
- 物理安全
保证物理的安全,比如物理位置,机房的访问安全;涉及访问控制,防火防盗防雷防电磁,保备用电等
- 网络安全
保证网络层面安全,比如访问控制,安全审计,入侵防范,恶意代码防范,设备防范等。
- 主机安全
比如,身份鉴别,访问控制,安全审计,剩余信息保护(比如退出时清理信息),安全审计,入侵防范等。
- 应用安全
比如,数据完整性,数据保密性(加密),数据备份和回复。
16.6 ISO27001
什么是ISO27001?
信息安全管理体系标准(ISO27001)可有效保护信息资源,保护信息化进程健康、有序、可持续发展。ISO27001是信息安全领域的管理体系标准,类似于质量管理体系认证的 ISO9000标准。当您的组织通过了ISO27001的认证,就相当于通过ISO9000的质量认证一般,表示您的组织信息安全管理已建立了一套科学有效的管理体系作为保障。
ISO27001认证流程?
第一阶段:现状调研
从日常运维、管理机制、系统配置等方面对贵公司信息安全管理安全现状进行调研,通过培训使贵公司相关人员全面了解信息安全管理的基本知识。
第二阶段:风险评估
对贵公司信息资产进行资产价值、威胁因素、脆弱性分析,从而评估贵公司信息安全风险,选择适当的措施、方法实现管理风险的目的。
第三阶段:管理策划
根据贵公司对信息安全风险的策略,制定相应信息安全整体规划、管理规划、技术规划等,形成完整的信息安全管理系统。
第四阶段:体系实施
ISMS建立起来(体系文件正式发布实施)之后,要通过一定时间的试运行来检验其有效性和稳定性。
第五阶段:认证审核
经过一定时间运行,ISMS达到一个稳定的状态,各项文档和记录已经建立完备,此时,可以提请进行认证。