BAT大厂面试题与全栈知识体系结合 Hot必读
提示
你好,我是pdai。你是否也曾对未来迷茫不知方向,也曾每天在碎片化的学习中焦虑,也曾钦羡他人步入高于你的层次? 那么跟随我,结合BAT大厂面试题帮你构筑你自己的知识体系,提升靠技术实现自我价值的概率和掌控力;而往往当你将本文中知识点掌握时,你会发现那些平时高谈阔论的家伙其实都是纸老虎;但你依然要保持谦卑,闻道有先后,术业有专攻,如是而已。@pdai
全栈知识体系总览
为适配更多屏幕,切成两个图:
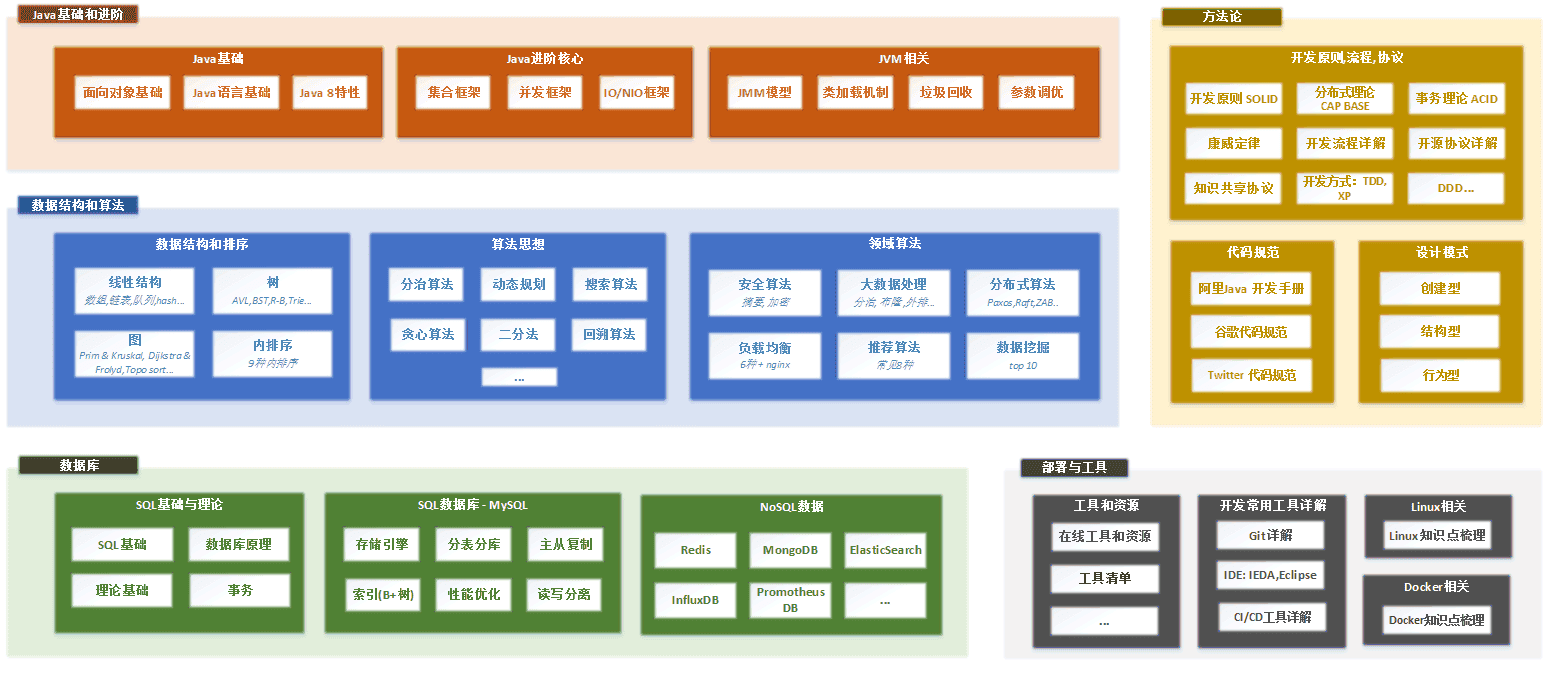
(点击放大看)
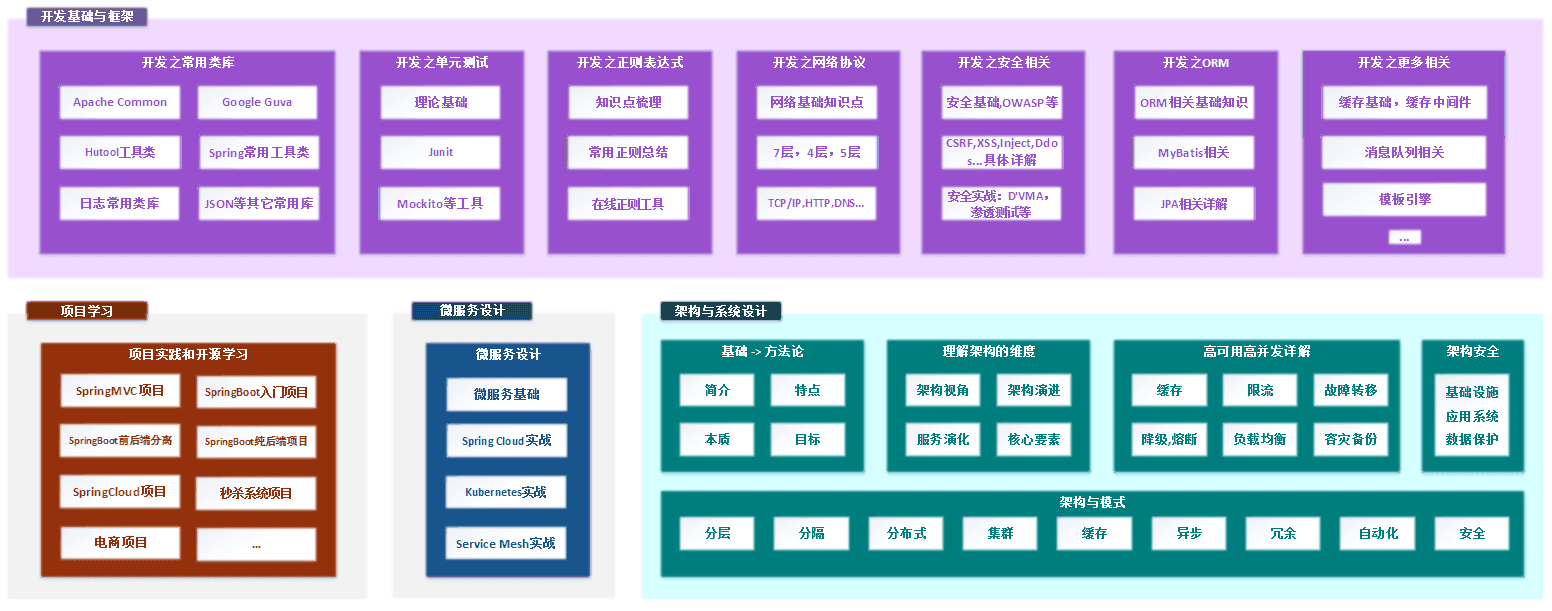
(点击放大看)
适合什么样的人群阅读
面试官:系统性的理解不仅能帮助你理解知识的基础体系,更能帮快速甄别候选人才开发入门者:提前上船,赢在起跑线开发进阶者:若干年的开发,尚还没有方向的是个想上进的:关键是你觉得对你有意义,且做你认为正确的事就够了
Java入门与进阶
面向对象与Java基础
知识体系系统性梳理

相关文章
Java入门:你可能会注意到,
面向对象与Java基础这个章节写的非常简单,为什么呢? 因为就语法本身而言,大多数人入门一门语言只需要两周左右,所以这里主要梳理下知识点和常见的Q/A。
基础知识点复习完了以后,我们需要深入的理解Java中的一些基础机制:
- Java 基础 - 泛型机制详解
- Java泛型这个特性是从JDK 1.5才开始加入的,因此为了兼容之前的版本,Java泛型的实现采取了“伪泛型”的策略,即Java在语法上支持泛型,但是在编译阶段会进行所谓的“类型擦除”(Type Erasure),将所有的泛型表示(尖括号中的内容)都替换为具体的类型(其对应的原生态类型),就像完全没有泛型一样。
- Java 基础 - 注解机制详解
- 注解是JDK1.5版本开始引入的一个特性,用于对代码进行说明,可以对包、类、接口、字段、方法参数、局部变量等进行注解。它是框架学习和设计者必须掌握的基础。
- Java 基础 - 异常机制详解
- Java异常是Java提供的一种识别及响应错误的一致性机制,java异常机制可以使程序中异常处理代码和正常业务代码分离,保证程序代码更加优雅,并提高程序健壮性。
- Java 基础 - 反射机制详解
- JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。Java反射机制在框架设计中极为广泛,需要深入理解。
- Java常用机制 - SPI机制
- SPI(Service Provider Interface),是JDK内置的一种 服务提供发现机制,可以用来启用框架扩展和替换组件,主要是被框架的开发人员使用。
Java进阶 - 集合框架
知识体系系统性梳理

相关文章
A. Java进阶 - Java 集合框架:Java 集合框架应用是极其广泛的,对于其总体框架用法及源码都必要深刻理解。@pdai
B. Java进阶 - Java 集合框架之 Collection源码解读:对核心的Collection类进行源码解读。
- Collection - ArrayList 源码解析
- Collection - LinkedList源码解析
- Collection - Stack & Queue 源码解析
- Collection - PriorityQueue源码解析
C. Java进阶 - Java 集合框架之 Map & Set 源码解读:对核心的Map & Set 类进行源码解读。
- Map - HashSet & HashMap 源码解析
- Map - LinkedHashSet&Map源码解析
- Map - TreeSet & TreeMap 源码解析
- Map - WeakHashMap源码解析
Java进阶 - 并发框架
知识体系系统性梳理
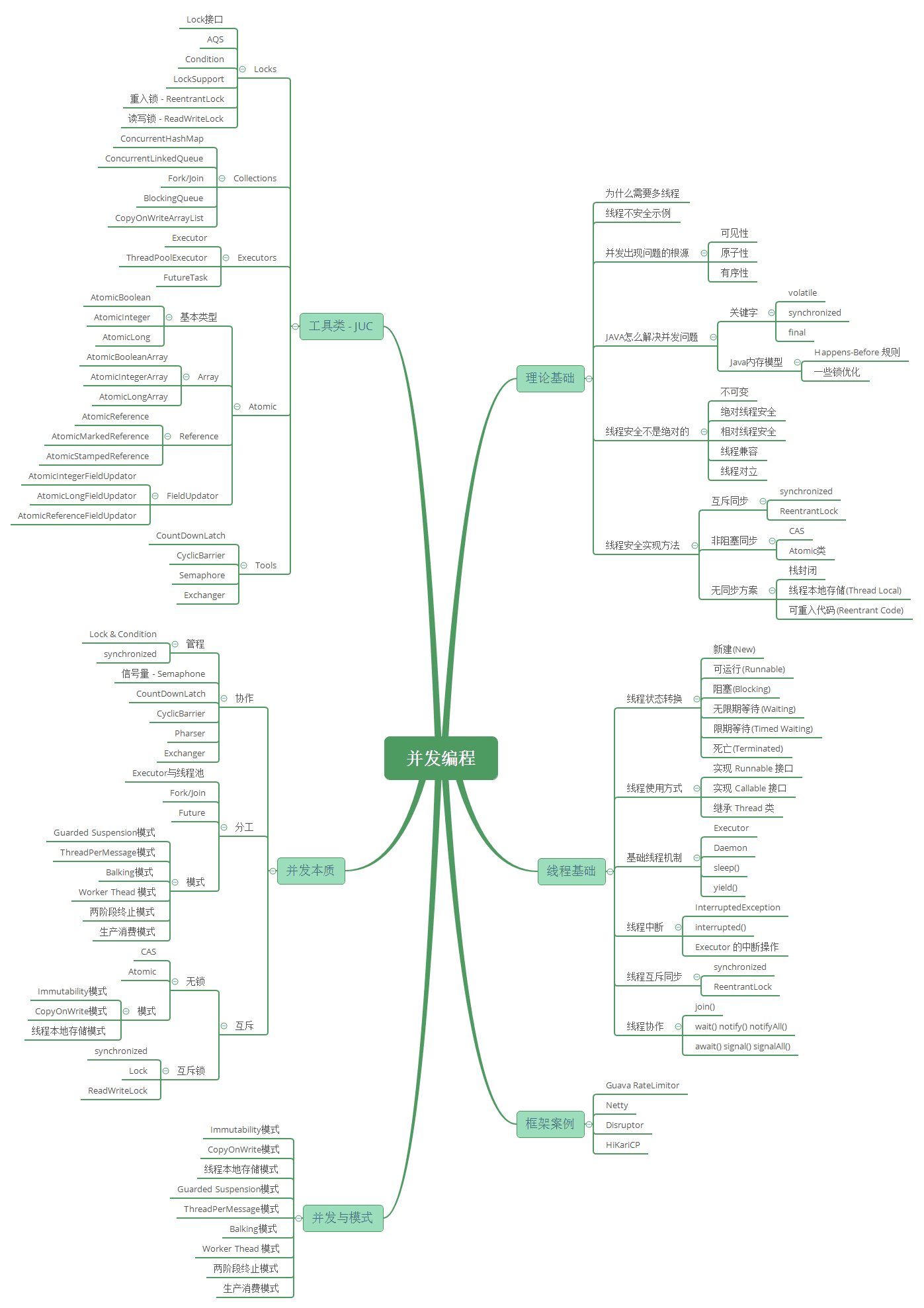
相关文章
A. Java进阶 - Java 并发之基础:首先全局的了解并发的知识体系,同时了解并发理论基础和线程基础,并发关键字等,这些是你理解Java并发框架的基础。@pdai
- Java 并发 - 知识体系
- Java 并发 - 理论基础
- 多线程的出现是要解决什么问题的?
- 线程不安全是指什么? 举例说明
- 并发出现线程不安全的本质什么? 可见性,原子性和有序性。
- Java是怎么解决并发问题的? 3个关键字,JMM和8个Happens-Before
- 线程安全是不是非真即假? 不是
- 线程安全有哪些实现思路?
- 如何理解并发和并行的区别?
- Java 并发 - 线程基础
- 线程有哪几种状态? 分别说明从一种状态到另一种状态转变有哪些方式?
- 通常线程有哪几种使用方式?
- 基础线程机制有哪些?
- 线程的中断方式有哪些?
- 线程的互斥同步方式有哪些? 如何比较和选择?
- 线程之间有哪些协作方式?
- 关键字: synchronized详解
- Synchronized可以作用在哪里? 分别通过对象锁和类锁进行举例。
- Synchronized本质上是通过什么保证线程安全的? 分三个方面回答:加锁和释放锁的原理,可重入原理,保证可见性原理。
- Synchronized由什么样的缺陷? Java Lock是怎么弥补这些缺陷的。
- Synchronized和Lock的对比,和选择?
- Synchronized在使用时有何注意事项?
- Synchronized修饰的方法在抛出异常时,会释放锁吗?
- 多个线程等待同一个Synchronized锁的时候,JVM如何选择下一个获取锁的线程?
- Synchronized使得同时只有一个线程可以执行,性能比较差,有什么提升的方法?
- 我想更加灵活地控制锁的释放和获取(现在释放锁和获取锁的时机都被规定死了),怎么办?
- 什么是锁的升级和降级? 什么是JVM里的偏斜锁、轻量级锁、重量级锁?
- 不同的JDK中对Synchronized有何优化?
- 关键字: volatile详解
- volatile关键字的作用是什么?
- volatile能保证原子性吗?
- 之前32位机器上共享的long和double变量的为什么要用volatile? 现在64位机器上是否也要设置呢?
- i++为什么不能保证原子性?
- volatile是如何实现可见性的? 内存屏障。
- volatile是如何实现有序性的? happens-before等
- 说下volatile的应用场景?
- 关键字: final详解
- 所有的final修饰的字段都是编译期常量吗?
- 如何理解private所修饰的方法是隐式的final?
- 说说final类型的类如何拓展? 比如String是final类型,我们想写个MyString复用所有String中方法,同时增加一个新的toMyString()的方法,应该如何做?
- final方法可以被重载吗? 可以
- 父类的final方法能不能够被子类重写? 不可以
- 说说final域重排序规则?
- 说说final的原理?
- 使用 final 的限制条件和局限性?
- 看本文最后的一个思考题
B. Java进阶 - Java 并发之J.U.C框架:然后需要对J.U.C框架五大类详细解读,包括:Lock框架,并发集合, 原子类, 线程池和工具类。@pdai
- JUC - 类汇总和学习指南
- JUC框架包含几个部分?
- 每个部分有哪些核心的类?
- 最最核心的类有哪些?
B.1 Java进阶 - Java 并发之J.U.C框架【1/5】:CAS及原子类:从最核心的CAS, Unsafe和原子类开始分析。
- JUC原子类: CAS, Unsafe和原子类详解
- 线程安全的实现方法有哪些?
- 什么是CAS?
- CAS使用示例,结合AtomicInteger给出示例?
- CAS会有哪些问题?
- 针对这这些问题,Java提供了哪几个解决的?
- AtomicInteger底层实现? CAS+volatile
- 请阐述你对Unsafe类的理解?
- 说说你对Java原子类的理解? 包含13个,4组分类,说说作用和使用场景。
- AtomicStampedReference是什么?
- AtomicStampedReference是怎么解决ABA的? 内部使用Pair来存储元素值及其版本号
- java中还有哪些类可以解决ABA的问题? AtomicMarkableReference
B.2 Java进阶 - Java 并发之J.U.C框架【2/5】:锁:然后分析JUC中锁。
- JUC锁: LockSupport详解
- 为什么LockSupport也是核心基础类? AQS框架借助于两个类:Unsafe(提供CAS操作)和LockSupport(提供park/unpark操作)
- 写出分别通过wait/notify和LockSupport的park/unpark实现同步?
- LockSupport.park()会释放锁资源吗? 那么Condition.await()呢?
- Thread.sleep()、Object.wait()、Condition.await()、LockSupport.park()的区别? 重点
- 如果在wait()之前执行了notify()会怎样?
- 如果在park()之前执行了unpark()会怎样?
- JUC锁: 锁核心类AQS详解
- 什么是AQS? 为什么它是核心?
- AQS的核心思想是什么? 它是怎么实现的? 底层数据结构等
- AQS有哪些核心的方法?
- AQS定义什么样的资源获取方式? AQS定义了两种资源获取方式:
独占(只有一个线程能访问执行,又根据是否按队列的顺序分为公平锁和非公平锁,如ReentrantLock) 和共享(多个线程可同时访问执行,如Semaphore、CountDownLatch、CyclicBarrier)。ReentrantReadWriteLock可以看成是组合式,允许多个线程同时对某一资源进行读。 - AQS底层使用了什么样的设计模式? 模板
- AQS的应用示例?
- JUC锁: ReentrantLock详解
- 什么是可重入,什么是可重入锁? 它用来解决什么问题?
- ReentrantLock的核心是AQS,那么它怎么来实现的,继承吗? 说说其类内部结构关系。
- ReentrantLock是如何实现公平锁的?
- ReentrantLock是如何实现非公平锁的?
- ReentrantLock默认实现的是公平还是非公平锁?
- 使用ReentrantLock实现公平和非公平锁的示例?
- ReentrantLock和Synchronized的对比?
- JUC锁: ReentrantReadWriteLock详解
- 为了有了ReentrantLock还需要ReentrantReadWriteLock?
- ReentrantReadWriteLock底层实现原理?
- ReentrantReadWriteLock底层读写状态如何设计的? 高16位为读锁,低16位为写锁
- 读锁和写锁的最大数量是多少?
- 本地线程计数器ThreadLocalHoldCounter是用来做什么的?
- 缓存计数器HoldCounter是用来做什么的?
- 写锁的获取与释放是怎么实现的?
- 读锁的获取与释放是怎么实现的?
- RentrantReadWriteLock为什么不支持锁升级?
- 什么是锁的升降级? RentrantReadWriteLock为什么不支持锁升级?
B.3 Java进阶 - Java 并发之J.U.C框架【3/5】:集合:再理解JUC中重要的支持并发的集合。
- JUC集合: ConcurrentHashMap详解
- 为什么HashTable慢? 它的并发度是什么? 那么ConcurrentHashMap并发度是什么?
- ConcurrentHashMap在JDK1.7和JDK1.8中实现有什么差别? JDK1.8解決了JDK1.7中什么问题
- ConcurrentHashMap JDK1.7实现的原理是什么? 分段锁机制
- ConcurrentHashMap JDK1.8实现的原理是什么? 数组+链表+红黑树,CAS
- ConcurrentHashMap JDK1.7中Segment数(concurrencyLevel)默认值是多少? 为何一旦初始化就不可再扩容?
- ConcurrentHashMap JDK1.7说说其put的机制?
- ConcurrentHashMap JDK1.7是如何扩容的? rehash(注:segment 数组不能扩容,扩容是 segment 数组某个位置内部的数组 HashEntry<K,V>[] 进行扩容)
- ConcurrentHashMap JDK1.8是如何扩容的? tryPresize
- ConcurrentHashMap JDK1.8链表转红黑树的时机是什么? 临界值为什么是8?
- ConcurrentHashMap JDK1.8是如何进行数据迁移的? transfer
- JUC集合: CopyOnWriteArrayList详解
- 请先说说非并发集合中Fail-fast机制?
- 再为什么说ArrayList查询快而增删慢?
- 对比ArrayList说说CopyOnWriteArrayList的增删改查实现原理? COW基于拷贝
- 再说下弱一致性的迭代器原理是怎么样的?
COWIterator<E> - CopyOnWriteArrayList为什么并发安全且性能比Vector好?
- CopyOnWriteArrayList有何缺陷,说说其应用场景?
- JUC集合: ConcurrentLinkedQueue详解
- 要想用线程安全的队列有哪些选择? Vector,
Collections.synchronizedList( List<T> list), ConcurrentLinkedQueue等 - ConcurrentLinkedQueue实现的数据结构?
- ConcurrentLinkedQueue底层原理? 全程无锁(CAS)
- ConcurrentLinkedQueue的核心方法有哪些? offer(),poll(),peek(),isEmpty()等队列常用方法
- 说说ConcurrentLinkedQueue的HOPS(延迟更新的策略)的设计?
- ConcurrentLinkedQueue适合什么样的使用场景?
- 要想用线程安全的队列有哪些选择? Vector,
- JUC集合: BlockingQueue详解
- 什么是BlockingDeque?
- BlockingQueue大家族有哪些? ArrayBlockingQueue, DelayQueue, LinkedBlockingQueue, SynchronousQueue...
- BlockingQueue适合用在什么样的场景?
- BlockingQueue常用的方法?
- BlockingQueue插入方法有哪些? 这些方法(
add(o),offer(o),put(o),offer(o, timeout, timeunit))的区别是什么? - BlockingDeque 与BlockingQueue有何关系,请对比下它们的方法?
- BlockingDeque适合用在什么样的场景?
- BlockingDeque大家族有哪些?
- BlockingDeque 与BlockingQueue实现例子?
B.4 Java进阶 - Java 并发之J.U.C框架【4/5】:线程池:再者分析JUC中非常常用的线程池等。
- JUC线程池: FutureTask详解
- FutureTask用来解决什么问题的? 为什么会出现?
- FutureTask类结构关系怎么样的?
- FutureTask的线程安全是由什么保证的?
- FutureTask结果返回机制?
- FutureTask内部运行状态的转变?
- FutureTask通常会怎么用? 举例说明。
- JUC线程池: ThreadPoolExecutor详解
- 为什么要有线程池?
- Java是实现和管理线程池有哪些方式? 请简单举例如何使用。
- 为什么很多公司不允许使用Executors去创建线程池? 那么推荐怎么使用呢?
- ThreadPoolExecutor有哪些核心的配置参数? 请简要说明
- ThreadPoolExecutor可以创建哪是哪三种线程池呢?
- 当队列满了并且worker的数量达到maxSize的时候,会怎么样?
- 说说ThreadPoolExecutor有哪些RejectedExecutionHandler策略? 默认是什么策略?
- 简要说下线程池的任务执行机制? execute –> addWorker –>runworker (getTask)
- 线程池中任务是如何提交的?
- 线程池中任务是如何关闭的?
- 在配置线程池的时候需要考虑哪些配置因素?
- 如何监控线程池的状态?
- JUC线程池: ScheduledThreadPool详解
- ScheduledThreadPoolExecutor要解决什么样的问题?
- ScheduledThreadPoolExecutor相比ThreadPoolExecutor有哪些特性?
- ScheduledThreadPoolExecutor有什么样的数据结构,核心内部类和抽象类?
- ScheduledThreadPoolExecutor有哪两个关闭策略? 区别是什么?
- ScheduledThreadPoolExecutor中scheduleAtFixedRate 和 scheduleWithFixedDelay区别是什么?
- 为什么ThreadPoolExecutor 的调整策略却不适用于 ScheduledThreadPoolExecutor?
- Executors 提供了几种方法来构造 ScheduledThreadPoolExecutor?
- JUC线程池: Fork/Join框架详解
- Fork/Join主要用来解决什么样的问题?
- Fork/Join框架是在哪个JDK版本中引入的?
- Fork/Join框架主要包含哪三个模块? 模块之间的关系是怎么样的?
- ForkJoinPool类继承关系?
- ForkJoinTask抽象类继承关系? 在实际运用中,我们一般都会继承 RecursiveTask 、RecursiveAction 或 CountedCompleter 来实现我们的业务需求,而不会直接继承 ForkJoinTask 类。
- 整个Fork/Join 框架的执行流程/运行机制是怎么样的?
- 具体阐述Fork/Join的分治思想和work-stealing 实现方式?
- 有哪些JDK源码中使用了Fork/Join思想?
- 如何使用Executors工具类创建ForkJoinPool?
- 写一个例子: 用ForkJoin方式实现1+2+3+...+100000?
- Fork/Join在使用时有哪些注意事项? 结合JDK中的斐波那契数列实例具体说明。
B.5 Java进阶 - Java 并发之J.U.C框架【5/5】:工具类:最后来看下JUC中有哪些工具类,以及线程隔离术ThreadLocal。
- JUC工具类: CountDownLatch详解
- 什么是CountDownLatch?
- CountDownLatch底层实现原理?
- CountDownLatch一次可以唤醒几个任务? 多个
- CountDownLatch有哪些主要方法? await(),countDown()
- CountDownLatch适用于什么场景?
- 写道题:实现一个容器,提供两个方法,add,size 写两个线程,线程1添加10个元素到容器中,线程2实现监控元素的个数,当个数到5个时,线程2给出提示并结束? 使用CountDownLatch 代替wait notify 好处。
- JUC工具类: CyclicBarrier详解
- 什么是CyclicBarrier?
- CyclicBarrier底层实现原理?
- CountDownLatch和CyclicBarrier对比?
- CyclicBarrier的核心函数有哪些?
- CyclicBarrier适用于什么场景?
- JUC工具类: Semaphore详解
- 什么是Semaphore?
- Semaphore内部原理?
- Semaphore常用方法有哪些? 如何实现线程同步和互斥的?
- Semaphore适合用在什么场景?
- 单独使用Semaphore是不会使用到AQS的条件队列?
- Semaphore中申请令牌(acquire)、释放令牌(release)的实现?
- Semaphore初始化有10个令牌,11个线程同时各调用1次acquire方法,会发生什么?
- Semaphore初始化有10个令牌,一个线程重复调用11次acquire方法,会发生什么?
- Semaphore初始化有1个令牌,1个线程调用一次acquire方法,然后调用两次release方法,之后另外一个线程调用acquire(2)方法,此线程能够获取到足够的令牌并继续运行吗?
- Semaphore初始化有2个令牌,一个线程调用1次release方法,然后一次性获取3个令牌,会获取到吗?
- JUC工具类: Phaser详解
- Phaser主要用来解决什么问题?
- Phaser与CyclicBarrier和CountDownLatch的区别是什么?
- 如果用CountDownLatch来实现Phaser的功能应该怎么实现?
- Phaser运行机制是什么样的?
- 给一个Phaser使用的示例?
- JUC工具类: Exchanger详解
- Exchanger主要解决什么问题?
- 对比SynchronousQueue,为什么说Exchanger可被视为 SynchronousQueue 的双向形式?
- Exchanger在不同的JDK版本中实现有什么差别?
- Exchanger实现机制?
- Exchanger已经有了slot单节点,为什么会加入arena node数组? 什么时候会用到数组?
- arena可以确保不同的slot在arena中是不会相冲突的,那么是怎么保证的呢?
- 什么是伪共享,Exchanger中如何体现的?
- Exchanger实现举例
- Java 并发 - ThreadLocal详解
- 什么是ThreadLocal? 用来解决什么问题的?
- 说说你对ThreadLocal的理解
- ThreadLocal是如何实现线程隔离的?
- 为什么ThreadLocal会造成内存泄露? 如何解决
- 还有哪些使用ThreadLocal的应用场景?
C. Java进阶 - Java 并发之 本质与模式:最后站在更高的角度看其本质(协作,分工和互斥),同时总结上述知识点所使用的模式。@pdai
Java进阶 - IO框架
知识体系系统性梳理
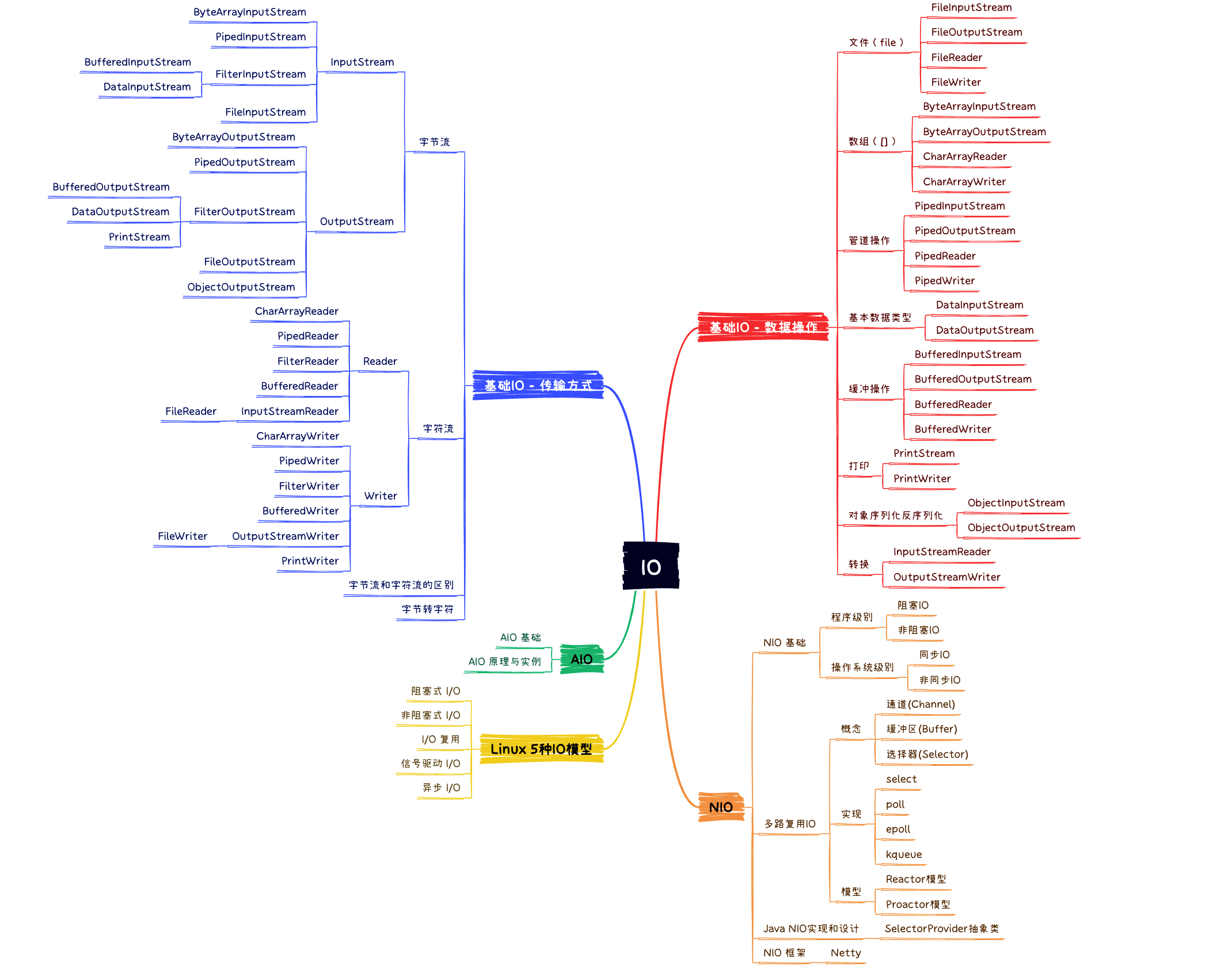
相关文章
A. Java进阶 - IO框架之知识体系:首先了解下Java IO框架包含什么,同时推荐下如何学习IO框架。@pdai
- Java IO/NIO/AIO - Overview
- 本文主要梳理Java IO/NIO/AIO的知识体系
B. Java进阶 - IO框架之基础IO:其次对Java基础IO框架进行梳理,包括其分类,使用和源码详解。@pdai
- Java IO - 分类(传输,操作)
- 本文主要从
传输方式和数据操作两个方面分析Java IO的分类
- 本文主要从
- Java IO - 设计模式(装饰者模式)
- Java I/O 使用了装饰者模式来实现
- Java IO - 源码: InputStream
- 本文主要从JDK源码角度分析InputStream
- Java IO - 源码: OutputStream
- 本文主要从JDK源码角度分析 OutputStream
- Java IO - 常见类使用
- 本文主要介绍Java IO常见类的使用,包括:磁盘操作,字节操作,字符操作,对象操作和网络操作
C. Java进阶 - IO框架之NIO/AIO等:然后再对Unix IO模型学习,引入到Java BIO/NIO/AIO相关知识详解。@pdai
- IO 模型 - Unix IO 模型
- 本文主要简要介绍 Unix I/O 5种模型,并对5大模型比较,并重点为后续章节解释IO多路复用做铺垫
- Java IO - BIO 详解
- BIO就是: blocking IO。最容易理解、最容易实现的IO工作方式,应用程序向操作系统请求网络IO操作,这时应用程序会一直等待;另一方面,操作系统收到请求后,也会等待,直到网络上有数据传到监听端口;操作系统在收集数据后,会把数据发送给应用程序;最后应用程序受到数据,并解除等待状态
- Java NIO - 基础详解
- 新的输入/输出 (NIO) 库是在 JDK 1.4 中引入的,弥补了原来的 I/O 的不足,提供了高速的、面向块的 I/O
- Java NIO - IO多路复用详解
- 本文主要对IO多路复用,Ractor模型以及Java NIO对其的支持
- Java AIO - 异步IO详解
- 本文主要对异步IO和Java中对AIO的支持详解。@pdai
D. Java进阶 - IO框架之开源框架:最后再对常用的开源框架进行分析和详解。@pdai
Java NIO - 零拷贝实现这里转一篇Java NIO 零拷贝的实现文章,在此之前建议先理解什么是Linux中零拷贝,可以先看这篇文章。本文从源码着手分析了 Java NIO 对零拷贝的实现,主要包括基于内存映射(mmap)方式的 MappedByteBuffer 以及基于 sendfile 方式的 FileChannel。最后在篇末简单的阐述了一下 Netty 中的零拷贝机制,以及 RocketMQ 和 Kafka 两种消息队列在零拷贝实现方式上的区别。
- Netty是一个高性能、异步事件驱动的NIO框架,提供了对TCP、UDP和文件传输的支持。作为当前最流行的NIO框架,Netty在互联网领域、大数据分布式计算领域、游戏行业、通信行业等获得了广泛的应用,一些业界著名的开源组件也基于Netty构建,比如RPC框架、zookeeper等
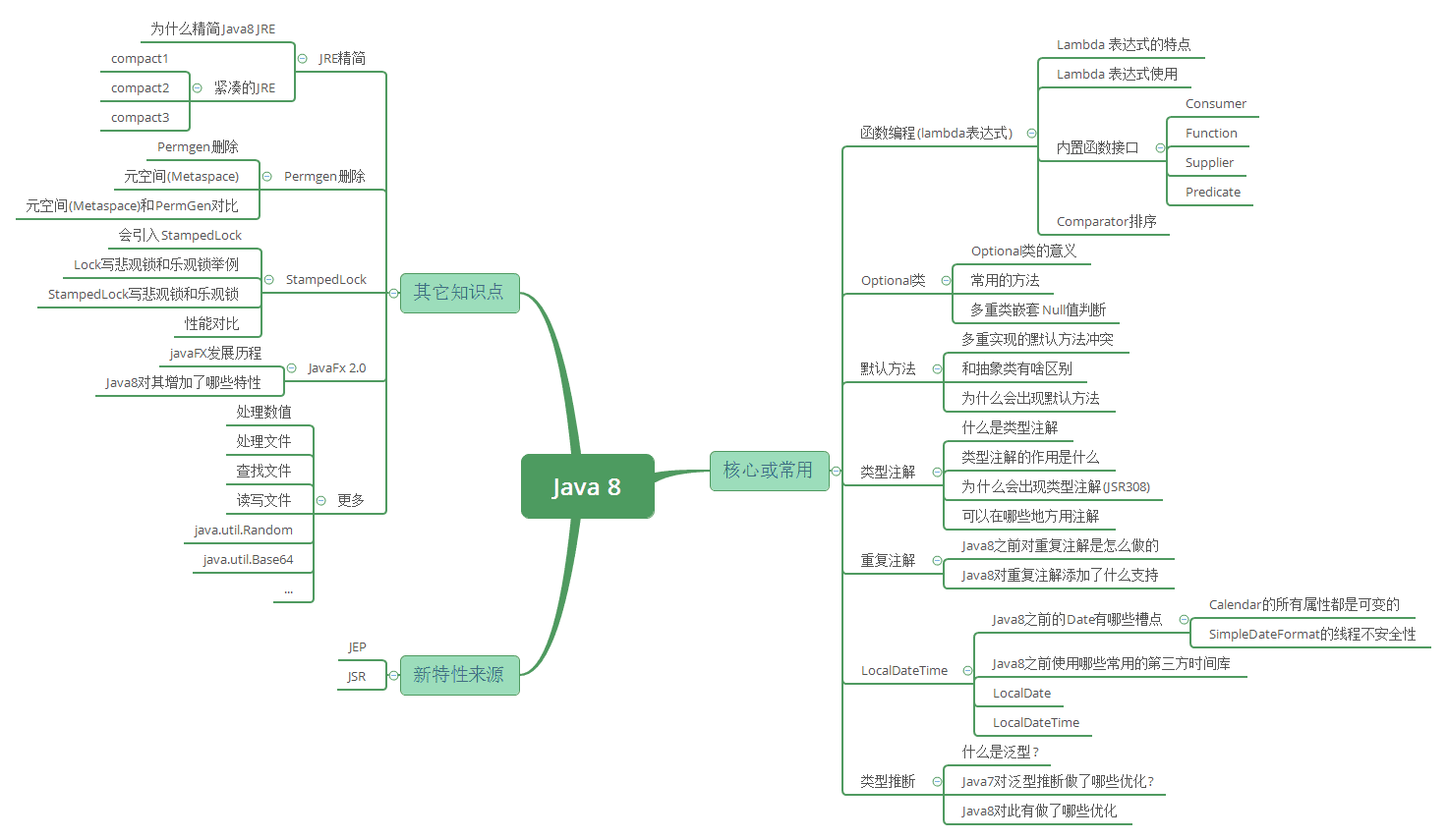
Java 8 新特性解读
知识体系系统性梳理
相关文章
A. Java进阶 - Java 8 新特性知识点:JDK1.6和JDK1.8是两个大的版本,目前主流使用的是JDK1.8, 所以有必要系统的学习下Java 8相关的知识点。@pdai
- Java 8 - 新特性汇总
- Java 新特性的增加都是来源于哪里?
- 简要说说Java8包含了哪些新的特性?
B. Java进阶 - Java 8 新特性解读之 常用核心特性:主要包含:函数编程(lambda表达式),Optional类,默认方法,类型注解,重复注解,LocalDateTime等等。
- Java 8 - 函数编程(lambda表达式)
- Lambda 表达式的特点?
- Lambda 表达式使用和Stream下的接口?
- 函数接口定义和使用,四大内置函数接口Consumer,Function,Supplier, Predicate.
- Comparator排序为例贯穿所有知识点。
- Java 8 - Optional类深度解析
- Optional类的意义?
- Optional类有哪些常用的方法?
- Optional举例贯穿所有知识点
- 如何解决多重类嵌套Null值判断?
- Java 8 - 默认方法
- 为什么会出现默认方法?
- 接口中出现默认方法,且类可以实现多接口的,那和抽象类有啥区别?
- 多重实现的默认方法冲突怎么办?
- Java 8 - 类型注解
- 注解在JDK哪个版本中出现的,可以在哪些地方用注解?
- 什么是类型注解?
- 类型注解的作用是什么?
- 为什么会出现类型注解(JSR308)?
- Java 8 - 重复注解
- Java8之前对重复注解是怎么做的?
- Java8对重复注解添加了什么支持?
- Java 8 - 类型推断优化
- 什么是泛型?
- Java7对泛型推断做了哪些优化?
- Java8对此有做了哪些优化?
- Java 8 - LocalDate/LocalDateTime
- Java8之前的Date有哪些槽点? (Calendar的所有属性都是可变的,SimpleDateFormat的线程不安全性等)
- Java8之前使用哪些常用的第三方时间库?
- Java8关于时间和日期有哪些类和方法,变比Java8之前它的特点是什么?
- 其它语言时间库?
C. Java进阶 - Java 8 新特性解读之 其它知识点:主要包含:JRE精简,Permgen删除及增加MetaSpace,StampedLock,JavaFx2.0等等。
- Java 8 - JRE精简
- 为什么精简Java8 JRE,及好处是啥?
- 紧凑的JRE分3种,分别是compact1、compact2、compact3,他们的关系是?
- 在不同平台上如何编译等?
- Java 8 - 移除Permgen
- Java8之前 “java.lang.OutOfMemoryError: PermGen space”是怎么引起的,怎么解决的?
- 新增加的元空间(Metaspace)包含哪些东西,画出图?
- 元空间(Metaspace)和PermGen对比?
- Java 8 - StampedLock
- 为什么会引入StampedLock?
- 用Lock写悲观锁和乐观锁举例?
- 用StampedLock写悲观锁和乐观锁举例?
- 性能对比?
- Java 8 - JavaFx 2.0
- JavaFX发展历程?
- Java8对其增加了哪些特性?
- Java 8 - 其它更新: 字符串,base64,...
- Java8 还有哪些其它更新?
Java 8 升Java 11
Java 11 在 2018 年 9 月 25 日正式发布!根据发布的规划,JDK 11 是一个长期维护的版本(LTS); 本文帮助你梳理Java 8 升Java 11 重要特性。
Java 11 升Java 17
JDK 17 在 2021 年 9 月 14 号正式发布了!根据发布的规划,这次发布的 JDK 17 是一个长期维护的版本(LTS)。SpingFramework 6 和SpringBoot 3中默认将使用JDK 17,所以JDK 17必将是使用较广泛的版本; 而从上个LTS版本JDK11到JDK17有哪些重要特性需要掌握呢?本文帮助你梳理Java 8 升Java 11 重要特性。
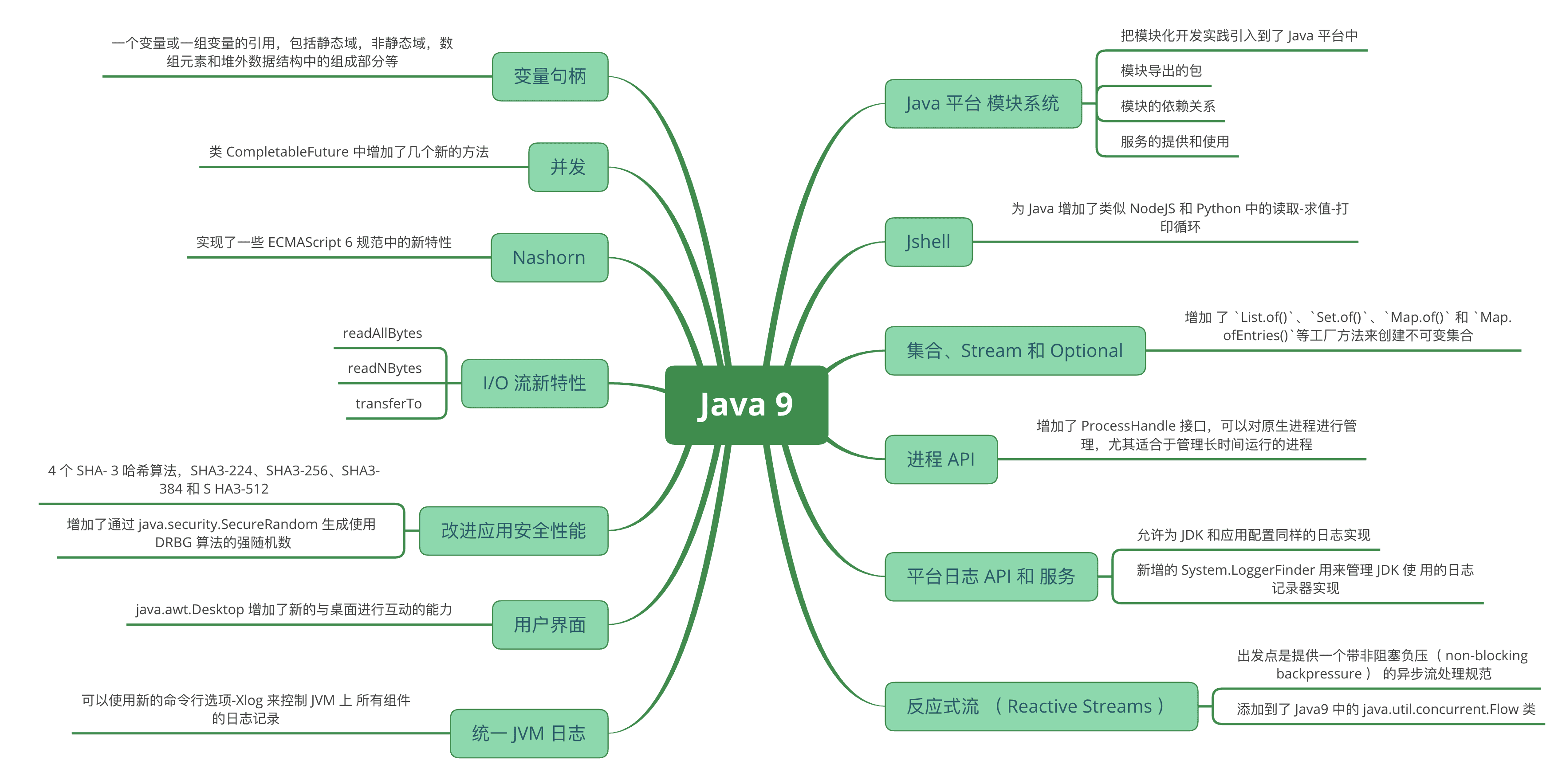
Java 9 新特性详解
Java 9 正式发布于 2017 年 9 月 21 日。作为 Java8 之后 3 年半才发布的新版本,Java 9 带来了很多重大的变化。其中最重要的改动是 Java 平台模块系统的引入。除此之外,还有一些新的特性。本文对 Java9 中包含的新特性做了概括性的介绍,可以帮助你快速了解 Java 9。
知识体系系统性梳理
相关文章
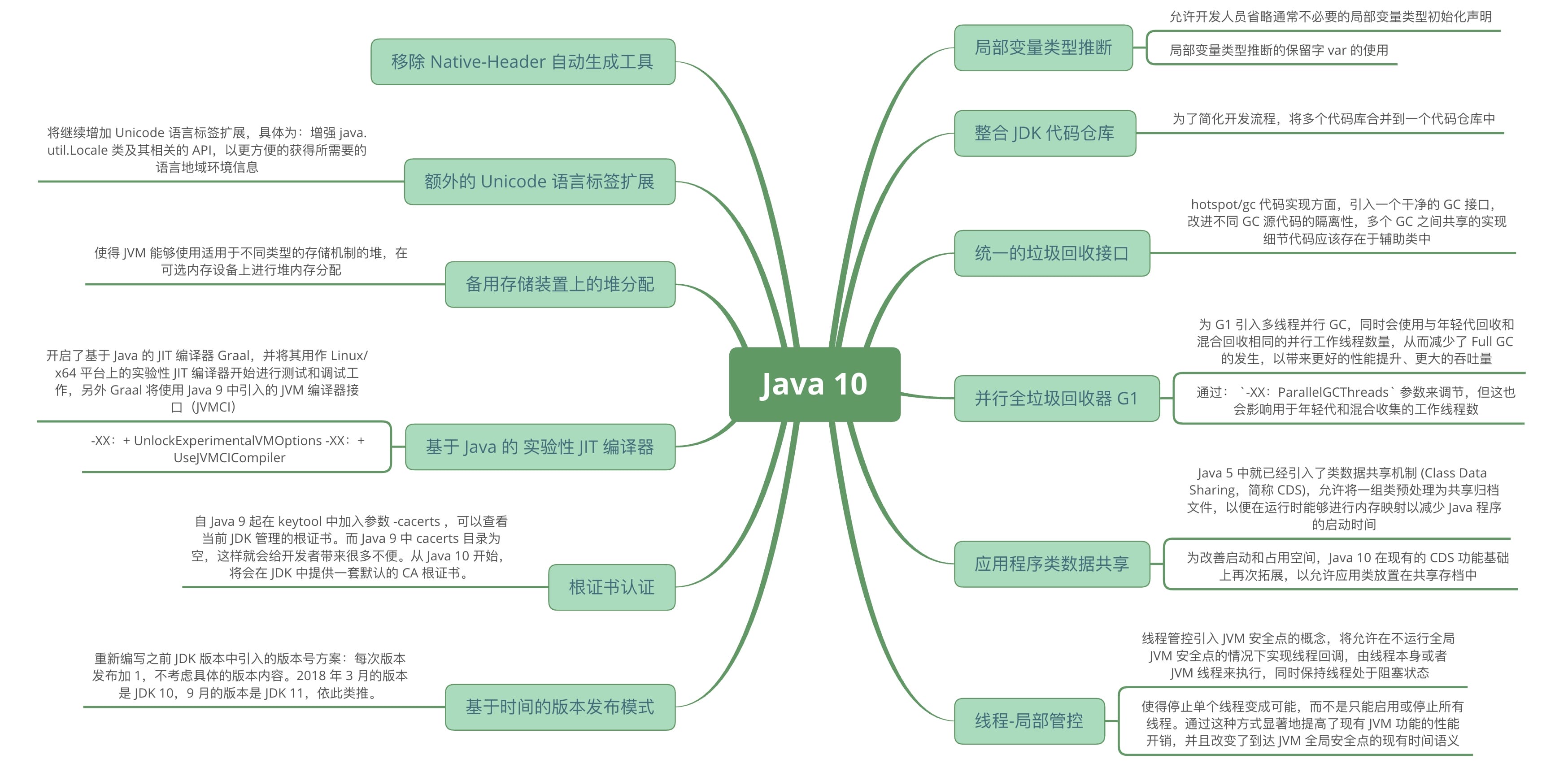
Java 10 新特性概述
作为当今使用最广泛的编程语言之一的 Java 在 2018 年 3 月 21 日发布了第十个大版本。为了更快地迭代、更好地跟进社区反馈,Java 语言版本发布周期调整为每隔 6 个月发布一次。Java 10 是这一新规则之后,采用新发布周期的第一个大版本。Java 10 版本带来了很多新特性,其中最备受广大开发者关注的莫过于局部变量类型推断。除此之外,还有其他包括垃圾收集器改善、GC 改进、性能提升、线程管控等一批新特性。本文主要针对 Java 10 中的新特性展开介绍,希望读者能从本文的介绍中快速了解 Java 10 带来的变化。
知识体系系统性梳理
相关文章
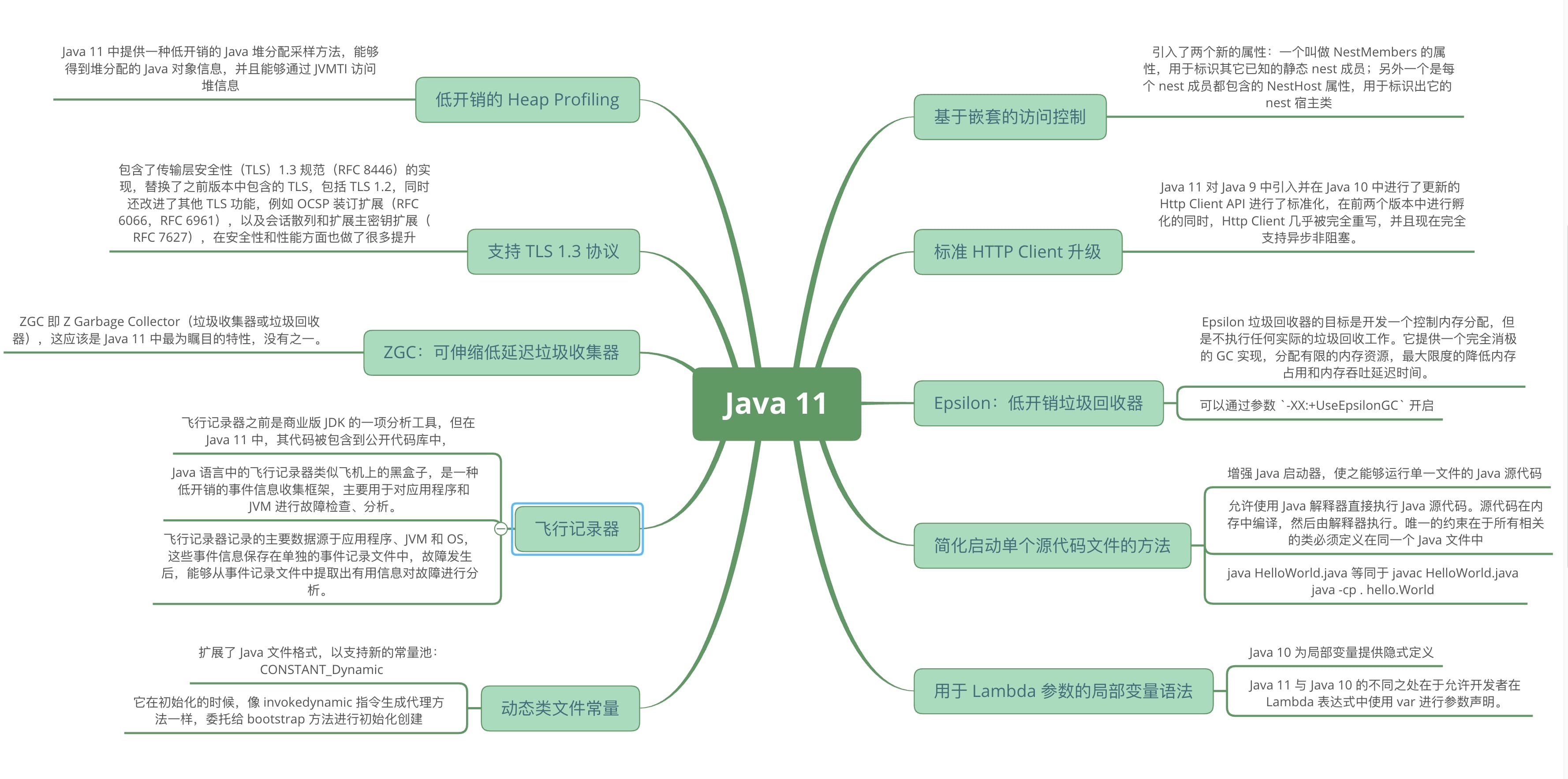
Java 11 新特性概述
Java 11 已于 2018 年 9 月 25 日正式发布,之前在 Java 10 新特性介绍 中介绍过,为了加快的版本迭代、跟进社区反馈,Java 的版本发布周期调整为每六个月一次——即每半年发布一个大版本,每个季度发布一个中间特性版本,并且做出不会跳票的承诺。通过这样的方式,Java 开发团队能够将一些重要特性尽早的合并到 Java Release 版本中,以便快速得到开发者的反馈,避免出现类似 Java 9 发布时的两次延期的情况。
知识体系系统性梳理
相关文章
Java 12 新特性概述
JDK12 在 2019 年 3 月 19 号正式发布,不同于JDK11,JDK12并不是一个LTS版本。作为一个中间版本,JDK12版本特性增加较少。 2017年宣布的加速发布节奏要求每六个月发布一次功能,每季度更新一次,每三年发布一次长期支持(LTS)更新版本(或每六个版本一次)
知识体系系统性梳理
相关文章
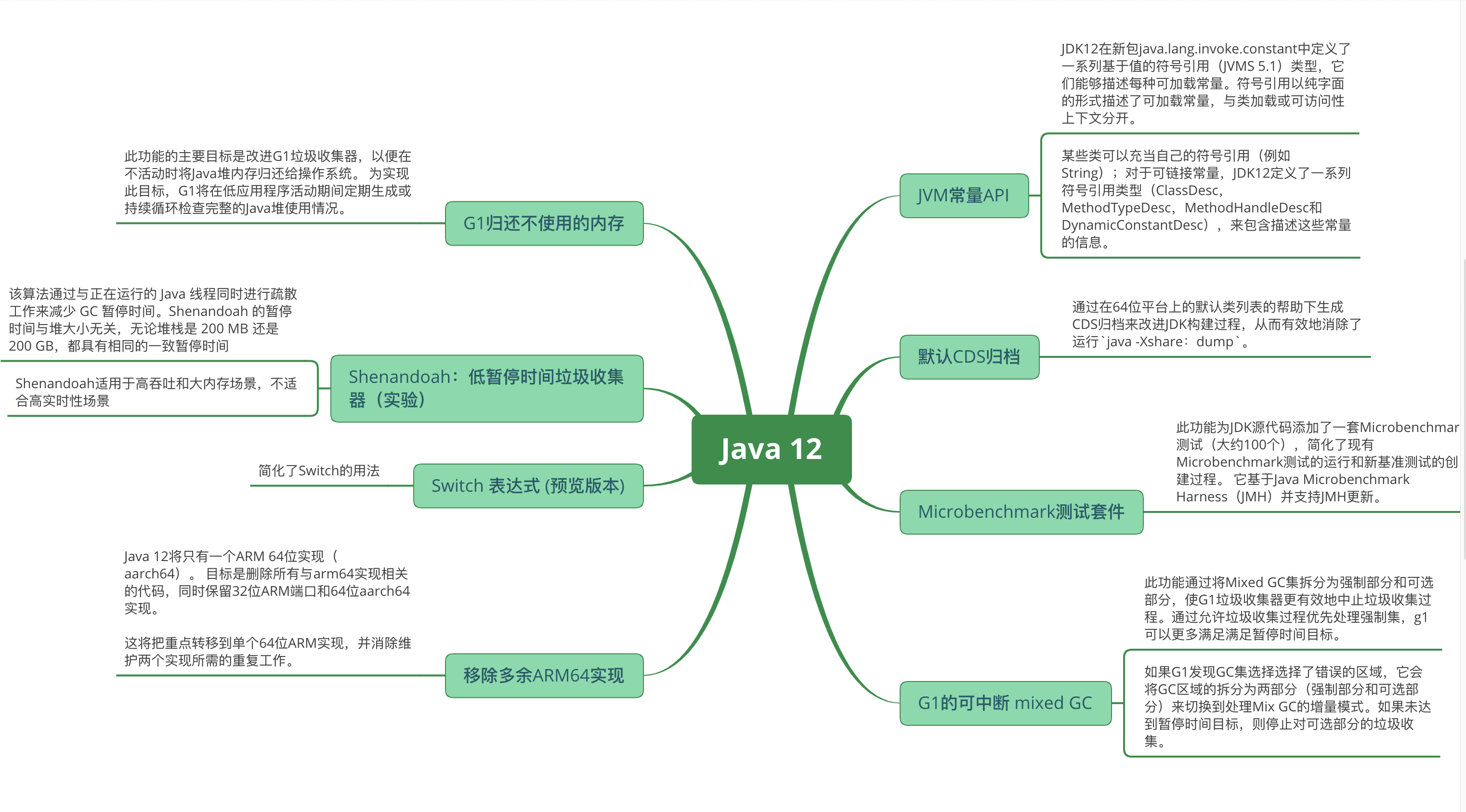
Java 13 新特性概述
Java 13 已如期于 9 月 17 日正式发布,此次更新是继半年前 Java 12 这大版本发布之后的一次常规版本更新,在这一版中,主要带来了 ZGC 增强、更新 Socket 实现、Switch 表达式更新等方面的改动、增强。本文主要针对 Java 13 中主要的新特性展开介绍,带你快速了解 Java 13 带来的不同体验。
知识体系系统性梳理
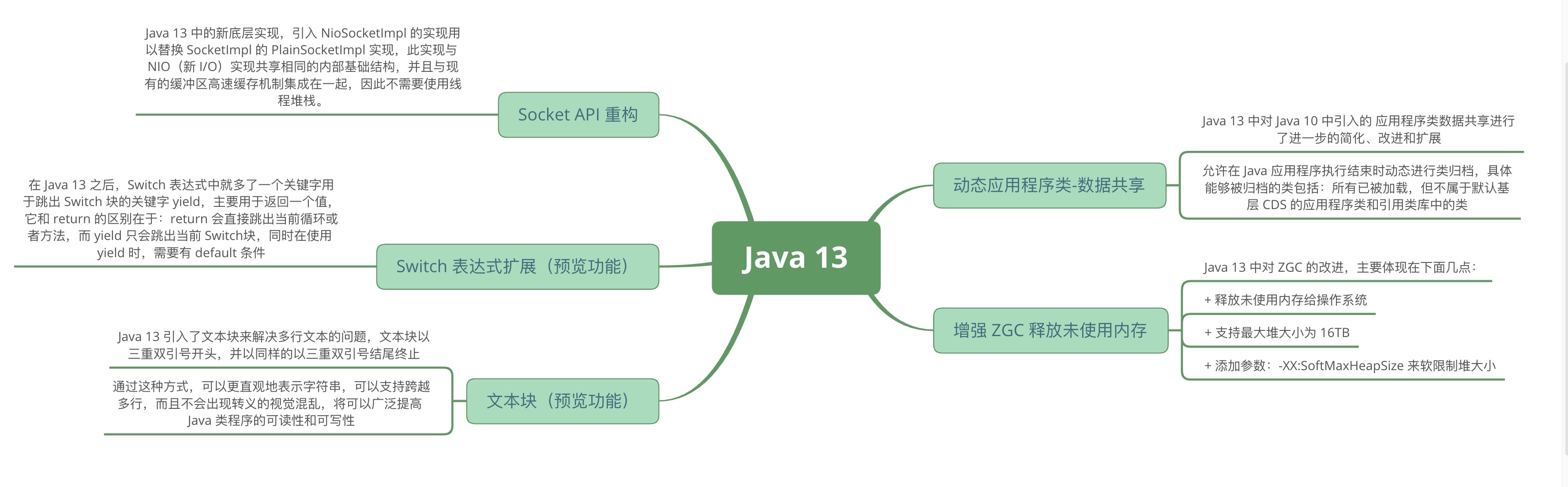
相关文章
Java 14 新特性概述
Java 14 已如期于 2020 年 3 月 17 日正式发布,此次更新是继半年前 Java 13 这大版本发布之后的又一次常规版本更新,即便在全球疫情如此严峻形势下,依然保持每六个月的版本更新频率,为大家及时带来改进和增强,这一点值得点赞。在这一版中,主要带来了 ZGC 增强、instanceof 增强、Switch 表达式更新为标准版等方面的改动、增强和新功能。本文主要介绍 Java 14 中的主要新特性,带您快速了解 Java 14 带来了哪些不一样的体验和便利。
知识体系系统性梳理
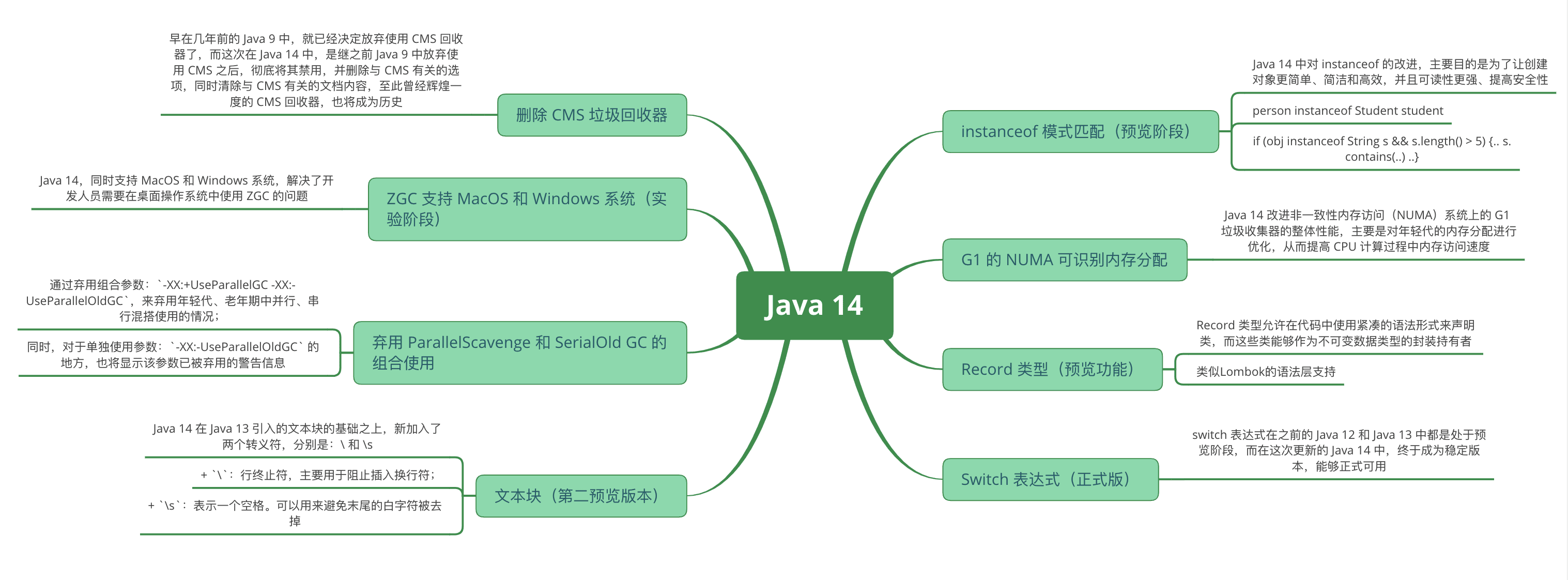
相关文章
Java 15 新特性概述
JDK 15 在 2020 年 9 月 15 号正式发布了!根据发布的规划,这次发布的 JDK 15 将是一个短期的过度版,只会被 Oracle 支持(维护)6 个月,直到明年 3 月的 JDK 16 发布此版本将停止维护。而 Oracle 下一个长期支持版(LTS 版)会在明年的 9 月份候发布(Java 17),LTS 版每 3 年发布一个,上一次长期支持版是 18 年 9 月发布的 JDK 11。
知识体系系统性梳理
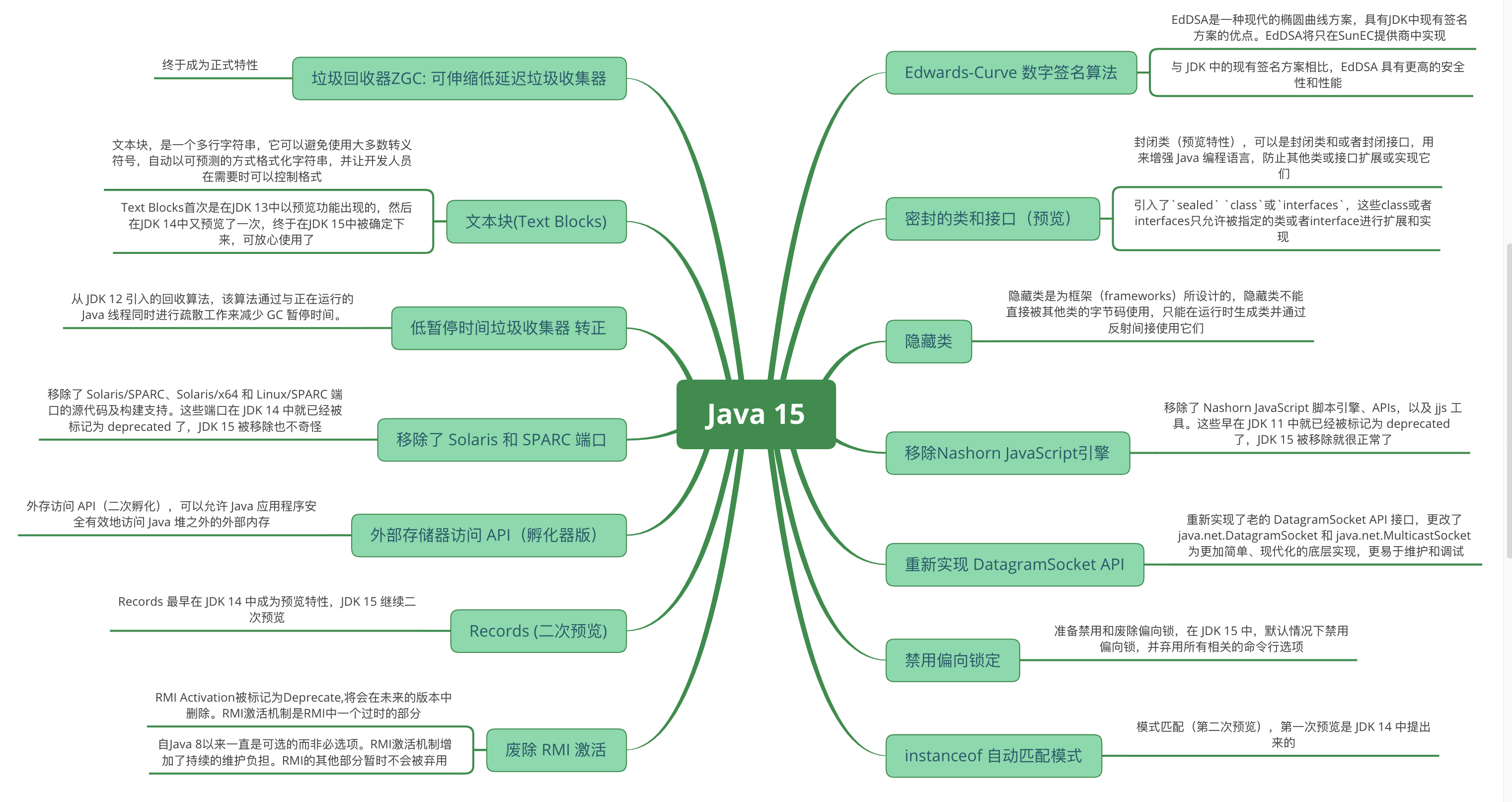
相关文章
Java 16 新特性概述
JDK 16 在 2021 年 3 月 16 号发布!根据发布的规划,这次发布的 JDK 17 是一个长期维护的版本(LTS)。Java 16 提供了数千个性能、稳定性和安全性更新,以及 17 个 JEP(JDK 增强提案),进一步改进了 Java 语言和平台,以帮助开发人员提高工作效率。
知识体系系统性梳理

相关文章
Java 17 新特性概述
JDK 17 在 2021 年 9 月 14 号正式发布了!根据发布的规划,这次发布的 JDK 17 是一个长期维护的版本(LTS)。Java 17 提供了数千个性能、稳定性和安全性更新,以及 14 个 JEP(JDK 增强提案),进一步改进了 Java 语言和平台,以帮助开发人员提高工作效率。JDK 17 包括新的语言增强、库更新、对新 Apple (Mx CPU)计算机的支持、旧功能的删除和弃用,并努力确保今天编写的 Java 代码在未来的 JDK 版本中继续工作而不会发生变化。它还提供语言功能预览和孵化 API,以收集 Java 社区的反馈。@pdai
知识体系系统性梳理
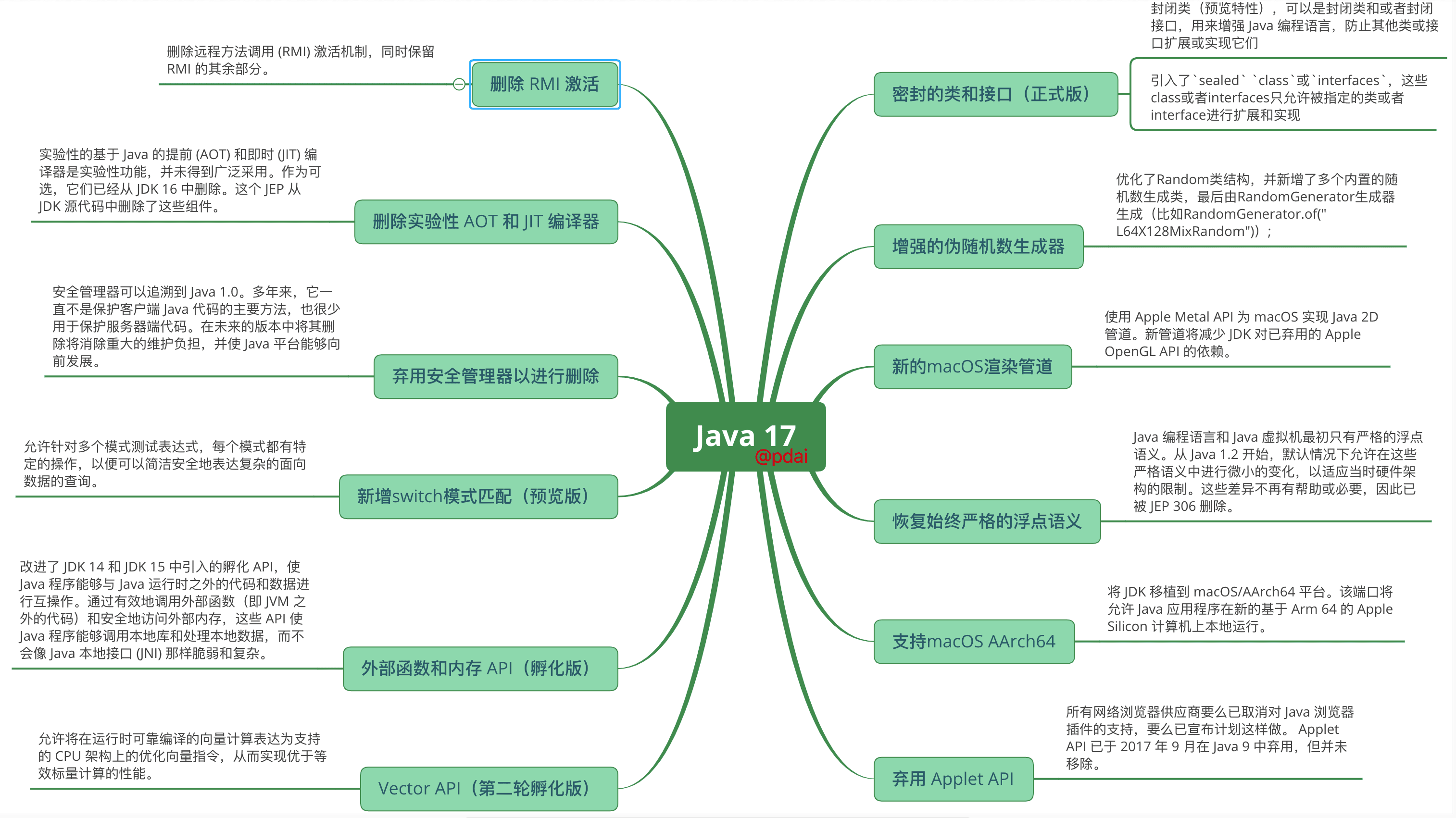
相关文章
Java进阶 - JVM相关
知识体系系统性梳理
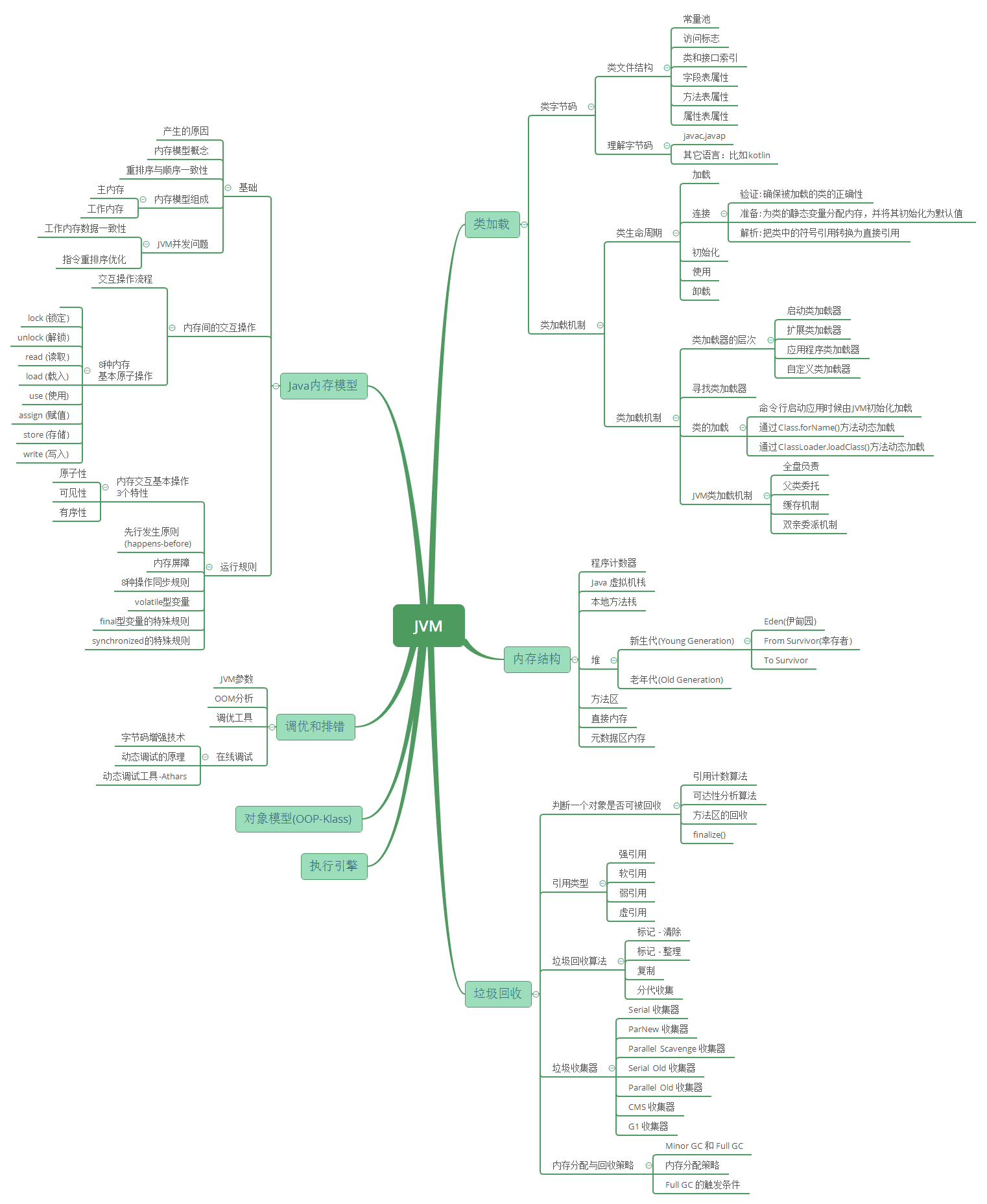
学习思路
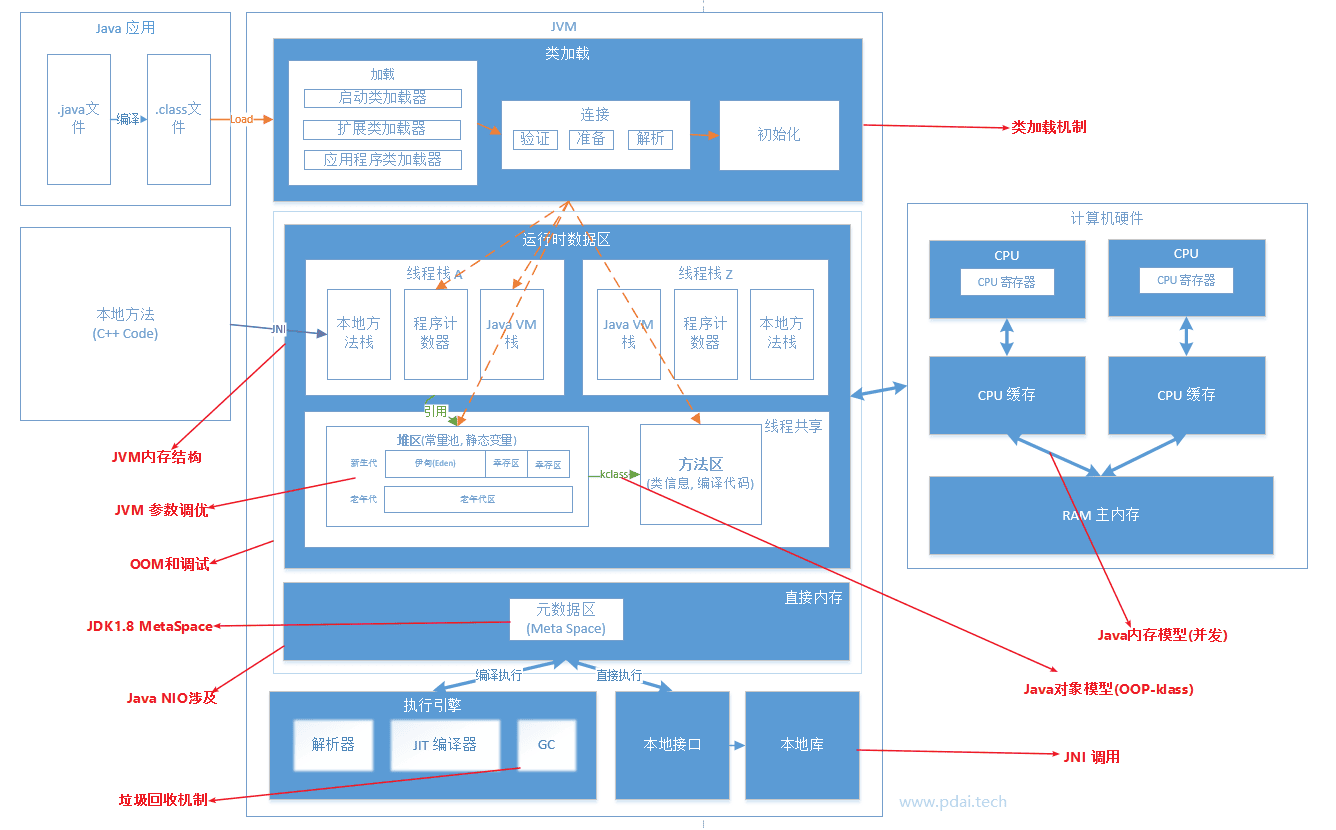
相关文章
A. Java进阶 - JVM相关 知识体系: 首先按照上述
学习思路,理解总体知识点在全局上与知识体系之间的对应关系。
B. Java进阶 - JVM相关 类加载: 然后理解类字节码和类的加载机制。
- JVM基础 - 类字节码详解
- 源代码通过编译器编译为字节码,再通过类加载子系统进行加载到JVM中运行
- JVM基础 - Java 类加载机制
- 这篇文章将带你深入理解Java 类加载机制
C. Java进阶 - JVM相关 内存结构: 因为类字节码是加载到JVM内存结构中的,所以紧接着理解JVM内存结构。
- JVM基础 - JVM内存结构
- 本文主要对JVM 内存结构进行讲解,注意不要和Java内存模型混淆了
D. Java进阶 - JVM相关 JMM: 然后通过理解JVM与硬件之间的联系,理解Java 通过其内存模型保证数据线程安全等,这是JVM在并发上底层的支持。
- JVM基础 - Java 内存模型引入
- 很多人都无法区分Java内存模型和JVM内存结构,以及Java内存模型与物理内存之间的关系。本文从堆栈角度引入JMM,然后介绍JMM和物理内存之间的关系, 为后面
JMM详解,JVM 内存结构详解,Java 对象模型详解等铺垫。
- 很多人都无法区分Java内存模型和JVM内存结构,以及Java内存模型与物理内存之间的关系。本文从堆栈角度引入JMM,然后介绍JMM和物理内存之间的关系, 为后面
- JVM基础 - Java 内存模型详解
- 本文主要转载自 Info 上深入理解Java内存模型, 作者程晓明。这篇文章对JMM讲的很清楚了,大致分三部分:重排序与顺序一致性;三个同步原语(lock,volatile,final)的内存语义,重排序规则及在处理器中的实现;java 内存模型的设计,及其与处理器内存模型和顺序一致性内存模型的关系
E. Java进阶 - JVM相关 GC: 再者理解下Java GC机制,如何回收内存等。
- GC - Java 垃圾回收基础知识
- 垃圾收集主要是针对堆和方法区进行;程序计数器、虚拟机栈和本地方法栈这三个区域属于线程私有的,只存在于线程的生命周期内,线程结束之后也会消失,因此不需要对这三个区域进行垃圾回收。
- GC - Java 垃圾回收器之G1详解
- G1垃圾回收器是在Java7 update 4之后引入的一个新的垃圾回收器。同优秀的CMS垃圾回收器一样,G1也是关注最小时延的垃圾回收器,也同样适合大尺寸堆内存的垃圾收集,官方在ZGC还没有出现时也推荐使用G1来代替选择CMS。G1最大的特点是引入分区的思路,弱化了分代的概念,合理利用垃圾收集各个周期的资源,解决了其他收集器甚至CMS的众多缺陷。
- GC - Java 垃圾回收器之ZGC详解
- ZGC(The Z Garbage Collector)是JDK 11中推出的一款低延迟垃圾回收器, 是JDK 11+ 最为重要的更新之一,适用于大内存低延迟服务的内存管理和回收。在梳理相关知识点时,发现美团技术团队分享的文章新一代垃圾回收器ZGC的探索与实践比较完善(包含G1收集器停顿时间瓶颈,原理,优化等), 这里分享给你,帮你构建ZGC相关的知识体系
- GC - Java 垃圾回收器之CMS GC问题分析与解决
- 本文整理自美团技术团队, 这篇文章将可以帮助你构建CMS GC相关问题解决的知识体系,分享给你。
F. Java进阶 - JVM相关 排错调优: 最后围绕着调试和排错,分析理解JVM调优参数,动态字节码技术及动态在线调试的原理;学会使用常用的调工具和在线动态调试工具等。

- 调试排错 - JVM 调优参数
- 本文对JVM涉及的常见的调优参数和垃圾回收参数进行阐述
- 调试排错 - Java 内存分析之堆内存和MetaSpace内存
- 本文以两个简单的例子(
堆内存溢出和MetaSpace (元数据) 内存溢出)解释Java 内存溢出的分析过程
- 本文以两个简单的例子(
- 调试排错 - Java 内存分析之堆外内存
- Java 堆外内存分析相对来说是复杂的,美团技术团队的Spring Boot引起的“堆外内存泄漏”排查及经验总结可以为很多Native Code内存泄漏/占用提供方向性指引。
- 调试排错 - Java 线程分析之线程Dump分析
- Thread Dump是非常有用的诊断Java应用问题的工具。
- 调试排错 - Java 问题排查之Linux命令
- Java 在线问题排查之通过linux常用命令排查。
- 调试排错 - Java 问题排查之工具单
- Java 在线问题排查之通过java调试/排查工具进行问题定位。
- 调试排错 - Java 问题排查之JVM可视化工具
- 本文主要梳理常见的JVM可视化的分析工具,主要包括JConsole, Visual VM, Vusial GC, JProfile 和 MAT等。
- 调试排错 - Java 问题排查之应用在线调试Arthas
- 本文主要介绍Alibaba开源的Java诊断工具,开源到现在已经1.7万个点赞了,深受开发者喜爱。具体解决在线问题,比如:
- 这个类从哪个 jar 包加载的? 为什么会报各种类相关的 Exception?
- 我改的代码为什么没有执行到? 难道是我没 commit? 分支搞错了?
- 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
- 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
- 是否有一个全局视角来查看系统的运行状况?
- 有什么办法可以监控到JVM的实时运行状态?
- 调试排错 - Java 问题排查之使用IDEA本地调试和远程调试
- Debug用来追踪代码的运行流程,通常在程序运行过程中出现异常,启用Debug模式可以分析定位异常发生的位置,以及在运行过程中参数的变化;并且在实际的排错过程中,还会用到Remote Debug。IDEA 相比 Eclipse/STS效率更高,本文主要介绍基于IDEA的Debug和Remote Debug的技巧。
- 调试排错 - Java动态调试技术原理
- 本文转载自 美团技术团队胡健的Java 动态调试技术原理及实践, 通过学习java agent方式进行动态调试了解目前很多大厂开源的一些基于此的调试工具。
数据结构与算法
数据结构基础
知识体系系统性梳理
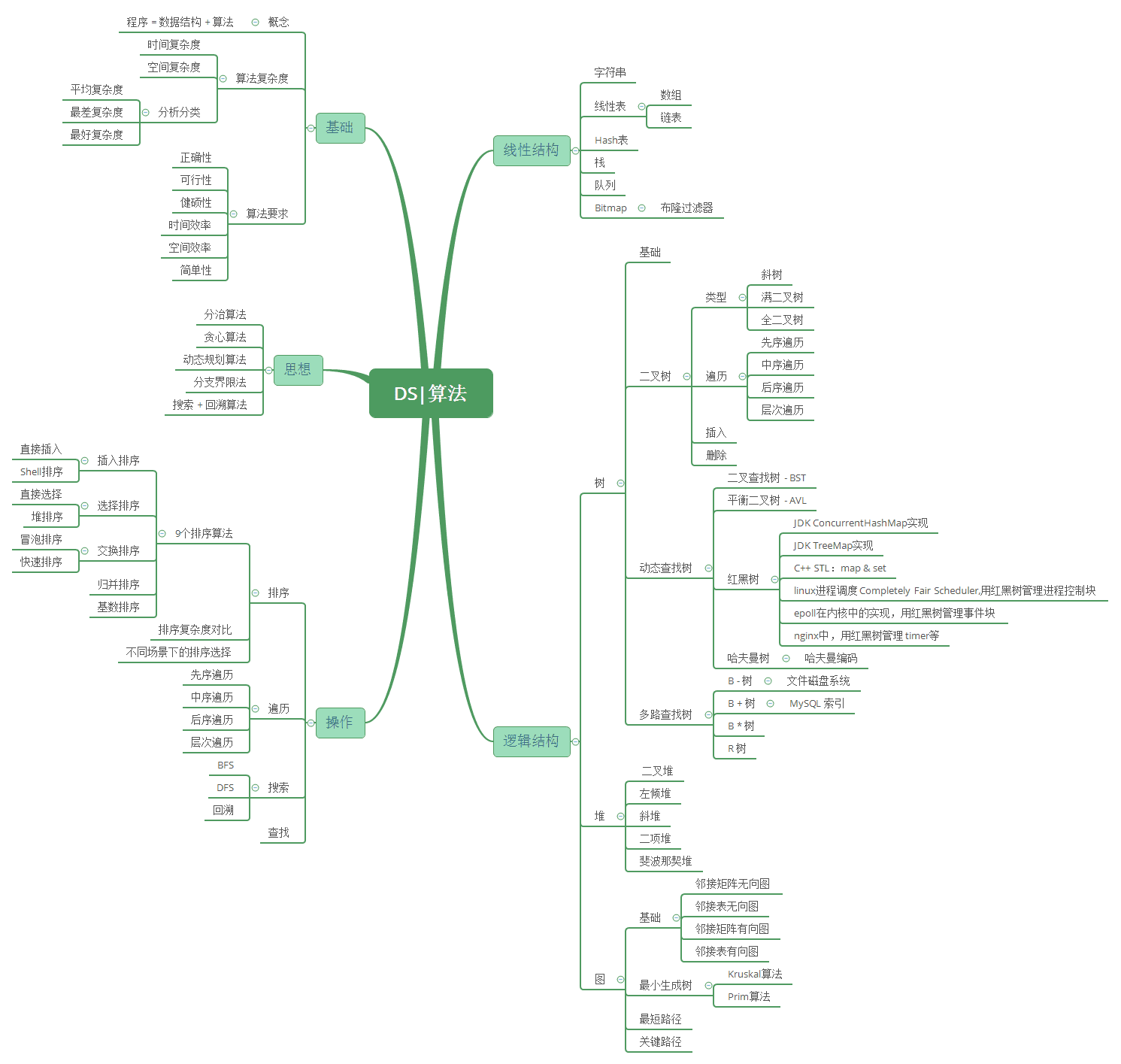
学习思路
避免孤立的学习知识点,要关联学习。比如实际应用当中,我们经常使用的是
查找和排序操作,这在我们的各种管理系统、数据库系统、操作系统等当中,十分常用,我们通过这个线索将知识点串联起来:
数组的下标寻址十分迅速,但计算机的内存是有限的,故数组的长度也是有限的,实际应用当中的数据往往十分庞大;而且无序数组的查找最坏情况需要遍历整个数组;后来人们提出了二分查找,二分查找要求数组的构造一定有序,二分法查找解决了普通数组查找复杂度过高的问题。任何一种数组无法解决的问题就是插入、删除操作比较复杂,因此,在一个增删查改比较频繁的数据结构中,数组不会被优先考虑
普通链表由于它的结构特点被证明根本不适合进行查找
哈希表是数组和链表的折中,同时它的设计依赖散列函数的设计,数组不能无限长、链表也不适合查找,所以也不适合大规模的查找
二叉查找树因为可能退化成链表,同样不适合进行查找
AVL树是为了解决可能退化成链表问题,但是AVL树的旋转过程非常麻烦,因此插入和删除很慢,也就是构建AVL树比较麻烦
红黑树是平衡二叉树和AVL树的折中,因此是比较合适的。集合类中的Map、关联数组具有较高的查询效率,它们的底层实现就是红黑树。
多路查找树 是大规模数据存储中,实现索引查询这样一个实际背景下,树节点存储的元素数量是有限的(如果元素数量非常多的话,查找就退化成节点内部的线性查找了),这样导致二叉查找树结构由于树的深度过大而造成磁盘I/O读写过于频繁,进而导致查询效率低下。
B树与自平衡二叉查找树不同,B树适用于读写相对大的数据块的存储系统,例如磁盘。它的应用是文件系统及部分非关系型数据库索引。
B+树在B树基础上,为叶子结点增加链表指针(B树+叶子有序链表),所有关键字都在叶子结点 中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中。通常用于关系型数据库(如Mysql)和操作系统的文件系统中。
B*树是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针, 在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3。
R树是用来做空间数据存储的树状数据结构。例如给地理位置,矩形和多边形这类多维数据建立索引。
Trie树是自然语言处理中最常用的数据结构,很多字符串处理任务都会用到。Trie树本身是一种有限状态自动机,还有很多变体。什么模式匹配、正则表达式,都与这有关。
相关文章
A. 数据结构 知识点:数据结构是基础中的基础,任何进阶都逃不开这些知识点。
B. 数据结构之 线性结构:首先理解数据结构中线性结构及其延伸:数组和矩阵,链表,栈和队列等。
- 线性表 - 数组和矩阵
- 数组是一种连续存储线性结构,元素类型相同,大小相等,数组是多维的,通过使用整型索引值来访问他们的元素,数组尺寸不能改变
- 线性表 - 链表
- n个节点离散分配,彼此通过指针相连,每个节点只有一个前驱节点,每个节点只有一个后续节点,首节点没有前驱节点,尾节点没有后续节点。确定一个链表我们只需要头指针,通过头指针就可以把整个链表都能推出来
- 线性表(散列) - 哈希表
- 散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。@pdai
- 线性表 - 栈和队列
- 数组和链表都是线性存储结构的基础,栈和队列都是线性存储结构的应用
C. 数据结构之 逻辑结构:树:然后理解数据结构中逻辑结构之树:二叉搜索树(BST),平衡二叉树(AVL),红黑树(R-B Tree),哈夫曼树,前缀树(Trie)等。
- 树 - 基础和Overview
- 树在数据结构中至关重要,这里展示树的整体知识体系结构和几种常见树类型
- 树 - 二叉搜索树(BST)
- 本文主要介绍 二叉树中最基本的二叉查找树(Binary Search Tree),(又:二叉搜索树,二叉排序树)它或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 它的左、右子树也分别为二叉排序树。
- 树 - 平衡二叉树(AVL)
- 平衡二叉树(Balanced Binary Tree)具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。平衡二叉树的常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等。 最小二叉平衡树的节点的公式如下 F(n)=F(n-1)+F(n-2)+1 这个类似于一个递归的数列,可以参考Fibonacci数列,1是根节点,F(n-1)是左子树的节点数量,F(n-2)是右子树的节点数量。
- 树 - 红黑树(R-B Tree)
- 红黑树(Red Black Tree) 是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组,是平衡二叉树和AVL树的折中。
- 树 - 哈夫曼树
- 哈夫曼又称最优二叉树, 是一种带权路径长度最短的二叉树。
- 树 - 前缀树(Trie)
- Trie,又称字典树、单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
D. 数据结构之 逻辑结构:图:最后理解数据结构中逻辑结构之图:图基础,图的遍历,最小生成树(Prim & Kruskal),最短路径(Dijkstra & Frolyd),拓扑排序(Topological sort),AOE & 关键路径等。
- 图 - 基础和Overview
- 图(Graph)是由顶点和连接顶点的边构成的离散结构。在计算机科学中,图是最灵活的数据结构之一,很多问题都可以使用图模型进行建模求解。例如: 生态环境中不同物种的相互竞争、人与人之间的社交与关系网络、化学上用图区分结构不同但分子式相同的同分异构体、分析计算机网络的拓扑结构确定两台计算机是否可以通信、找到两个城市之间的最短路径等等。
- 图 - 遍历(BFS & DFS)
- 图的深度优先搜索(Depth First Search),和树的先序遍历比较类似; 广度优先搜索算法(Breadth First Search),又称为"宽度优先搜索"或"横向优先搜索"
- 图 - 最小生成树(Prim & Kruskal)
- Kruskal算法是从最小权重边着手,将森林里的树逐渐合并;prim算法是从顶点出发,在根结点的基础上建起一棵树
- 图 - 最短路径(Dijkstra & Frolyd)
- 最短路径有着广泛的应用,比如地图两点间距离计算,公交查询系统,路由选择等
- 图 - 拓扑排序(Topological sort)
- 拓扑排序主要用来解决有向图中的依赖解析(dependency resolution)问题
- 图 - AOE & 关键路径
- 关键路径在项目管理计算工期等方面有广泛等应用,提升工期就是所见缩减所有关键路径上的工期,并且在实现时需要应用到之前拓扑排序的算法(前提: 有向无环图,有依赖关系)
排序算法详解
知识体系系统性梳理
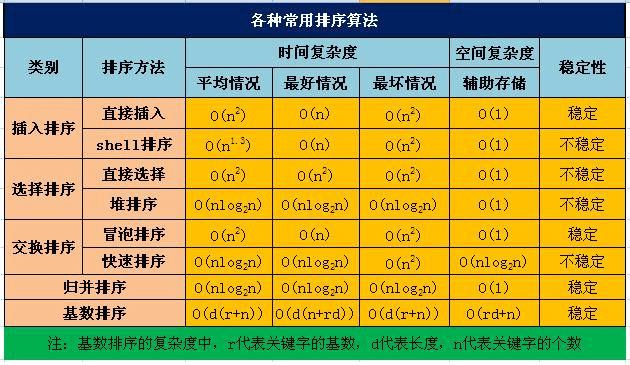
相关文章
A. 常见排序概要:重点理解几个排序之间的对比,时间和空间复杂度,以及应用。PS:越简单越要提高认知效率,做到战略上藐视战术上重视。
B. 常见排序详解:具体分析各种排序及其复杂度,查漏补缺;在综合复杂度及稳定性情况下,通常
希尔,快排和归并需要重点掌握。
- 排序 - 冒泡排序(Bubble Sort)
- 它是一种较简单的排序算法。它会遍历若干次要排序的数列,每次遍历时,它都会从前往后依次的比较相邻两个数的大小;如果前者比后者大,则交换它们的位置。这样,一次遍历之后,最大的元素就在数列的末尾! 采用相同的方法再次遍历时,第二大的元素就被排列在最大元素之前。重复此操作,直到整个数列都有序为止
- 排序 - 快速排序(Quick Sort)
- 它的基本思想是: 选择一个基准数,通过一趟排序将要排序的数据分割成独立的两部分;其中一部分的所有数据都比另外一部分的所有数据都要小。然后,再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
- 排序 - 插入排序(Insertion Sort)
- 直接插入排序(Straight Insertion Sort)的基本思想是: 把n个待排序的元素看成为一个有序表和一个无序表。开始时有序表中只包含1个元素,无序表中包含有n-1个元素,排序过程中每次从无序表中取出第一个元素,将它插入到有序表中的适当位置,使之成为新的有序表,重复n-1次可完成排序过程。
- 排序 - Shell排序(Shell Sort)
- 希尔排序实质上是一种分组插入方法。它的基本思想是: 对于n个待排序的数列,取一个小于n的整数gap(gap被称为步长)将待排序元素分成若干个组子序列,所有距离为gap的倍数的记录放在同一个组中;然后,对各组内的元素进行直接插入排序。 这一趟排序完成之后,每一个组的元素都是有序的。然后减小gap的值,并重复执行上述的分组和排序。重复这样的操作,当gap=1时,整个数列就是有序的。
- 排序 - 选择排序(Selection sort)
- 它的基本思想是: 首先在未排序的数列中找到最小(or最大)元素,然后将其存放到数列的起始位置;接着,再从剩余未排序的元素中继续寻找最小(or最大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
- 排序 - 堆排序(Heap Sort)
- 堆排序是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
- 排序 - 归并排序(Merge Sort)
- 将两个的有序数列合并成一个有序数列,我们称之为"归并"。归并排序(Merge Sort)就是利用归并思想对数列进行排序。
- 排序 - 桶排序(Bucket Sort)
- 桶排序(Bucket Sort)的原理很简单,将数组分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)
- 排序 - 基数排序(Radix Sort)
- 它的基本思想是: 将整数按位数切割成不同的数字,然后按每个位数分别比较。具体做法是: 将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列
算法思想详解
相关文章
A. 算法思想 详解:紧接着我们通过理解算法背后常用的算法思想,进行归纳总结,并通过leetcode练习来辅助理解和提升。
- 算法思想 - 分治算法
- 分治算法的基本思想是将一个规模为N的问题分解为K个规模较小的子问题,这些子问题相互独立且与原问题性质相同。求出子问题的解,就可得到原问题的解
- 算法思想 - 动态规划算法
- 动态规划算法通常用于求解具有某种最优性质的问题。在这类问题中,可能会有许多可行解。每一个解都对应于一个值,我们希望找到具有最优值的解。动态规划算法与分治法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解
- 算法思想 - 贪心算法
- 本文主要介绍算法中贪心算法的思想: 保证每次操作都是局部最优的,并且最后得到的结果是全局最优的
- 算法思想 - 二分法
- 本文主要介绍算法思想中分治算法重要的二分法,比如二分查找;二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
- 算法思想 - 搜索算法
- 本文主要介绍算法中搜索算法的思想,主要包含BFS,DFS
- 算法思想 - 回溯算法
- Backtracking(回溯)属于 DFS, 本文主要介绍算法中Backtracking算法的思想。回溯算法实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法
领域算法详解
知识体系系统性梳理

相关文章
A. 领域算法 梳理知识点:在了解基础算法之后,我们还要学习和了解在不同专业领域有哪些特有的算法。这里不一定要求复杂度,而是要有知识面以及解决问题的思路。
B. 领域算法之 安全算法:主要包括摘要算法和加密算法两大类。
- 安全算法 - 摘要算法
- 消息摘要算法的主要特征是加密过程不需要密钥,并且经过加密的数据无法被解密,目前可以解密逆向的只有CRC32算法,只有输入相同的明文数据经过相同的消息摘要算法才能得到相同的密文。消息摘要算法不存在密钥的管理与分发问题,适合于分布式网络上使用。
- 安全算法 - 加密算法
- 数据加密的基本过程就是对原来为明文的文件或数据按某种算法进行处理,使其成为不可读的一段代码为“密文”,使其只能在输入相应的密钥之后才能显示出原容,通过这样的途径来达到保护数据不被非法人窃取、阅读的目的。 该过程的逆过程为解密,即将该编码信息转化为其原来数据的过程
- 安全算法 - 国密算法
- 国密即国家密码局认定的国产密码算法。主要有SM1,SM2,SM3,SM4,SM7, SM9。
C. 领域算法之 字符串匹配算法:字符串匹配(String Matchiing)也称字符串搜索(String Searching)是字符串算法中重要的一种,是指从一个大字符串或文本中找到模式串出现的位置。
- 朴素的字符串匹配算法(Naive String Matching Algorithm)
- 朴素的字符串匹配算法又称为暴力匹配算法(Brute Force Algorithm),最为简单的字符串匹配算法
- Knuth-Morris-Pratt 字符串匹配算法(即 KMP 算法)
- Knuth-Morris-Pratt算法(简称KMP)是最常用的字符串匹配算法之一
- Boyer-Moore 字符串匹配算法
- 各种文本编辑器的"查找"功能(Ctrl+F),大多采用Boyer-Moore算法,效率非常高
- 字符串匹配 - 文本预处理:后缀树(Suffix Tree)
- 上述字符串匹配算法(朴素的字符串匹配算法, KMP 算法, Boyer-Moore算法)均是通过对模式(Pattern)字符串进行预处理的方式来加快搜索速度。对 Pattern 进行预处理的最优复杂度为 O(m),其中 m 为 Pattern 字符串的长度。那么,有没有对文本(Text)进行预处理的算法呢?本文即将介绍一种对 Text 进行预处理的字符串匹配算法:后缀树(Suffix Tree)
D. 领域算法之 大数据处理:这里其实想让大家理解的是大数据处理的常用思路,而不是算法本身。
- 大数据处理 - Overview
- 本文主要介绍大数据处理的一些思路
- 大数据处理 - 分治/hash/排序
- 就是先映射,而后统计,最后排序:
分而治之/hash映射: 针对数据太大,内存受限,只能是: 把大文件化成(取模映射)小文件,即16字方针: 大而化小,各个击破,缩小规模,逐个解决hash_map统计: 当大文件转化了小文件,那么我们便可以采用常规的hash_map(ip,value)来进行频率统计。堆/快速排序: 统计完了之后,便进行排序(可采取堆排序),得到次数最多的IP。
- 大数据处理 - Bitmap & Bloom Filter
- 布隆过滤器有着广泛的应用,对于大量数据的“存不存在”的问题在空间上有明显优势,但是在判断存不存在是有一定的错误率(false positive),也就是说,有可能把不属于这个集合的元素误认为属于这个集合(False Positive),但不会把属于这个集合的元素误认为不属于这个集合(False Negative)
- 大数据处理 - 双层桶划分
- 其实本质上还是分而治之的思想,重在“分”的技巧上!
适用范围: 第k大,中位数,不重复或重复的数字;基本原理及要点: 因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围,然后最后在一个可以接受的范围内进行。
- 其实本质上还是分而治之的思想,重在“分”的技巧上!
- 大数据处理 - Trie树/数据库/倒排索引
适用范围: 数据量大,重复多,但是数据种类小可以放入内存;基本原理及要点: 实现方式,节点孩子的表示方式;扩展: 压缩实现
- 大数据处理 - 外排序
适用范围: 大数据的排序,去重;基本原理及要点: 外排序的归并方法,置换选择败者树原理,最优归并树
- 大数据处理 - Map & Reduce
- MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。这样做的好处是可以在任务被分解后,可以通过大量机器进行并行计算,减少整个操作的时间。但如果你要我再通俗点介绍,那么,说白了,Mapreduce的原理就是一个归并排序
E. 领域算法之 分布式算法:接着向大家介绍分布式算法,包括一致性Hash算法,经典的Paxos算法,Raft算法,ZAB算法等;顺便也介绍了经典用于全局ID生成的Snowflake算法。
- 分布式算法 - Overview
- 本文总结下常见的分布式算法
- 分布式算法 - 一致性Hash算法
- 一致性Hash算法是个经典算法,Hash环的引入是为解决
单调性(Monotonicity)的问题;虚拟节点的引入是为了解决平衡性(Balance)问题
- 一致性Hash算法是个经典算法,Hash环的引入是为解决
- 分布式算法 - Paxos算法
- Paxos算法是Lamport宗师提出的一种基于消息传递的分布式一致性算法,使其获得2013年图灵奖。自Paxos问世以来就持续垄断了分布式一致性算法,Paxos这个名词几乎等同于分布式一致性, 很多分布式一致性算法都由Paxos演变而来
- 分布式算法 - Raft算法
- Paxos是出了名的难懂,而Raft正是为了探索一种更易于理解的一致性算法而产生的。它的首要设计目的就是易于理解,所以在选主的冲突处理等方式上它都选择了非常简单明了的解决方案
- 分布式算法 - ZAB算法
- ZAB 协议全称:Zookeeper Atomic Broadcast(Zookeeper 原子广播协议), 它应该是所有一致性协议中生产环境中应用最多的了。为什么呢?因为他是为 Zookeeper 设计的分布式一致性协议!
- 分布式算法 - Snowflake算法
- Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割成多个部分,每个部分代表不同的含义。这种就是将64位划分为不同的段,每段代表不同的涵义,基本就是时间戳、机器ID和序列数。为什么如此重要?因为它提供了一种ID生成及生成的思路,当然这种方案就是需要考虑时钟回拨的问题以及做一些 buffer的缓冲设计提高性能。
F. 领域算法之 其它算法汇总:最后概要性的了解常见的其它算法:负载均衡算法,推荐算法,数据挖掘或机器学习算法。因为有其专业性,一般总体上了解就够了。
- 负载均衡算法 - 汇总
- 本文主要介绍常用的负载均衡算法和Nginx中支持的负载均衡算法:轮询法(Round Robin),加权轮询法(Weight Round Robin),平滑加权轮询法(Smooth Weight Round Robin),随机法(Random),加权随机法(Weight Random),源地址哈希法(Hash),最小连接数法(Least Connections)
- 推荐算法 - 汇总
- 本文主要对推荐算法整体知识点做汇总,做到总体的理解;深入理解需要再看专业的材料
- 数据挖掘 - 10大算法汇总
- 国际权威的学术组织the IEEE International Conference on Data Mining (ICDM) 2006年12月评选出了数据挖掘领域的十大经典算法: C4.5, k-Means, SVM, Apriori, EM, PageRank, AdaBoost, kNN, Naive Bayes, and CART
数据库理论与实践
知识体系系统性梳理
数据库基础与理论
相关文章
A. 了解数据库基础和理论知识:在学习数据库之前,不要一上来就是SQL语句;这里建议从数据结构开始切入到数据库,然后再理解数据库是如何工作的,紧接着理解数据库系统的原理知识点和相关知识体系。
- SQL DB - 资料汇总
- SQL DB - 关系型数据库是如何工作的
- 很多人在学习数据库时都是孤立的学习知识点,这样是很难将所有知识点串起来深入理解;强烈推荐你学习两篇文章:Architecture of a Database System以及How does a relational database work;本文主要在第二篇基础上翻译并梳理,如果你英文不好的话,你可以通过本文帮助你构筑数据库体系的基础
- SQL DB - 关系型数据库设计理论
- 在上文了解数据库如何工作后,本节介绍如何将一个关系模型(基于表的数据模型)合理的转化为数据表和关系表,以及确定主外键的。这便是数据库设计理论基础,包括术语,函数依赖,范式等理论基础
- SQL DB - 关系型数据库设计流程
- 在上文知道如何设计表和键后,让我们再看看整个的数据库设计的标准流程吧,主要包括
需求分析,概念结构设计,逻辑结构设计,物理设计,实施阶段和运行和维护阶段这6个阶段
- 在上文知道如何设计表和键后,让我们再看看整个的数据库设计的标准流程吧,主要包括
- SQL DB - 数据库系统核心知识点
- 基于上篇数据库如何工作的基础之上,我们再来梳理下数据库系统中有哪些重要的知识点,包括:事务,并发一致性,封锁,隔离级别,多版本并发控制等
SQL语言基础和进阶
相关文章
B. 完全掌握SQL语言:在了解数据库基础之后,如下章节将重点阐述SQL语言相关的知识;主要顺序是:SQL语法->SQL语句练习->SQL题目进阶->SQL语句优化建议等。
- SQL语言 - SQL语法基础
- 本文包含了所有SQL语言的基础语法,并用例子的方式向你展示
- SQL语言 - SQL语句练习
- 在上文学习了SQL的基本语法以后,本文将通过最经典的“教师-学生-成绩”表来帮助你练习SQL。@pdai
- SQL语言 - SQL题目进阶
- 接下来,通过Leetcode上的SQL题目进行进阶吧
- SQL语言 - SQL语句优化
- 最后,再总结一些SQL语句的优化建议
SQL DB - MySQL数据库
相关文章
C. 掌握MySQL数据库:在理解了SQL语言后,开始进阶MySQL相关的知识点吧(在开始前,建议你完整看一本MySQl相关的书,作为你的知识体系基础);这里不会讲如何安装MySQL或者如何使用,因为这是容易的,而是会关注一些有助于我们构建MySQL相关知识体系的知识点等。
- MySQL - 数据类型
- 本文主要整理MySQL中数据字段类型。
- MySQL - 存储引擎
- 本文主要介绍MySQL中的存储引擎。
- MySQL - 索引(B+树)
- MySQL - 性能优化
- MySQL - 分表分库
- MySQL - 主从复制与读写分离
- MySQL - 一条 SQL 的执行过程详解
- 天天和数据库打交道,一天能写上几十条 SQL 语句,但你知道我们的系统是如何和数据库交互的吗?MySQL 如何帮我们存储数据、又是如何帮我们管理事务?....是不是感觉真的除了写几个 「select * from dual」外基本脑子一片空白?这篇文章就将带你走进 MySQL 的世界,让你彻底了解系统到底是如何和 MySQL 交互的,MySQL 在接受到我们发送的 SQL 语句时又分别做了哪些事情。
- MySQL - MySQL中SQL是如何解析的
- 前文我们分享了一篇文章学习一条SQL是如何在数据库中执行的,其中有一个阶段是SQL的解析。这个阶段对于更全面的SQL优化功能;多维度的慢查询分析;辅助故障分析等都有很大帮助。本文主要介绍一篇美团技术团队关于SQL解析和应用的文章,希望能给一些启示。
- 大厂实践 - 美团: MySQL索引原理及慢查询优化
- 目前常用的 SQL 优化方式包括但不限于:业务层优化、SQL逻辑优化、索引优化等。其中索引优化通常通过调整索引或新增索引从而达到 SQL 优化的目的,索引优化往往可以在短时间内产生非常巨大的效果。本文旨在以开发工程师的角度来解释数据库索引的原理和如何优化慢查询。
- 大厂实践 - 美团: SQL优化工具SQLAdvisor开源
- 正如你在前文中看到的可以通过调整索引或新增索引的索引优化方式,从而达到 SQL 优化的目的。如果能够将索引优化转化成工具化、标准化的流程,减少人工介入的工作量,无疑会大大提高DBA的工作效率。本文主要介绍SQL优化的开源工具SQLAdvisor。
- 大厂实践 - 美团: 基于代价的慢查询优化建议
- 前文我们介绍了优化慢查询最直接有效的方法就是选用一个查询效率高的索引, 也介绍了索引优化工具SQLAdvisor。关于高效率的索引推荐,主要在日常工作中,基于经验规则的推荐随处可见,对于简单的SQL,如
select * from sync_test1 where name like 'Bobby%',直接添加索引IX(name) 就可以取得不错的效果;但对于稍微复杂点的SQL,如select * from sync_test1 where name like 'Bobby%' and dt > '2021-07-06',到底选择IX(name)、IX(dt)、IX(dt,name) 还是IX(name,dt),该方法也无法给出准确的回答。更别说像多表Join、子查询这样复杂的场景了。所以采用基于代价的推荐来解决该问题会更加普适,因为基于代价的方法使用了和数据库优化器相同的方式,去量化评估所有的可能性,选出的是执行SQL耗费代价最小的索引。
- 前文我们介绍了优化慢查询最直接有效的方法就是选用一个查询效率高的索引, 也介绍了索引优化工具SQLAdvisor。关于高效率的索引推荐,主要在日常工作中,基于经验规则的推荐随处可见,对于简单的SQL,如
- 大厂实践 - 美团: MySQL数据库巡检系统的设计与应用
- 巡检工作是保障系统平稳有效运行必不可少的一个环节,目的是能及时发现系统中存在的隐患。我们生活中也随处可见各种巡检,比如电力巡检、消防检查等,正是这些巡检工作,我们才能在稳定的环境下进行工作、生活。巡检对于数据库或者其他IT系统来说也同样至关重要,特别是在降低风险、提高服务稳定性方面起到了非常关键作用。本文介绍了美团MySQL数据库巡检系统的框架和巡检内容,希望能够帮助大家了解什么是数据库巡检,美团的巡检系统架构是如何设计的,以及巡检系统是如何保障MySQL服务稳定运行的。
NoSQL DB - Redis详解
D. 掌握Redis数据库:在理解了关系型数据库后,开始进阶最为常用的KV库Redis,一些大厂都在使用,面试也必问。
知识体系
相关文章
首先,我们通过学习Redis的概念基础,了解它适用的场景。
- Redis入门 - Redis概念和基础
- Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
其次,这些适用场景都是基于Redis支持的数据类型的,所以我们需要学习它支持的数据类型;同时在redis优化中还需要对底层数据结构了解,所以也需要了解一些底层数据结构的设计和实现。
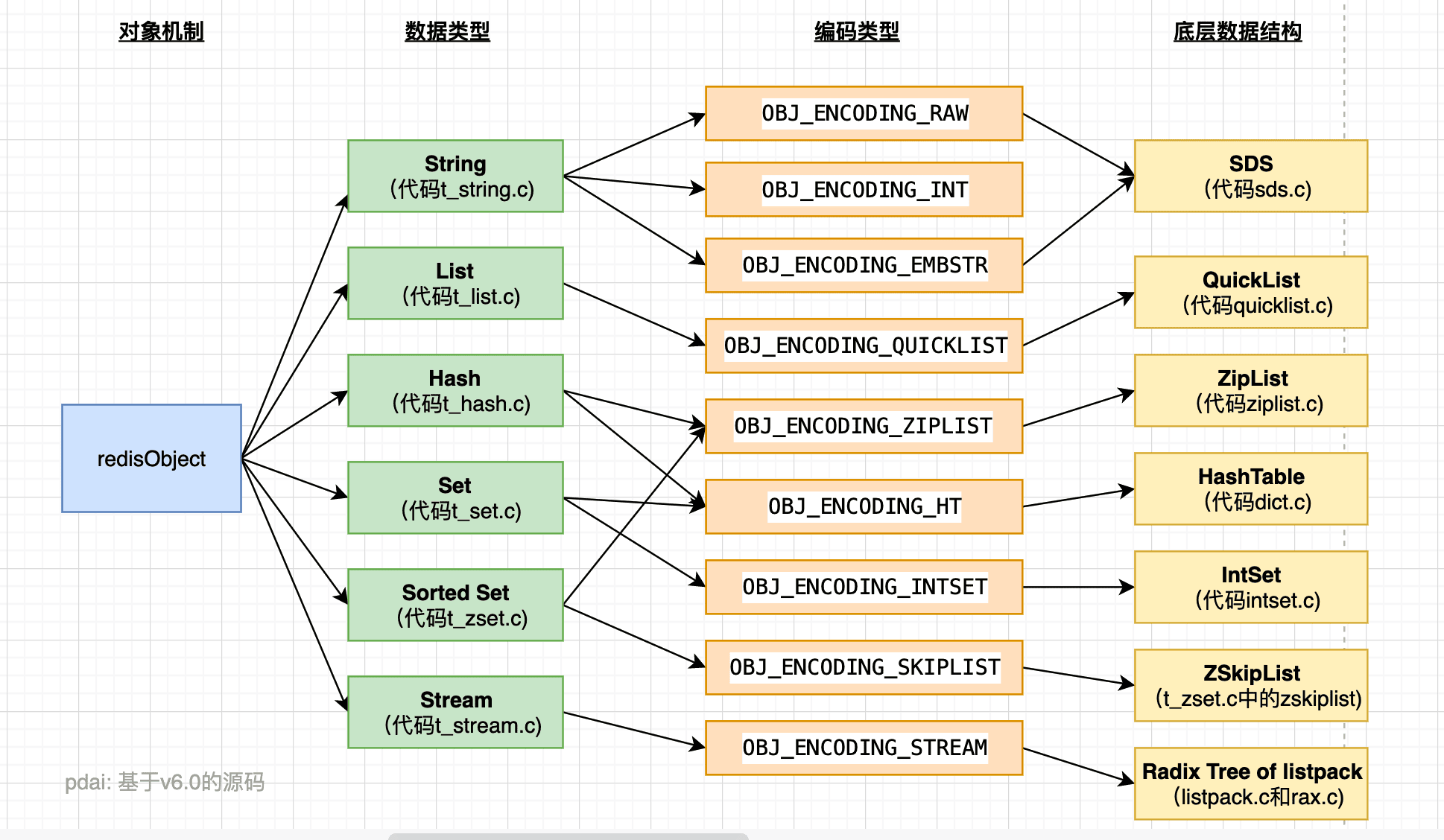
- Redis入门 - 数据类型:5种基础数据类型详解
- Redis所有的key(键)都是字符串。我们在谈基础数据结构时,讨论的是存储值的数据类型,主要包括常见的5种数据类型,分别是:String、List、Set、Zset、Hash
- Redis入门 - 数据类型:3种特殊类型详解
- Redis除了上文中5种基础数据类型,还有三种特殊的数据类型,分别是 HyperLogLogs(基数统计), Bitmaps (位图) 和 geospatial (地理位置)
- Redis入门 - 数据类型:Stream详解
- Redis5.0 中还增加了一个数据结构Stream,它借鉴了Kafka的设计,是一个新的强大的支持多播的可持久化的消息队列。
- Redis进阶 - 底层数据结构:对象机制详解
- 我们在前文已经阐述了Redis 5种基础数据类型详解,分别是字符串(string)、列表(list)、哈希(hash)、集合(set)、有序集合(zset),以及5.0版本中Redis Stream结构详解;那么这些基础类型的底层是如何实现的呢?Redis的每种对象其实都由对象结构(redisObject) 与 对应编码的数据结构组合而成, 本文主要介绍对象结构(redisObject) 部分。。
- Redis进阶 - 底层数据结构:底层数据结构详解
- 前文是第一部分底层设计:对象机制详解, 本文主要介绍底层数据结构 部分。
- Redis进阶 - 底层数据结构:redis对象与编码(底层结构)对应关系详解
- 在学习完底层数据结构之后,我们终于可以结合前文内容阐述redis对象及编码之间的关系了。
再者,需要学习Redis支持的核心功能,包括持久化,消息,事务,高可用;高可用方面包括,主从,哨兵等;高可拓展方面,比如 分片机制等。
- Redis进阶 - 持久化:RDB和AOF机制详解
- 为了防止数据丢失以及服务重启时能够恢复数据,Redis支持数据的持久化,主要分为两种方式,分别是RDB和AOF; 当然实际场景下还会使用这两种的混合模式。
- Redis进阶 - 消息传递:发布订阅模式详解
- Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
- Redis进阶 - 事件:Redis事件机制详解
- Redis 采用事件驱动机制来处理大量的网络IO。它并没有使用 libevent 或者 libev 这样的成熟开源方案,而是自己实现一个非常简洁的事件驱动库 ae_event。
- Redis进阶 - 事务:Redis事务详解
- Redis 事务的本质是一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
- Redis进阶 - 高可用:主从复制详解
- 我们知道要避免单点故障,即保证高可用,便需要冗余(副本)方式提供集群服务。而Redis 提供了主从库模式,以保证数据副本的一致,主从库之间采用的是读写分离的方式。本文主要阐述Redis的主从复制。
- Redis进阶 - 高可用:哨兵机制(Redis Sentinel)详解
- 在上文主从复制的基础上,如果注节点出现故障该怎么办呢? 在 Redis 主从集群中,哨兵机制是实现主从库自动切换的关键机制,它有效地解决了主从复制模式下故障转移的问题。
- Redis进阶 - 高可拓展:分片技术(Redis Cluster)详解
- 前面两篇文章,主从复制和哨兵机制保障了高可用,就读写分离而言虽然slave节点来扩展主从的读并发能力,但是写能力和存储能力是无法进行扩展的,就只能是master节点能够承载的上限。如果面对海量数据那么必然需要构建master(主节点分片)之间的集群,同时必然需要吸收高可用(主从复制和哨兵机制)能力,即每个master分片节点还需要有slave节点,这是分布式系统中典型的纵向扩展(集群的分片技术)的体现;所以在Redis 3.0版本中对应的设计就是Redis Cluster。
最后,就是具体的实践以及实践中遇到的问题和解决方法了:在不同版本中有不同特性,所以还需要了解版本;以及性能优化,大厂实践等。
- Redis进阶 - 缓存问题:一致性, 穿击, 穿透, 雪崩, 污染等
- Redis最常用的一个场景就是作为缓存,本文主要探讨作为缓存,在实践中可能会有哪些问题?比如一致性, 穿击, 穿透, 雪崩, 污染等
- Redis进阶 - 版本特性: Redis4.0、5.0、6.0特性整理
- 在学习Redis知识体系时,我们难免会需要查看版本实现之间的差异,本文主要整理Redis较为新的版本的特性。
- Redis进阶 - 运维监控:Redis的监控详解
- Redis实战中包含开发,集群 和 运维,Redis用的好不好,如何让它更好,这是运维要做的;本文主要在 Redis自身状态及命令,可视化监控工具,以及Redis监控体系等方面帮助你构建对redis运维/监控体系的认知,它是性能优化的前提。
- Redis进阶 - 性能调优:Redis性能调优详解
- Redis 的性能问题,涉及到的知识点非常广,几乎涵盖了 CPU、内存、网络、甚至磁盘的方方面面;同时还需要对上文中一些基础或底层有详细的了解。针对Redis的性能调优,这里整理分享一篇水滴与银弹(公众号)的文章,这篇文章可以帮助你构筑Redis性能调优的知识体系。
- Redis大厂经验 - 微博:万亿级日访问量下,Redis在微博的9年优化历程
- 再分享一篇微博使用redis的经验的文章,因为Redis在微博内部分布在各个应用场景,比如像现在春晚必争的“红包飞”活动,还有像粉丝数、用户数、阅读数、转评赞、评论盖楼、广告推荐、负反馈、音乐榜单等等都有用到Redis;我们可以通过大厂使用redis的经验来强化对redis使用上的认知。
NoSQL DB - MongoDB详解
E. 掌握MongoDB数据库:在理解了Redis后,让我们认识NoSQL数据库中最为常用的MongoDB;它在后期版本中更换了证书,使用时需要注意下;但是不妨碍我们学习。
MongoDB学习引入
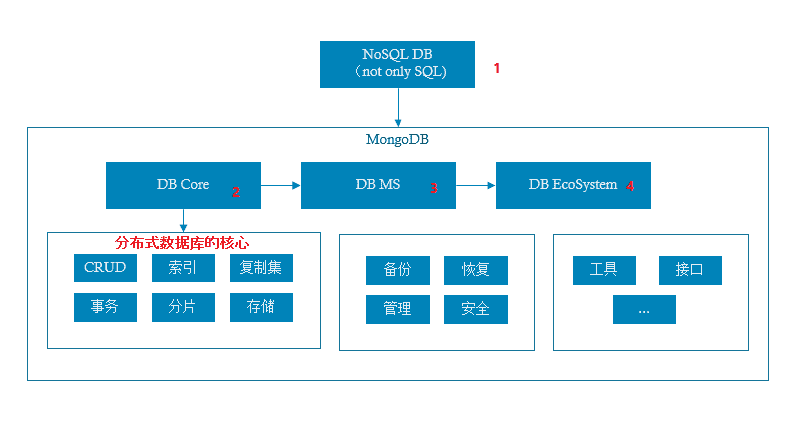
MongoDB生态
1. MongoDB引入和生态介绍: 首先了解NoSQL基本的概念以及MongoDB基础概念,进而引入MongoDB的生态。
- Mongo入门 - MongoDB基础概念
- 在学习MongoDB之前先简单了解相关概念。
- Mongo入门 - MongoDB整体生态
- 很多人在学习Mongo时仅仅围绕着数据库功能,围绕着CRUD和聚合操作,但是MongoDB其实已经基本形成了它自身的生态了。我们在学习一项技能时一定要跳出使用的本身,要从高一点的格局上了解整个生态,这样会对你构筑知识体系有很大的帮助。。
2. MongoDB入门 - 基本使用: 开始学习MongoDB安装,使用等。
- Mongo入门 - 基本使用:安装和CRUD
- 在理解MongoDB基础概念后,本文将介绍MongoDB的安装和最基本的CURD操作。
- Mongo入门 - 基本使用:索引和聚合
- 在了解MongoDB的基本CRUD操作后,常用的其它操作还有对字段的索引以及对字段的聚合操作。
- Mongo入门 - 基本使用:效率工具
- 本文将主要介绍常用的MongoDB的工具,这些工具可以极大程度的提升你的效率。
- Mongo入门 - 基本使用:Java 低阶API
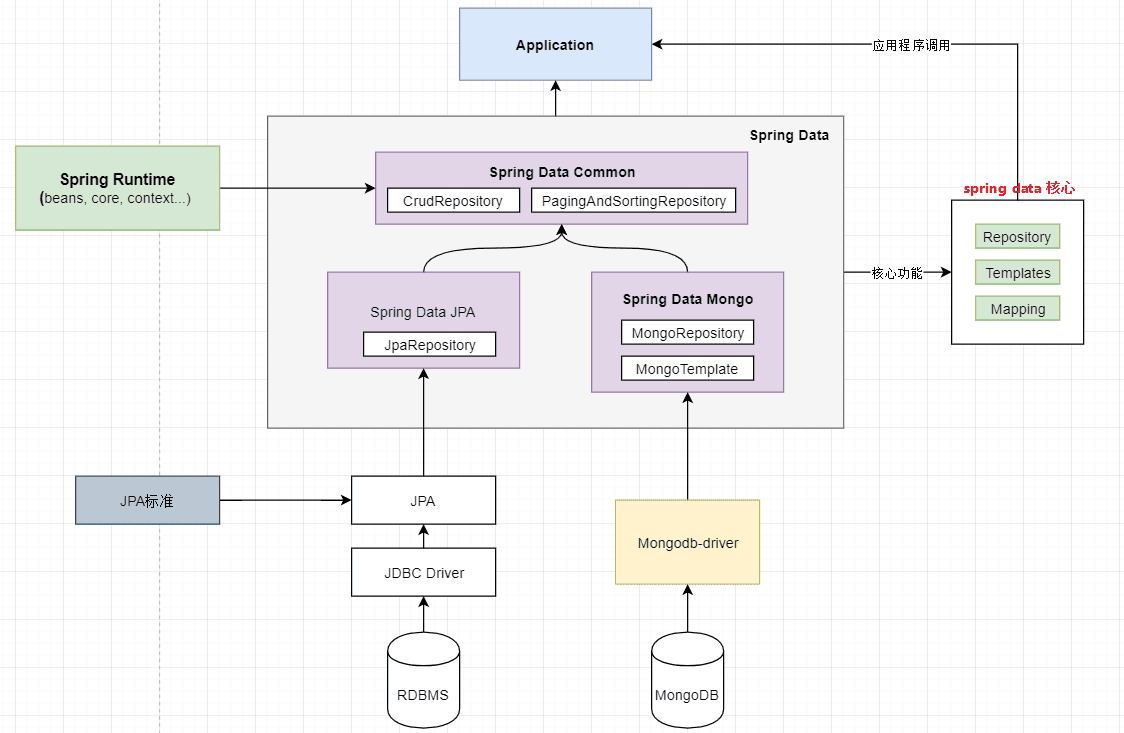
- 本文为低优先级,只是向你介绍下MongoDB提供的原生的JavaAPI;而大多数公司使用Spring框架,会使用Spring Data对MongoDB原生API的封装,比如JPA,MongoTemplate等。
- Mongo入门 - 基本使用:Spring Data + Mongo
- 本文为主要介绍Spring Data对MongoDB原生API的封装,比如JPA,MongoTemplate等。以及原生API和Spring data系列之间的关系。
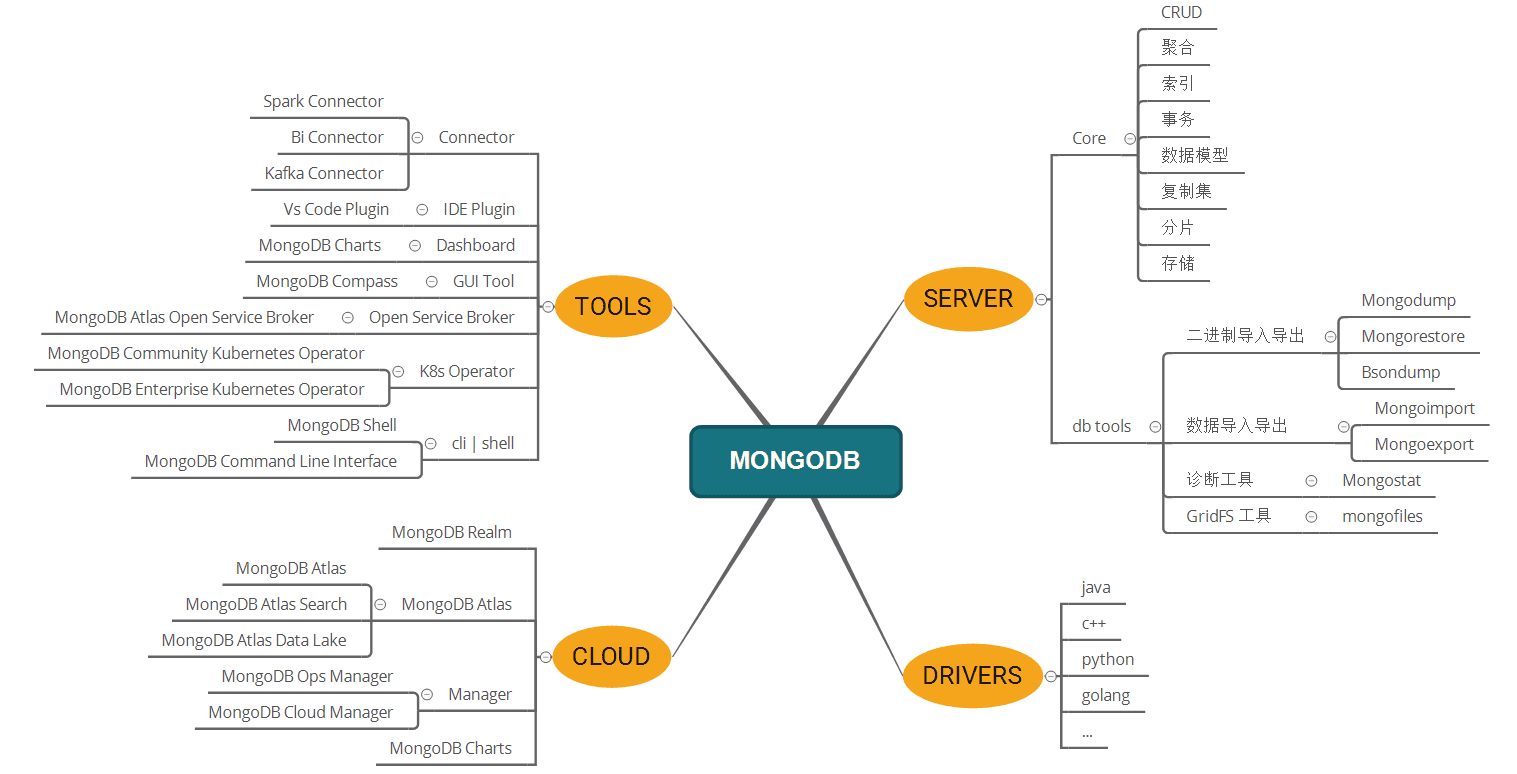
3. MongoDB进阶 - 原理和WiredTigger存储引擎: 在学习完常用的基础之后,我们再看下MongoDB的原理和WiredTigger存储引擎。
- Mongo进阶 - MongoDB体系结构
- 上面章节已经对MongoDB生态中工具以及使用有了基础,后续文章我们将开始理解MongoDB是如何支撑这些功能的。我们将从最基本的MongoDB的体系结构开始介绍,主要包括
MongoDB的包结构,MongoDB的数据逻辑结构,MongoDB的数据文件结构。其中围绕着MongoDB的数据文件结构,将为我们后续介绍MongoDB的存储引擎详解打下基础。
- 上面章节已经对MongoDB生态中工具以及使用有了基础,后续文章我们将开始理解MongoDB是如何支撑这些功能的。我们将从最基本的MongoDB的体系结构开始介绍,主要包括
- Mongo进阶 - 原理和WiredTiger引擎
- 开始初步了解MongoDB实现原理和WiredTiger引擎。
- Mongo进阶 - WT引擎:数据结构
- MongoDB的WiredTiger存储引擎背后采用了什么样的数据结构呢?本文将从
常见引擎数据结构,典型B-Tree数据结构,磁盘数据结构,内存数据结构,Page数据结构等方面详解介绍。。
- MongoDB的WiredTiger存储引擎背后采用了什么样的数据结构呢?本文将从
- Mongo进阶 - WT引擎:Page生命周期
- 通过前文我们了解到数据以page为单位加载到cache; 有必要系统的分析一页page的生命周期、状态以及相关参数的配置,这对后续MongoDB的性能调优和故障问题的定位和解决有帮助。
- Mongo进阶 - WT引擎:checkpoint原理
- Checkpoint主要有两个目的: 一是将内存里面发生修改的数据写到数据文件进行持久化保存,确保数据一致性;二是实现数据库在某个时刻意外发生故障,再次启动时,缩短数据库的恢复时间,WiredTiger存储引擎中的Checkpoint模块就是来实现这个功能的。
4. MongoDB进阶 - 数据库核心知识点: 再者我们还学要进一步学习MongoDB的核心知识点。
- Mongo进阶 - DB核心:索引实现
- 数据库核心知识点之索引
- Mongo进阶 - DB核心:复制集
- 数据库核心知识点之复制集
- Mongo进阶 - DB核心:分片Sharding
- 数据库核心知识点之复分片Sharding
- Mongo进阶 - DB核心:备份恢复
- 数据库核心知识点之备份恢复
5. MongoDB进阶 - 数据模型设计: 在真正使用中,需要知道如何设计数据模型。
- Mongo进阶 - 系统设计:数据模型
- MongoDB使用文档数据模型。
- Mongo进阶 - 系统设计:模式构建
- MongoDB使用文档数据模型具有内在的灵活性,允许数据模型支持你的应用程序需求, 灵活性也可能导致模式比它们应有样子的更复杂。这涉及到如何在MongoDB中设计数据库模式(schema),有一个严峻的现实,大多数性能问题都可以追溯到糟糕的模式设计。
6. MongoDB进阶 - 性能优化: 最后基于上述知识点,我们再了解下常见的性能优化的方式。
- Mongo进阶 - 性能:查询聚合优化
- 在MongoDB中通过查询聚合语句分析定位慢查询/聚合分析
NoSQL DB - ElasticSearch
E. 掌握ElasticSearch数据库:在理解了MongoDB后,让我们再学习下搜索的索引库;日志收集ELK栈是非常常见的,同时在一些离线大数据分析中也经常使用。
相关文章
首先,我们通过学习ElasticSearch的概念基础,了解Elastic Stack生态和场景方案。
- ES详解 - 认知:ElasticSearch基础概念
- 在学习ElasticSearch之前,先简单了解下ES流行度,使用背景,以及相关概念等
- ES详解 - 认知:Elastic Stack生态和场景方案
- 在了解ElaticSearch之后,我们还要了解Elastic背后的生态即我们常说的ELK;与此同时,还会给你展示ElasticSearch的案例场景,让你在学习ES前对它有个全局的印象。
然后,搭建ElasticSearch和Kibana,进而从查询和聚合的角度入门学习。
- ES详解 - 安装:ElasticSearch和Kibana安装
- 了解完ElasticSearch基础和Elastic Stack生态后,我们便可以开始学习使用ElastiSearch了。所以本文主要介绍ElasticSearch和Kibana的安装。
- ES详解 - 入门:查询和聚合的基础使用
- 安装完ElasticSearch 和 Kibana后,为了快速上手,我们通过官网GitHub提供的一个数据进行入门学习,主要包括查询数据和聚合数据。
入门后,需要从两大方面深入ElasticSearch常用功能:第一方面是索引管理;第二方面是查询和聚合。
- ES详解 - 索引:索引管理详解
- 了解基本使用后,我们从索引操作的角度看看如何对索引进行管理。
- ES详解 - 索引:索引模板(Index Template)详解
- 前文介绍了索引的一些操作,特别是手动创建索引,但是批量和脚本化必然需要提供一种模板方式快速构建和管理索引,这就是本文要介绍的索引模板(Index Template),它是一种告诉Elasticsearch在创建索引时如何配置索引的方法。为了更好的复用性,在7.8中还引入了组件模板。
- ES详解 - 查询:DSL查询之复合查询详解
- 在查询中会有多种条件组合的查询,在ElasticSearch中叫复合查询。它提供了5种复合查询方式:bool query(布尔查询)、boosting query(提高查询)、constant_score(固定分数查询)、dis_max(最佳匹配查询)、function_score(函数查询)。
- ES详解 - 查询:DSL查询之全文搜索详解
- DSL查询极为常用的是对文本进行搜索,我们叫全文搜索,本文主要对全文搜索进行详解。
- ES详解 - 查询:DSL查询之Term详解
- DSL查询另一种极为常用的是对词项进行搜索,官方文档中叫”term level“查询,本文主要对term level搜索进行详解。
- ES详解 - 聚合:聚合查询之Bucket聚合详解
- 除了查询之外,最常用的聚合了,ElasticSearch提供了三种聚合方式: 桶聚合(Bucket Aggregation),指标聚合(Metric Aggregation) 和 管道聚合(Pipline Aggregation),本文主要介绍桶聚合(Bucket Aggregation)。
- ES详解 - 聚合:聚合查询之Metric聚合详解
- 前文主要讲了 ElasticSearch提供的三种聚合方式之桶聚合(Bucket Aggregation),本文主要讲讲指标聚合(Metric Aggregation)。
- ES详解 - 聚合:聚合查询之Pipline聚合详解
- 前文主要讲了 ElasticSearch提供的三种聚合方式之指标聚合(Metric Aggregation),本文主要讲讲管道聚合(Pipeline Aggregation)。
进一步进阶,了解并深入ElasticSearch底层的原理等。
- ES详解 - 原理:从图解构筑对ES原理的初步认知
- 在学习ElasticSearch原理时,我推荐你先通过官方博客中的一篇图解文章(虽然是基于2.x版本)来构筑对ES的初步认知(这种认识是体系上的快速认知)。
- ES详解 - 原理:ES原理知识点补充和整体结构
- 通过上文图解了解了ES整体的原理后,我们便可以基于此知识体系下梳理下ES的整体结构以及相关的知识点, 这将帮助你更好的ElasticSearch索引文档和搜索文档的原理。
- ES详解 - 原理:ES原理之索引文档流程详解
- ElasticSearch中最重要原理是文档的索引和文档的读取,本文带你理解ES文档的索引过程。
- ES详解 - 原理:ES原理之读取文档流程详解
- ElasticSearch中最重要原理是文档的索引和文档的读取,前文介绍了索引文档流程,本文带你理解ES文档的读取过程。
最后,学习ElasticSearch实践,大厂经验,运维,资料等。
- ES详解 - 优化:ElasticSearch性能优化详解
- Elasticsearch 作为一个开箱即用的产品,在生产环境上线之后,我们其实不一定能确保其的性能和稳定性。如何根据实际情况提高服务的性能,其实有很多技巧。这章我们分享从实战经验中总结出来的 elasticsearch 性能优化,主要从硬件配置优化、索引优化设置、查询方面优化、数据结构优化、集群架构优化等方面讲解。
- ES详解 - 大厂实践:腾讯万亿级 Elasticsearch 技术实践
- 腾讯在ES优化上非常具备参考价值,本文来源于腾讯相关团队的技术分享。Elasticsearch 在腾讯内部广泛应用于日志实时分析、结构化数据分析、全文检索等场景,目前单集群规模达到千级节点、万亿级吞吐,同时腾讯联合 Elastic 公司在腾讯云上提供了内核增强版 ES 云服务。海量规模、丰富的应用场景推动着腾讯对原生 ES 进行持续的高可用、高性能、低成本等全方位优化。本次分享主要剖析腾讯对 Elasticsearch 海量规模下的内核优化与实践,希望能和广大 ES 爱好者共同探讨推动 ES 技术的发展。
- ES详解 - 资料:Awesome Elasticsearch
- 本文来自 GitHub Awesome Elasticsearch 项目, 搜集ElasticSearch相关的优秀资料。
- ElasticSearch - WrapperQuery
- ElasticSearch - 备份和迁移
开发与常用基础
知识体系系统性梳理
开发之常用类库
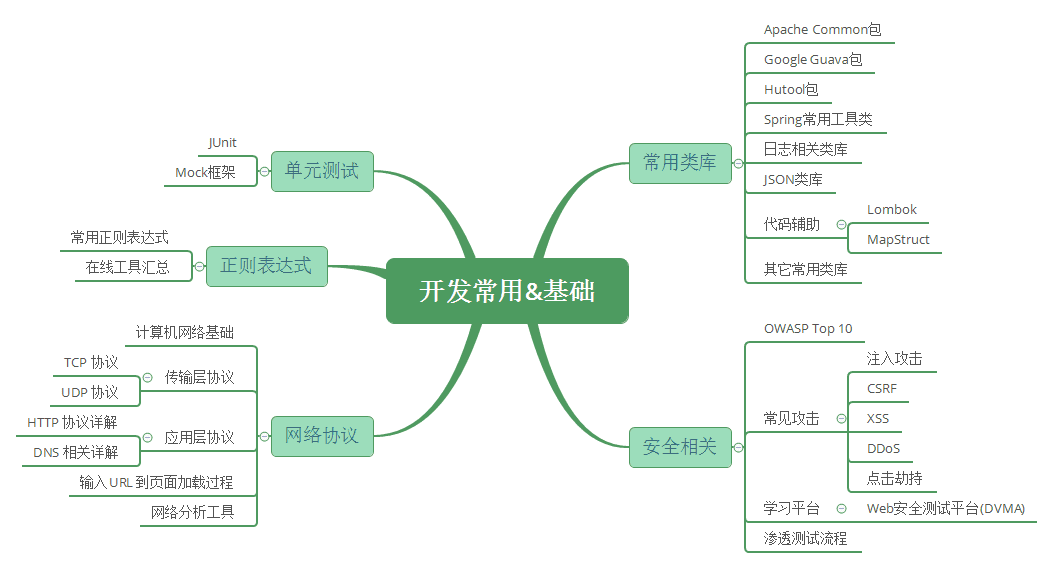
A. 开发之常用类库:区别于学习,在开发应用时正确使用一些开源第三方工具包可以极大的提升开发效率,本章主要介绍运用极为广泛的工具包,比如Apache Common,Google Guava,Hutool等。
相关文章
- 常用类库 - Apache Common包
- 工具类第一选择1 - Apache common包不仅被成千上万开源工具使用,更是学习Java编程比较好的代码参考工具,效率工具。
- 常用类库 - Google Guava包
- 工具类第一选择2- Google出品,必属精品。
- 常用类库 - Hutool包
- 国产的工具类库,优点是比较全,也比较实用;选它要注意下它的协议是中国第一个开源协议木兰宽松许可证, 第1版,商业型项目最好咨询下相关法务部门。
- 常用类库 - Spring常用工具类
- Spring作为常用的开发框架,在Spring框架应用中,排在ApacheCommon,Guava, Huool等通用库后,第二优先级可以考虑使用Spring-core-xxx.jar中的util包。
- 常用类库 - 日志相关类库详解
- Java日志库是最能体现Java库在进化中的渊源关系的,在理解时重点理解日志框架本身和日志门面,以及比较好的实践等。要关注其历史渊源和设计(比如桥接),而具体在使用时查询接口即可。
- 常用类库 - JSON类库详解
- JSON应用非常广泛,对常用对FastJson,Jackson和Gson作了具体阐述;其中考虑到FastJson代码质量,漏洞,坑等等,应该尽量避免使用。
- 常用类库 - Lombok工具库详解
- Lombok是一款非常实用Java工具,可用来帮助开发人员消除Java的冗长代码,尤其是对于简单的Java对象(POJO)。实际上我并不推荐使用Lombok(不主动使用它), 但是因为它有着很大的使用量,我们仍然有必要掌握它,不仅知道如何使用和它解决的问题,还要知道它的坑。
- 常用类库 - MapStruct工具库详解
- MapStruct是一款非常实用Java工具,主要用于解决对象之间的拷贝问题,比如PO/DTO/VO/QueryParam之间的转换问题。区别于BeanUtils这种通过反射,它通过编译器编译生成常规方法,将可以很大程度上提升效率。
- 常用类库 - 其它常用类库
- 其它常用类库体系很庞大,但是工具类的原则是只需要查找会使用即可。
开发之代码质量保障
B1. 开发之单元测试:单元测试是从开发侧保证软件质量的第一步,本章将具体介绍单元测试相关的内容和工具,比如Junit,Mockito等。
- 单元测试:浅谈单元测试
- 单元测试(unit testing),是指对软件中的最小可测试单元进行检查和验证。这是基础,所以围绕着单元测试,我从网上搜集和总结了相关的概念,以助你完善体系。
- 单元测试:Junit4 详解
- JUint是Java编程语言的单元测试框架,用于编写和运行可重复的自动化测试。本文主要针对Junit4要点进行梳理总结。
- 单元测试:Junit5 详解
- JUnit 5是JUnit的下一代。目标是为JVM上的开发人员端测试创建一个最新的基础。这包括专注于Java 8及更高版本,以及启用许多不同风格的测试。
- 单元测试:Mockito 详解
- Mock通常是指,在测试一个对象A时,我们构造一些假的对象来模拟与A之间的交互,而这些Mock对象的行为是我们事先设定且符合预期。通过这些Mock对象来测试A在正常逻辑,异常逻辑或压力情况下工作是否正常。而Mockito是最流行的Java mock框架之一。
- 单元测试:IDEA下单元测试详解
- 工欲善其事必先利其器,我们在写单元测试一定要使用工具,这将能大幅度提升编码的效率。本文以IDEA为例,看看如何利用插件提升效率。
- 单元测试 - SpringBoot2+Mockito实战
- 在真实的开发中,我们通常是使用SpringBoot的,目前SpringBoot是v2.4.x的版本(SpringBoot 2.2.2.RELEASE之前默认是使用 JUnit4,之后版本默认使用Junit5);所以我们写个基于SpringBoot2.4+H2的内存库的简单例子,同时加点必要的单元测试。
B2. 开发之代码质量:项目的代码通常是一个团队共同完成的,要保障代码质量的首要前提就是统一代码的风格,命名规范,静态代码检查等等。
- 代码质量 - 统一风格:统一代码格式化详解
- 项目的代码通常是一个团队共同完成的,要保障代码质量的首要前提就是统一代码的风格,本文将介绍常用的统一风格的措施之统一代码格式化。
- 代码质量 - 统一风格:统一命名规范详解
- 好的代码本身就是注释, 所以我们需要统一命名风格,本文将介绍常用的统一风格的措施之统一命名规范。
- 代码质量 - 统一风格:静态样式检查详解
- 统一样式检查规范里,最为常用的统一样式工具是checkstyle插件,本文将介绍常用的统一风格的措施之静态样式检查。
- 代码质量 - 代码质量管理: Sonarlint插件详解
- 在提交代码前,为提升代码质量还需要使用一些静态代码工具检查代码质量,最为常用的是Sonar;在本地IDE中可以配置Sonarlint插件进行检查。
- 代码质量 - 代码质量管理: SpotBugs插件详解
- SpotBugs是Findbugs的继任者(Findbugs已经于2016年后不再维护),用于对代码进行静态分析,查找相关的漏洞;在本地IDE中可以配置SpotBugs插件进行检查。
开发之正则表达式
C. 开发之正则表达式:正则表达式运用极为广泛,但是知识点又多;在学习时,总体上理解,对常用的知悉,开发时可以快速查询使用即可。
相关文章
- 正则表达式 - 知识点学习
- 正则表达式的语法知识点
- 正则表达式 - 常用正则表达式
- 常用的正则表达式,供使用时查询
- 正则表达式 - 在线工具汇总
- 主要总结常用的在线正则表达式相关的工具,从而高效的写出正确的表达式。
开发之CRON表达式
D. 开发之CRON表达式:定时任务和CRON表达式在开发中使用也非常广泛;在学习时,总体上理解,对常用的知悉,开发时可以快速查询使用即可。
相关文章
- CRON表达式 - CRON表达式介绍和使用
- 定时任务和CRON表达式在开发中使用也非常广泛,本文整理了CRON表达式和常见使用例子
- CRON表达式 - CRON生成和校验工具
- 本文主要总结常用的在线CRON生成和校验工具,从而高效的写出正确的表达式
开发之网络协议
E. 开发之网络协议:对Web开发而言,网络协议是必学项,本章主要对常见的网络协议进行梳理,并重点分析常用TCP/IP协议等,这篇网络基础和协议 - Overview将指导你如何学习这个系列。
相关文章
第一步:学习计算机网络基础;构筑任何基础体系之前,需要学习这个专题的整体知识点(最好是一本完整的书),这里主要基于
《计算机网络(第五版)》知识点梳理,不得不说这本书作者谢希仁画的PPT还是挺棒的。网络基础分三部分内容,主要包含如下:
- 网络基础之一 - 计算机网络基础部分梳理
- 网络基础的第一篇,主要来源于大学的课程《计算机网络(第五版)》知识点梳理,内容整理自这里, 但是作了调整和优化; 不得不说这本书作者谢希仁画的PPT还是挺棒的。
- 网络基础之二 - 网络7层协议,4层,5层
- 网络基础的第二篇,我觉的一定要有全局框架观,构建全局观时建议分三步:第一步,理解全局的网络层次;第二步,理解每一层次中的常见的网络设备及功能;第三步,理解每一层中的常见协议。在此基础上,将其它知识点放置在相应的层次(很多网络上的零散知识点是没法帮你构筑完整的知识体系的,推荐你完整的看一本关于网络的书籍来构筑基础)
- 网络基础之三 - IP 协议相关详解
- 网络基础第三篇,主要阐述:
IP协议(在网络层)及其配套协议(在数据链路层的ARP协议,在网络层的ICMP,IGMP协议,IPV6详解,网络地址转换 NAT等。
- 网络基础第三篇,主要阐述:
第二步:学习传输层协议TCP/UDP;TCP/UDP是后面应用层协议的基础。
- 网络协议 - TCP 协议详解
- TCP是一个巨复杂的协议,关于TCP这个协议的细节,我还是推荐你去看W.Richard Stevens的《TCP/IP 详解 卷1:协议》。全网上讲TCP/IP的文章众多,多数是皮毛;本文梳理自 左耳朵耗子的文章《TCP 的那些事儿》,来帮助大家理解TCP/IP, 其中引用的图片在这里
- 网络协议 - UDP 协议详解
- 基于TCP和UDP的协议非常广泛,所以也有必要对UDP协议进行详解
第三步:学习应用层协议;HTTP 基于TCP协议实现,web开发必学;DNS 基于UDP协议实现。
- 网络协议 - HTTP 协议详解
- HTTP 协议详解,web开发必备
- 网络协议 - DNS 相关详解
- DNS的核心工作就是将域名翻译成计算机IP地址, 它是基于UDP协议实现的,本文将具体阐述DNS相关的概念,解析,调度原理(负载均衡和区域调度)等DNS相关的所有知识点
第四步:知识点贯穿理解;
- 知识点串联:输入URL 到页面加载过程详解
- 第一,将前面涉及网络协议特别是
TCP协议和HTTP协议,DNS解析等等知识点贯穿; - 第二,在此基础上介绍
浏览器渲染过程,以及为Web优化提供基础。
- 第一,将前面涉及网络协议特别是
第五步:相关工具等;
- 工具: netstat查看服务及监听端口详解
- 在Linux使用过程中,需要了解当前系统开放了哪些端口,并且要查看开放这些端口的具体进程和用户,可以通过netstat命令进行简单查询。
- 工具: 网络抓包神器 tcpdump 使用详解
- tcpdump 是一款强大的网络抓包工具,它使用 libpcap 库来抓取网络数据包,这个库在几乎在所有的 Linux/Unix 中都有。熟悉 tcpdump 的使用能够帮助你分析调试网络数据,本文将通过一个个具体的示例来介绍它在不同场景下的使用方法。。
- 工具: Wireshark介绍及抓包分析
- Wireshark(前称Ethereal)是一个网络封包分析软件.网络管理员使用Wireshark来检测网络问题,网络安全工程师使用Wireshark来检查资讯安全相关问题,开发者使用Wireshark来为新的通讯协定除错,普通使用者使用Wireshark来学习网络协定的相关知识。
开发之安全相关
F. 开发之安全相关:保障开发出的软件安全是非常重要的,本章主要对开发知识体系,OWASP Top 10梳理,以及对常见的漏洞进行详解; 这篇开发安全 - Overview将指导你如何学习这个系列。
相关文章
第一步:业内趋势和常见漏洞;在学习安全需要总体了解安全趋势和常见的Web漏洞,首推了解OWASP,因为它代表着业内Web安全漏洞的趋势
- 开发安全 - OWASP Top 10
- OWASP(开放式web应用程序安全项目)关注web应用程序的安全。OWASP这个项目最有名的,也许就是它的"十大安全隐患列表"。这个列表不但总结了web应用程序最可能、最常见、最危险的十大安全隐患,还包括了如何消除这些隐患的建议。(另外,OWASP还有一些辅助项目和指南来帮助IT公司和开发团队来规范应用程序开发流程和测试流程,提高web产品的安全性。)这个"十大"差不多每隔三年更新一次。。
第二步:重点知识点详解;这里将具体对常见对几种攻击方式进行阐述,包括注入攻击,CSRF,XSS等。
- 开发安全 - 注入攻击详解
- 注入攻击最为常见的攻击方式,作为开发而言必须完全避免; 本文会介绍常见的几种注入方式,比如:
SQL 注入,xPath 注入,命令注入,LDAP注入,CLRF注入,Host头注入,Email头注入等等,总结来看其本质其实是一样的,且防御措施也大同小异。
- 注入攻击最为常见的攻击方式,作为开发而言必须完全避免; 本文会介绍常见的几种注入方式,比如:
- 开发安全 - CSRF 详解
- CSRF(Cross-site request forgery跨站请求伪造,也被称成为“one click attack”或者session riding,通常缩写为CSRF或者XSRF,是一种对网站的恶意利用。
- 开发安全 - XSS 详解
- XSS是跨站脚本攻击(Cross Site Scripting),为不和层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,故将跨站脚本攻击缩写为XSS。恶意攻击者往Web页面里插入恶意Script代码,当用户浏览该页之时,嵌入其中Web里面的Script代码会被执行,从而达到恶意攻击用户的目的
- 开发安全 - DDoS 详解
- 分布式拒绝服务攻击(英文意思是Distributed Denial of Service,简称DDoS)是指处于不同位置的多个攻击者同时向一个或数个目标发动攻击,或者一个攻击者控制了位于不同位置的多台机器并利用这些机器对受害者同时实施攻击。由于攻击的发出点是分布在不同地方的,这类攻击称为分布式拒绝服务攻击,其中的攻击者可以有多个
- 开发安全 - 点击劫持详解
- 点击劫持其实是一种视觉上的欺骗手段,攻击者将一个透明的、不可见的iframe覆盖在一个网页上,通过调整iframe页面位置,诱使用户在页面上进行操作,在不知情的情况下用户的点击恰好是点击在iframe页面的一些功能按钮上
第三步:学习和实践:一个比较好对学习常见web漏洞的平台 - Web安全测试平台(DVMA)
- 开发安全实战 - Web安全测试平台(DVMA)
- DVWA(Damn Vulnerable Web Application)是一个用来进行安全脆弱性鉴定的PHP/MySQL Web应用,旨在为安全专业人员测试自己的专业技能和工具提供合法的环境,帮助web开发者更好的理解web应用安全防范的过程。
第四步:渗透测试:用渗透测试的整个流程,帮你理解项目发布时安全团队如何做渗透测试来尽量避免漏洞
- 开发安全实战 - 渗透测试流程示例
- 在应用程序上线之前,都会进行多次内部或者外部的渗透测试。对于开发而言,有必要了解下渗透测试的整体流程,从而知己知彼,避免一些开发中的问题
框架与中间件
包含各类常见的中间件和开发框架等。@pdai
Web容器 - Tomcat详解
结构图
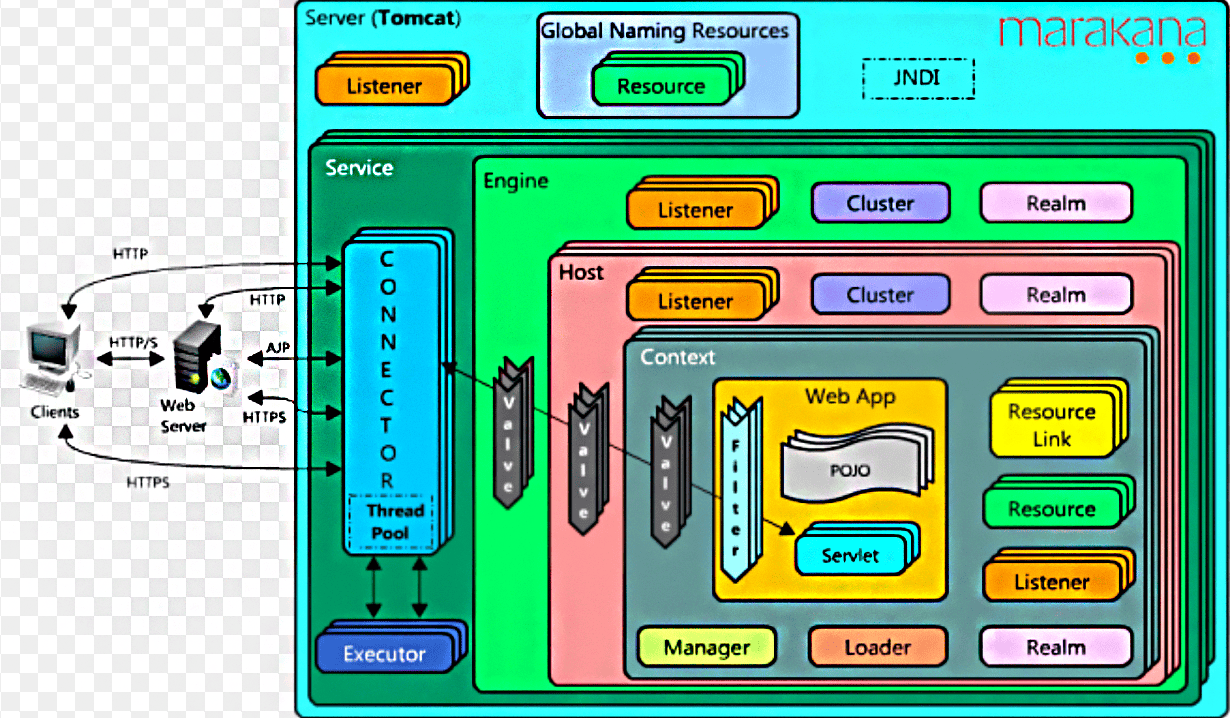
初始化和启动流程
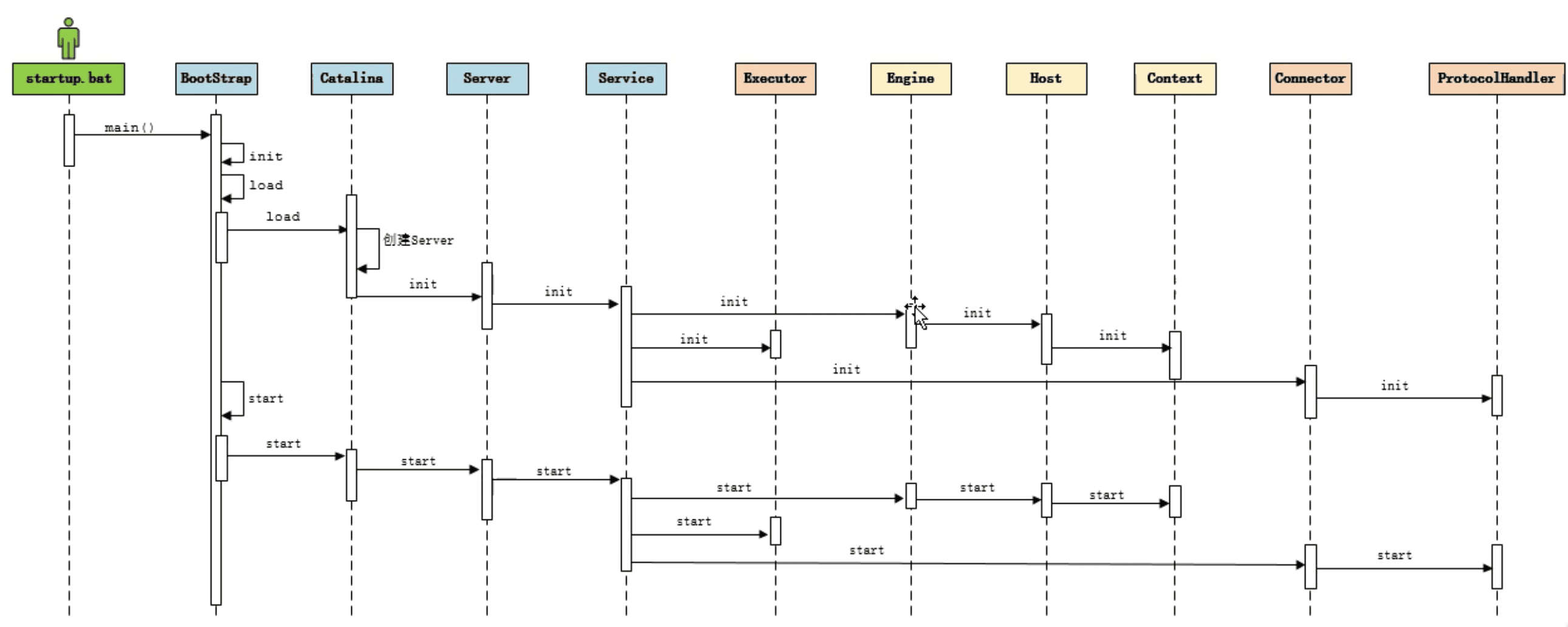
相关文章
- Tomcat - 如何设计一个简单的web容器
- 在学习Tomcat前,很多人先入为主的对它的认知是巨复杂的;所以第一步,在学习它之前,要打破这种观念,我们通过学习如何设计一个最基本的web容器来看它需要考虑什么;进而在真正学习Tomcat时,多把重点放在它的顶层设计上,而不是某一块代码上, 思路永远比具体实现重要的多。
- Tomcat - 理解Tomcat架构设计
- 前文我们已经介绍了一个简单的Servlet容器是如何设计出来,我们就可以开始正式学习Tomcat了,在学习开始,我们有必要站在高点去看看Tomcat的架构设计。
- Tomcat - 源码分析准备和分析入口
- 上文我们介绍了Tomcat的架构设计,接下来我们便可以下载源码以及寻找源码入口了。
- Tomcat - 启动过程:初始化和启动流程
- 在有了Tomcat架构设计和源码入口以后,我们便可以开始真正读源码了。
- Tomcat - 启动过程:类加载机制详解
- 上文我们讲了Tomcat在初始化时会初始化classLoader。本文将具体分析Tomcat的类加载机制,特别是区别于传统的
双亲委派模型的加载机制。
- 上文我们讲了Tomcat在初始化时会初始化classLoader。本文将具体分析Tomcat的类加载机制,特别是区别于传统的
- Tomcat - 启动过程:Catalina的加载
- 通过前两篇文章,我们知道了Tomcat的类加载机制和整体的组件加载流程;我们也知道通过Bootstrap初始化的catalinaClassLoader加载了Catalina,那么进而引入了一个问题就是Catalina是如何加载的呢?加载了什么呢?本文将带你进一步分析。
- Tomcat - 组件生命周期管理:LifeCycle
- 上文中,我们已经知道Catalina初始化了Server(它调用了 Server 类的 init 和 start 方法来启动 Tomcat);你会发现Server是Tomcat的配置文件server.xml的顶层元素,那这个阶段其实我们已经进入到Tomcat内部组件的详解;这时候有一个问题,这么多组件是如何管理它的生命周期的呢?
- Tomcat - 组件拓展管理:JMX和MBean
- 我们在前文中讲Lifecycle以及组件,怎么会突然讲JMX和MBean呢?本文通过承接上文Lifecycle讲Tomcat基于JMX的实现。
- Tomcat - 事件的监听机制:观察者模式
- 本文承接上文中Lifecycle中实现,引出Tomcat的监听机制。
- Tomcat - Server的设计和实现: StandardServer
- 基于前面的几篇文章,我们终于可以总体上梳理Server的具体实现了,这里体现在StandardServer具体的功能实现上。
- Tomcat - Service的设计和实现: StandardService
- 上文讲了Server的具体实现了,本文主要讲Service的设计和实现;我们从上文其实已经知道Server中包含多个service了。
- Tomcat - 线程池的设计与实现:StandardThreadExecutor
- 上文中我们研究了下Service的设计和实现,StandardService中包含Executor的调用;这个比较好理解,Tomcat需要并发处理用户的请求,自然而言就想到线程池,那么Tomcat中线程池(Executor)具体是如何实现的?本文带你继续深度解析。
- Tomcat - Request请求处理: Container设计
- 在理解了Server,Service和Executor后,我们可以进入Request处理环节了。我们知道客户端是可以发起多个请求的,Tomcat也是可以支持多个webapp的,有多个上下文,且一个webapp中可以有多个Servlet...等等,那么Tomcat是如何设计组件来支撑请求处理的呢?本节文将介绍Tomcat的Container设计。
- Tomcat - Container容器之Engine:StandardEngine
- 上文已经知道Container的整体结构和设计,其中Engine其实就是Servlet Engine,负责处理request的顶层容器。
- Tomcat - Container的管道机制:责任链模式
- 上文中介绍了Engine的设计,其中有Pipline相关内容没有介绍,本文将向你阐述Tomcat的管道机制以及它要解决的问题。
- Tomcat - Request请求处理过程:Connector
- 本文主要介绍request请求的处理过程。
ORM框架 - MyBatis详解
架构图

相关文章
- MyBatis详解 - 总体框架设计
- MyBatis整体架构包含哪些层呢?这些层次是如何设计的呢?
- MyBatis详解 - 初始化基本过程
- 从上文我们知道MyBatis和数据库的交互有两种方式有Java API和Mapper接口两种,所以MyBatis的初始化必然也有两种;那么MyBatis是如何初始化的呢?
- MyBatis详解 - 配置解析过程
- 【本文为中优先级】通过上文我们知道MyBatis初始化过程中会解析配置,那具体是如何解析的呢?
- MyBatis详解 - 官网配置清单
- 【本文为低优先级】通过上文我们知道配置是如何加载并初始化的,那MyBatis提供了哪些配置呢?通过MyBatis官网文档我们一探究竟。PS:对于清单型的,只需要大致浏览且在使用时能快速查找即可,所以是低优先级的。
- MyBatis详解 - Mapper映射文件配置
- 在mapper文件中,以mapper作为根节点,其下面可以配置的元素节点有: select, insert, update, delete, cache, cache-ref, resultMap, sql; 本文将Mapper映射文件配置进行详解。
- MyBatis详解 - sqlSession执行流程
- 前面的章节主要讲mybatis如何解析配置文件,这些都是一次性的过程。从本章开始讲解动态的过程,它们跟应用程序对mybatis的调用密切相关。
- MyBatis详解 - 动态SQL使用与原理
- 动态 SQL 是 MyBatis 的强大特性之一。如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL,可以彻底摆脱这种痛苦
- MyBatis详解 - 插件机制
- MyBatis提供了一种插件(plugin)的功能,虽然叫做插件,但其实这是拦截器功能。那么拦截器拦截MyBatis中的哪些内容呢?
- MyBatis详解 - 插件之分页机制
- Mybatis的分页功能很弱,它是基于内存的分页(查出所有记录再按偏移量和limit取结果),在大数据量的情况下这样的分页基本上是没有用的。本文基于插件,通过拦截StatementHandler重写sql语句,实现数据库的物理分页
- MyBatis详解 - 数据源与连接池
- 本文主要介绍MyBatis数据源和连接池相关的内容。
- MyBatis详解 - 事务管理机制
- 本文主要介绍MyBatis事务管理相关的使用和机制。
- MyBatis详解 - 一级缓存实现机制
- 减少资源的浪费,MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候,如果判断先前有个完全一样的查询,会直接从缓存中直接将结果取出,返回给用户,不需要再进行一次数据库查询了。
- MyBatis详解 - 二级缓存实现机制
- MyBatis的二级缓存是Application级别的缓存,它可以提高对数据库查询的效率,以提高应用的性能。
分库分表 - ShardingSphere
ShardingSphere架构实现篇: 主要是对ShardingSphere主要的架构和原理进行分析(多数内容来源于ShardingSphere官方网站)
相关文章
- ShardingSphere详解 - 整体架构设计
- Apache ShardingSphere 5.x 版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。 目前,数据分片、读写分离、数据库高可用、数据加密、影子库压测等功能,以及对 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目; 在 Apache ShardingSphere 中,很多功能实现类的加载方式是通过 SPI(Service Provider Interface) 注入的方式完成的。 SPI 是一种为了被第三方实现或扩展的 API,它可以用于实现框架扩展或组件替换。
- ShardingSphere详解 - 数据分片的原理
- 本文主要介绍ShardingSphere最重要的数据分片功能的原理,ShardingSphere的3个产品的数据分片主要流程是完全一致的,Standard 内核流程由 SQL 解析 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并 组成,主要用于处理标准分片场景下的 SQL 执行。 Federation 执行引擎流程由 SQL 解析 => 逻辑优化 => 物理优化 => 优化执行 => Standard 内核流程 组成。 这篇文章主要转载自ShardingSphere官方网站(v4.x版本 + V5.1.0版本),对于进阶数据库中间件或者设计自带Sharding的数据库(真正的分布式SQL数据库)极具参考价值。
- ShardingSphere详解 - 数据脱敏(加密)详解
- 根据业界对加密的需求及业务改造痛点,提供了一套完整、安全、透明化、低改造成本的数据加密整合解决方案,是 Apache ShardingSphere 数据加密模块的主要设计目标; 这篇文章主要转载自ShardingSphere官方网站(V5.1.0版本),对开发者进阶设计通过数据库中间件进行数据脱敏、加密有着很大的借鉴意义。
- ShardingSphere详解 - 事务实现原理之两阶段事务XA
- 本文主要介绍ShardingSphere分布式事务XA的实现原理; 这篇文章主要转载自ShardingSphere官方网站(V5.1.0版本)。
- ShardingSphere详解 - 事务实现原理之柔性事务SAGA
- Apache ShardingSphere 在v5.0版本前还支持柔性事务SAGA,目前看5.x+版本中已经移除了向观众章节,本文主要介绍其实现原理; 这篇文章主要转载自ShardingSphere官方网站(V4.x版本)。
- ShardingSphere详解 - 事务实现原理之柔性事务SEATA
- Apache ShardingSphere 集成了 SEATA 作为柔性事务的使用方案,本文主要介绍其实现原理; 这篇文章主要转载自ShardingSphere官方网站(V5.1.0版本)。
- ShardingSphere详解 - 弹性伸缩原理
- 支持自定义分片算法,减少数据伸缩及迁移时的业务影响,提供一站式的通用弹性伸缩解决方案,是 Apache ShardingSphere 弹性伸缩的主要设计目标; 这篇文章主要转载自ShardingSphere官方网站(V5.1.0版本)。
- ShardingSphere详解 - 通过影子库进行压测
- Apache ShardingSphere 关注于全链路压测场景下,数据库层面的解决方案。 将压测数据自动路由至用户指定的数据库,是 Apache ShardingSphere 影子库模块的主要设计目标; 这篇文章主要转载自ShardingSphere官方网站(V5.1.0版本)。
Spring技术栈
站在知识体系的视角,学习SpringFramework及其原理,并基于SpringBoot开发。@pdai
SpringFramework框架详解
首先, 从Spring框架的整体架构和组成对整体框架有个认知。
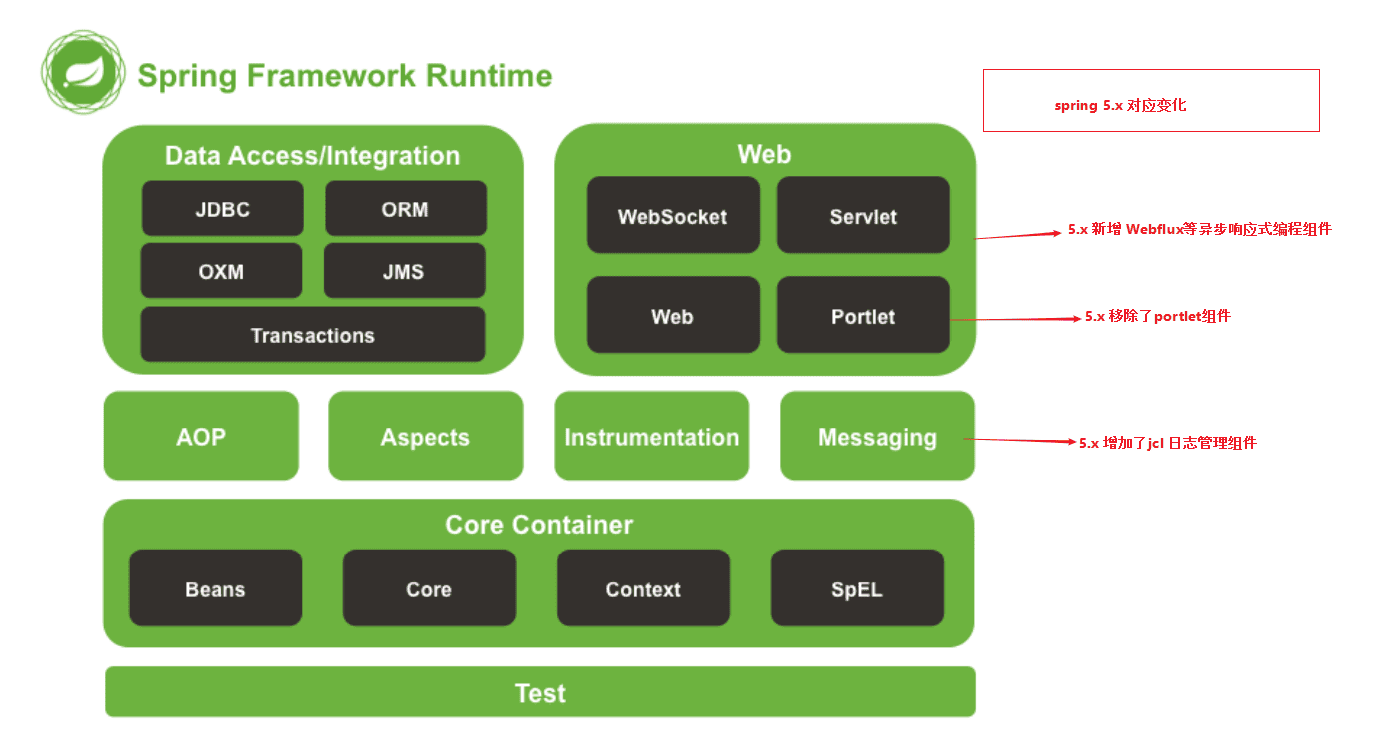
- Spring基础 - Spring和Spring框架组成
- Spring是什么?它是怎么诞生的?有哪些主要的组件和核心功能呢? 本文通过这几个问题帮助你构筑Spring和Spring Framework的整体认知。
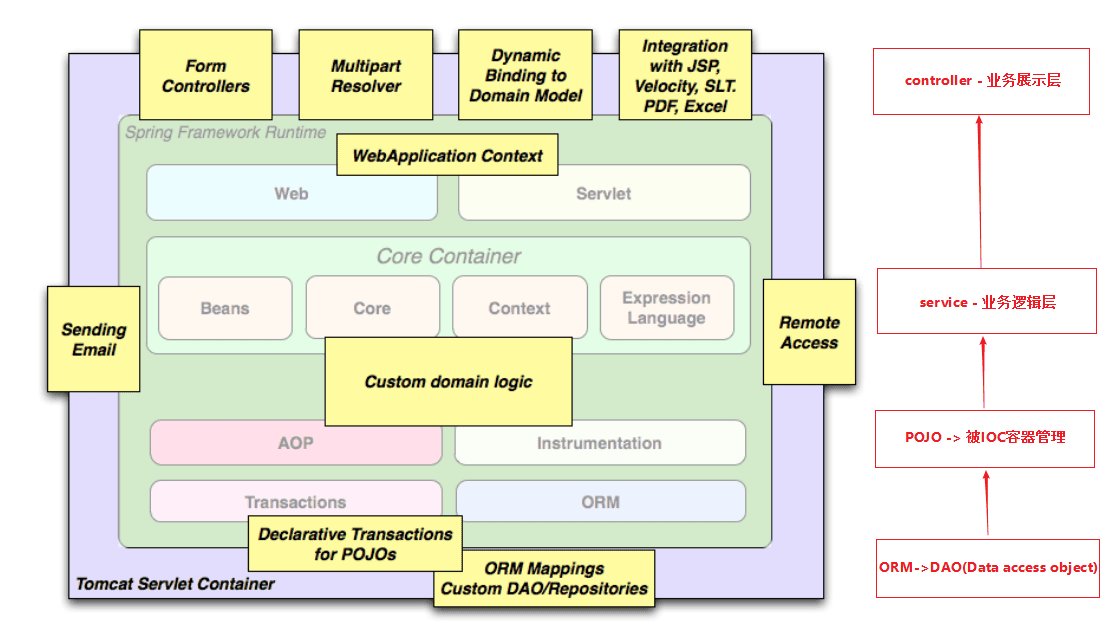
其次,通过案例引出Spring的核心(IoC和AOP),同时对IoC和AOP进行案例使用分析。
- Spring基础 - Spring简单例子引入Spring的核心
- 上文中我们简单介绍了Spring和Spring Framework的组件,那么这些Spring Framework组件是如何配合工作的呢?本文主要承接上文,向你展示Spring Framework组件的典型应用场景和基于这个场景设计出的简单案例,并以此引出Spring的核心要点,比如IOC和AOP等;在此基础上还引入了不同的配置方式, 如XML,Java配置和注解方式的差异。
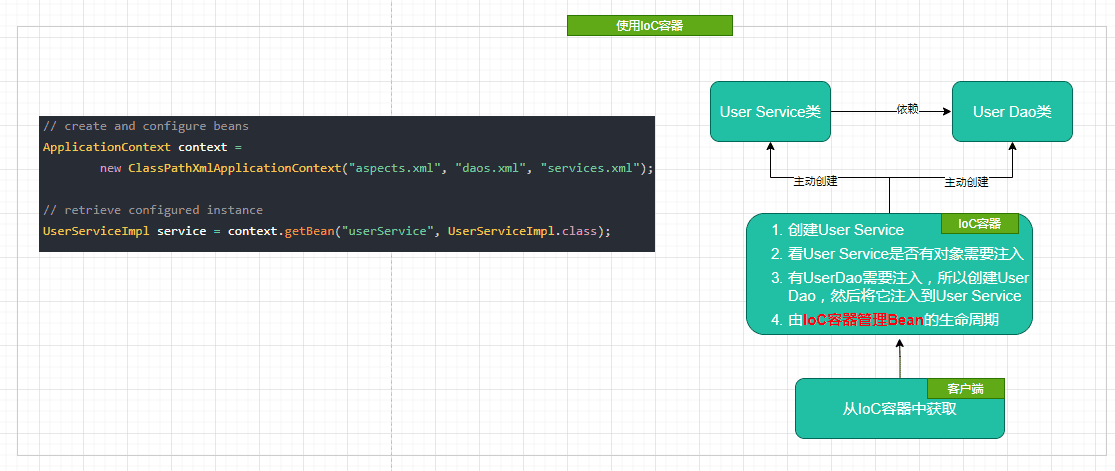
- Spring基础 - Spring核心之控制反转(IOC)
- 在Spring基础 - Spring简单例子引入Spring的核心中向你展示了IoC的基础含义,同时以此发散了一些IoC相关知识点; 本节将在此基础上进一步解读IOC的含义以及IOC的使用方式
- Spring基础 - Spring核心之面向切面编程(AOP)
- 在Spring基础 - Spring简单例子引入Spring的核心中向你展示了AOP的基础含义,同时以此发散了一些AOP相关知识点; 本节将在此基础上进一步解读AOP的含义以及AOP的使用方式。

基于Spring框架和IOC,AOP的基础,为构建上层web应用,需要进一步学习SpringMVC。
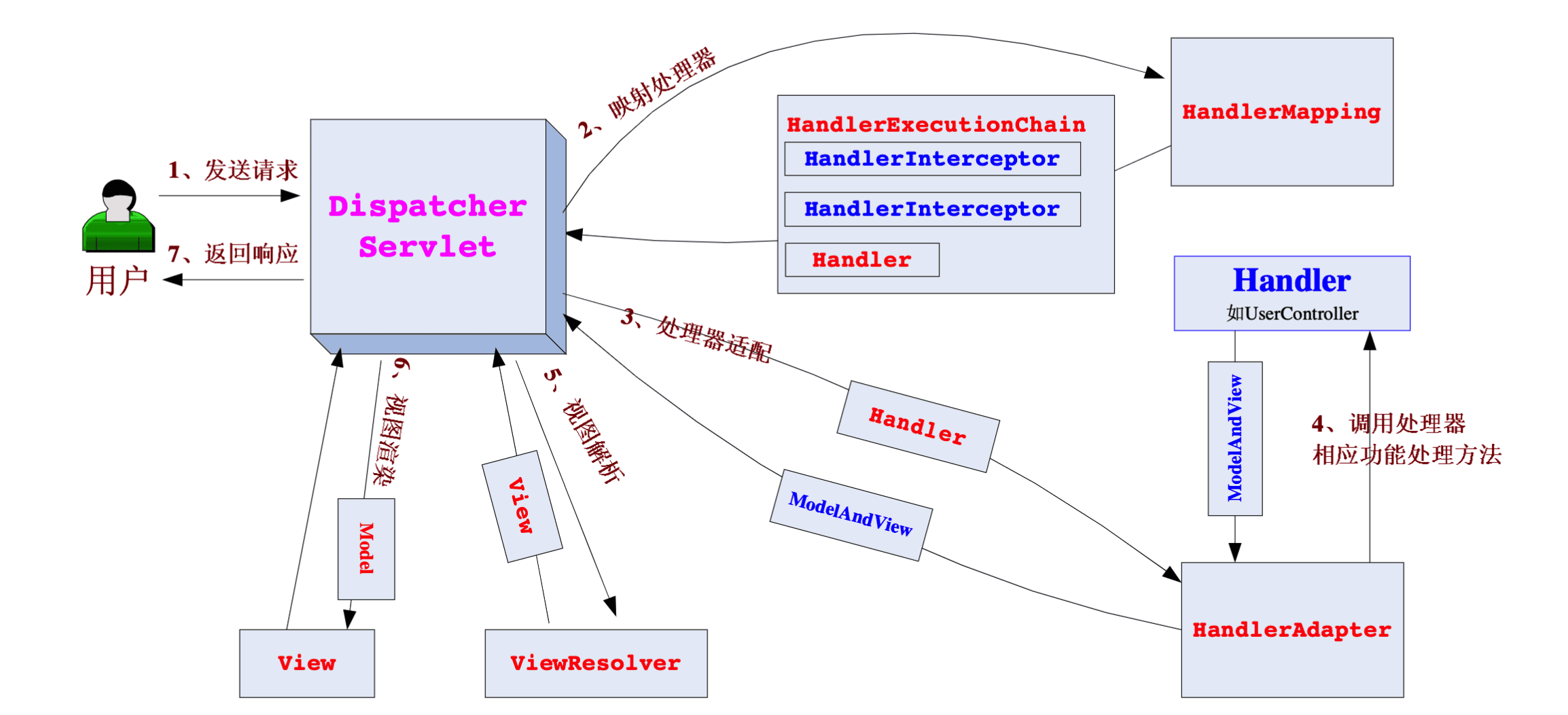
- Spring基础 - SpringMVC请求流程和案例
- 前文我们介绍了Spring框架和Spring框架中最为重要的两个技术点(IOC和AOP),那我们如何更好的构建上层的应用呢(比如web 应用),这便是SpringMVC;Spring MVC是Spring在Spring Container Core和AOP等技术基础上,遵循上述Web MVC的规范推出的web开发框架,目的是为了简化Java栈的web开发。 本文主要介绍SpringMVC的请求流程和基础案例的编写和运行。
Spring进阶 - IoC,AOP以及SpringMVC的源码分析
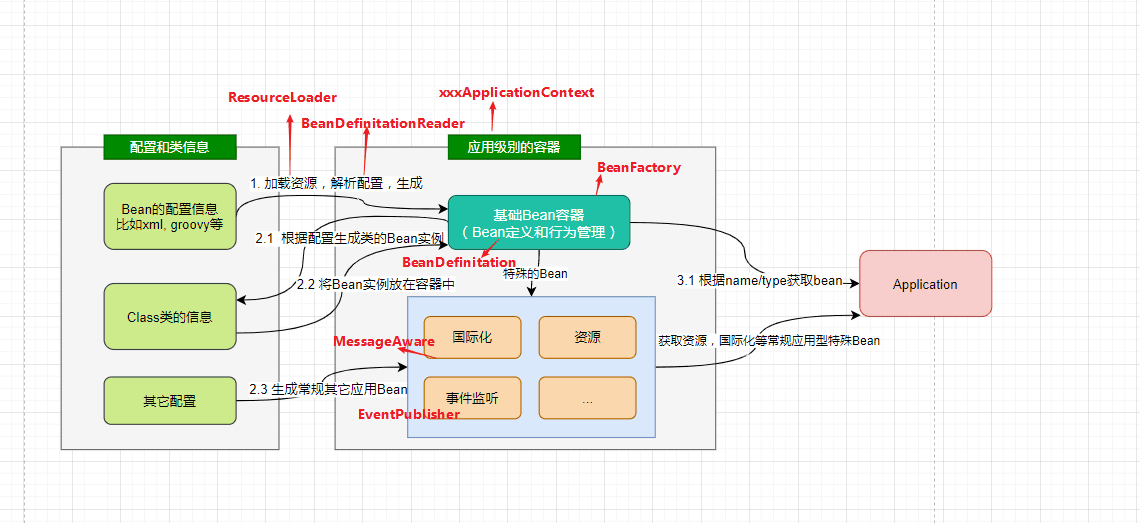
- Spring进阶 - Spring IOC实现原理详解之IOC体系结构设计
- 在对IoC有了初步的认知后,我们开始对IOC的实现原理进行深入理解。本文将帮助你站在设计者的角度去看IOC最顶层的结构设计
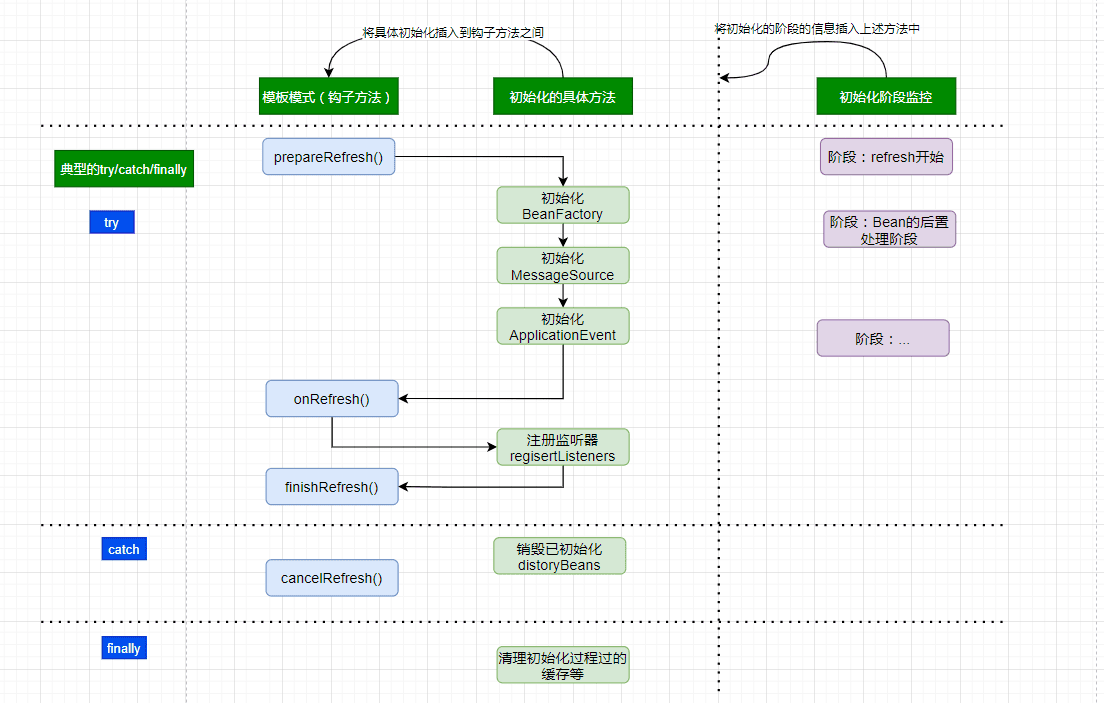
- Spring进阶 - Spring IOC实现原理详解之IOC初始化流程
- 上文,我们看了IOC设计要点和设计结构;紧接着这篇,我们可以看下源码的实现了:Spring如何实现将资源配置(以xml配置为例)通过加载,解析,生成BeanDefination并注册到IoC容器中的
- Spring进阶 - Spring IOC实现原理详解之Bean实例化(生命周期,循环依赖等)
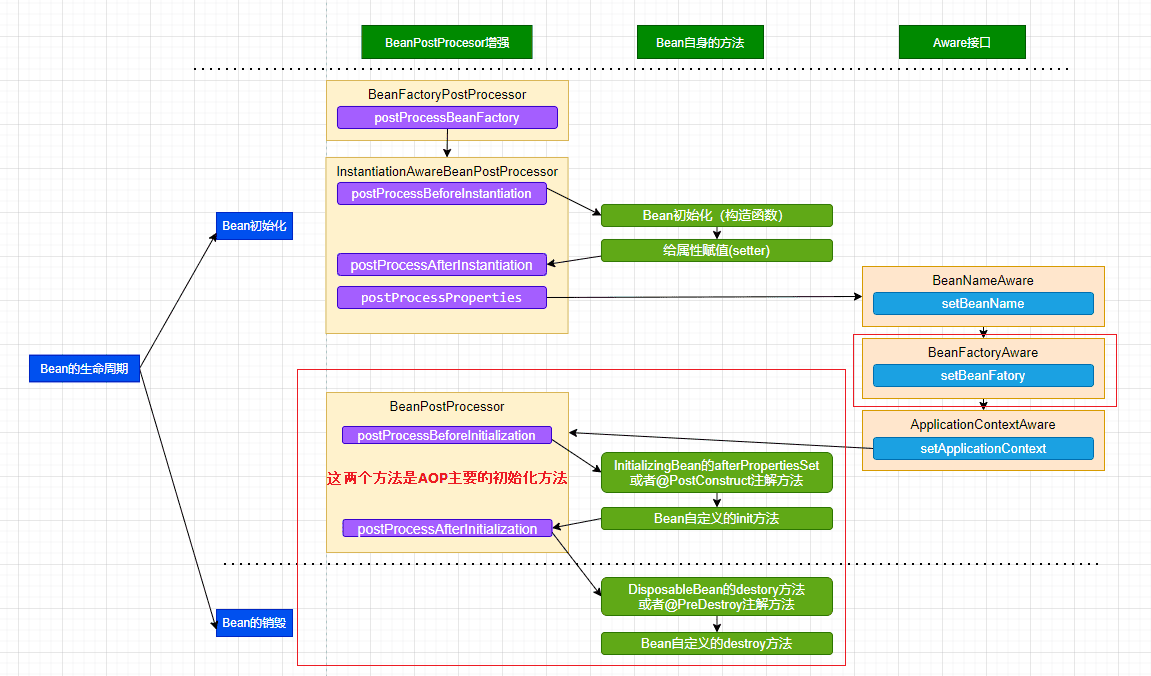
- 上文,我们看了IOC设计要点和设计结构;以及Spring如何实现将资源配置(以xml配置为例)通过加载,解析,生成BeanDefination并注册到IoC容器中的;容器中存放的是Bean的定义即BeanDefinition放到beanDefinitionMap中,本质上是一个
ConcurrentHashMap<String, Object>;并且BeanDefinition接口中包含了这个类的Class信息以及是否是单例等。那么如何从BeanDefinition中实例化Bean对象呢,这是本文主要研究的内容?
- 上文,我们看了IOC设计要点和设计结构;以及Spring如何实现将资源配置(以xml配置为例)通过加载,解析,生成BeanDefination并注册到IoC容器中的;容器中存放的是Bean的定义即BeanDefinition放到beanDefinitionMap中,本质上是一个

- Spring进阶 - Spring AOP实现原理详解之切面实现
- 前文,我们分析了Spring IOC的初始化过程和Bean的生命周期等,而Spring AOP也是基于IOC的Bean加载来实现的。本文主要介绍Spring AOP原理解析的切面实现过程(将切面类的所有切面方法根据使用的注解生成对应Advice,并将Advice连同切入点匹配器和切面类等信息一并封装到Advisor,为后续交给代理增强实现做准备的过程)。
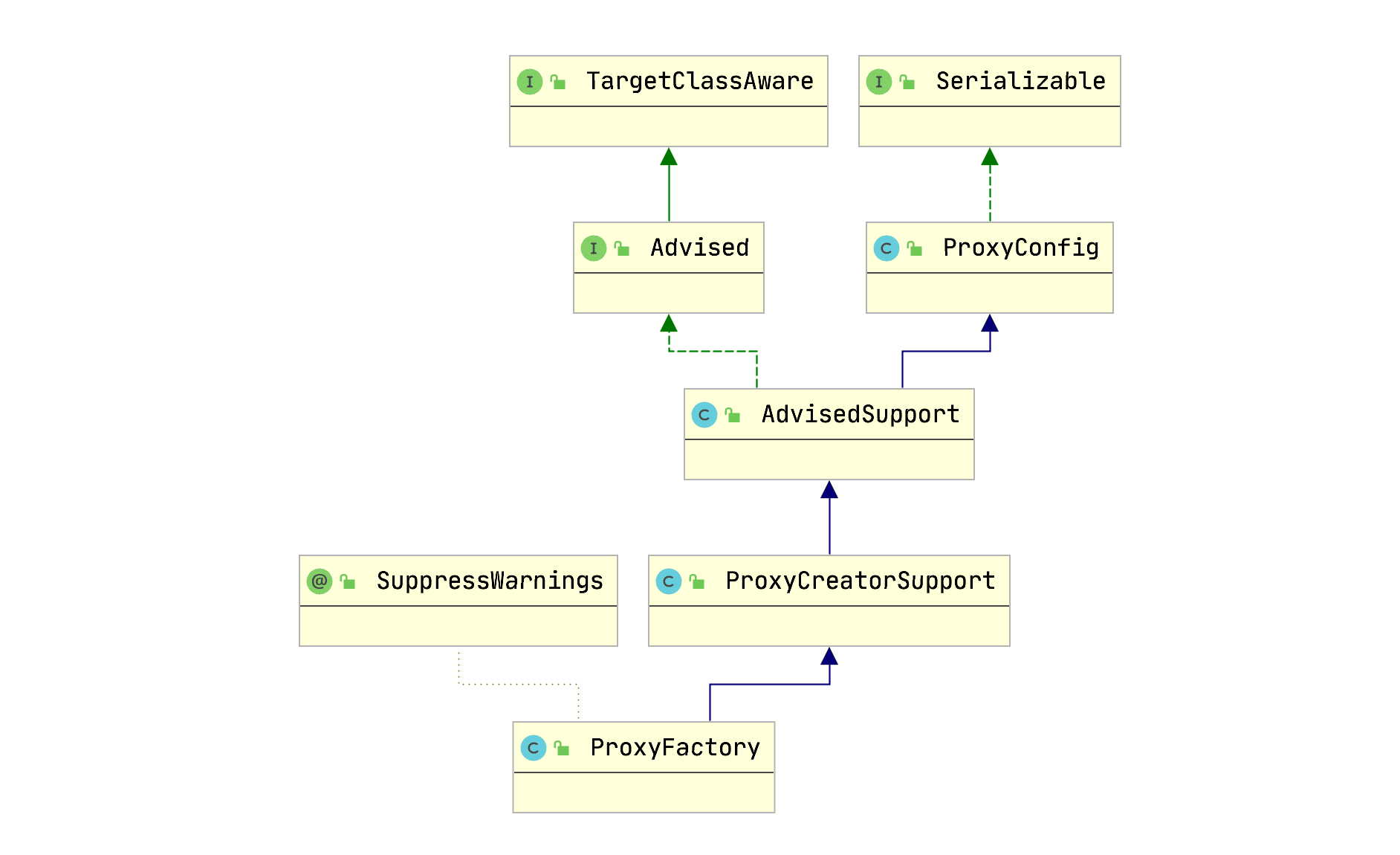
- Spring进阶 - Spring AOP实现原理详解之AOP代理
- 上文我们介绍了Spring AOP原理解析的切面实现过程(将切面类的所有切面方法根据使用的注解生成对应Advice,并将Advice连同切入点匹配器和切面类等信息一并封装到Advisor)。本文在此基础上继续介绍,代理(cglib代理和JDK代理)的实现过程。
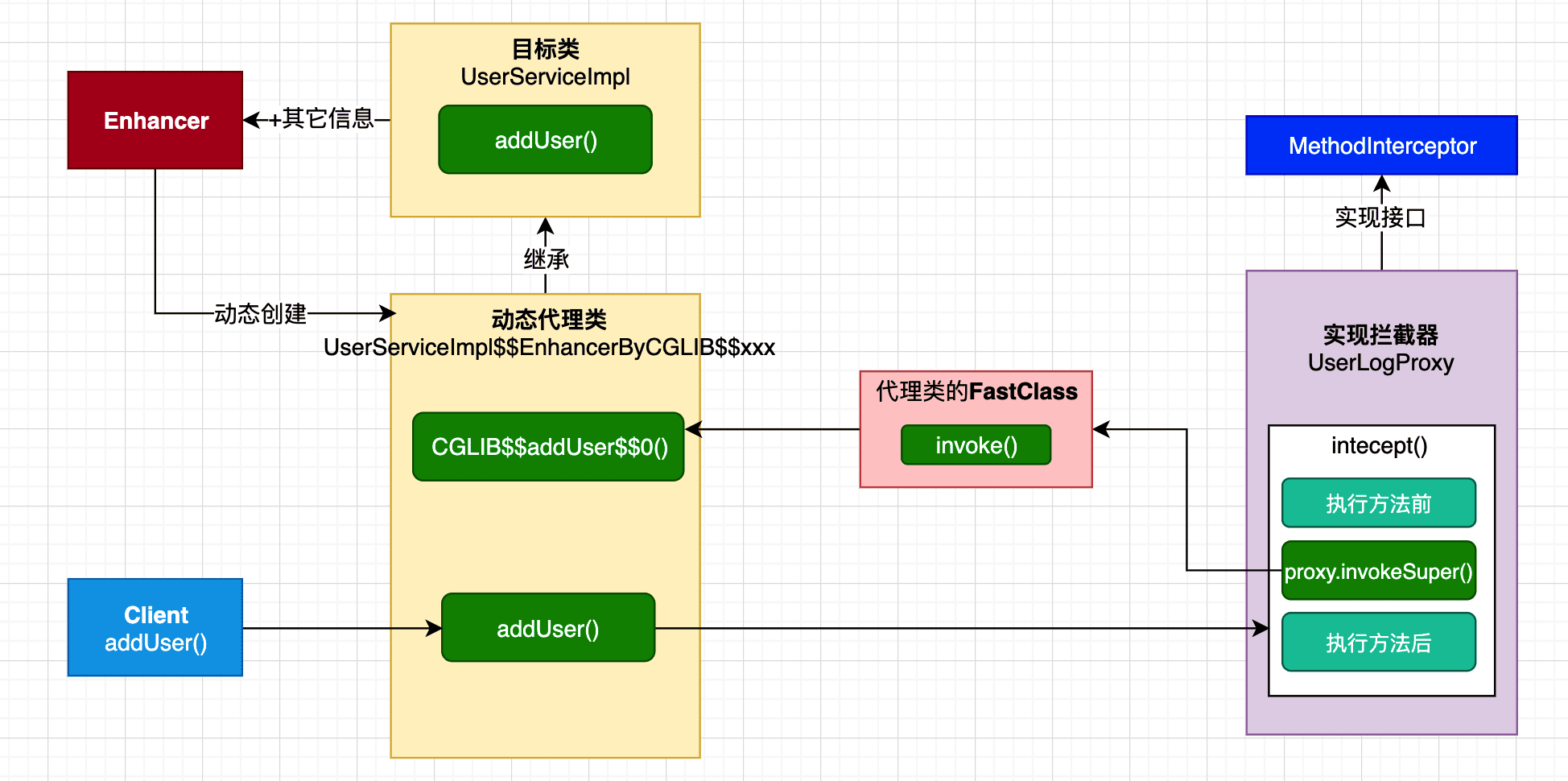
- Spring进阶 - Spring AOP实现原理详解之Cglib代理实现
- 我们在前文中已经介绍了SpringAOP的切面实现和创建动态代理的过程,那么动态代理是如何工作的呢?本文主要介绍Cglib动态代理的案例和SpringAOP实现的原理。
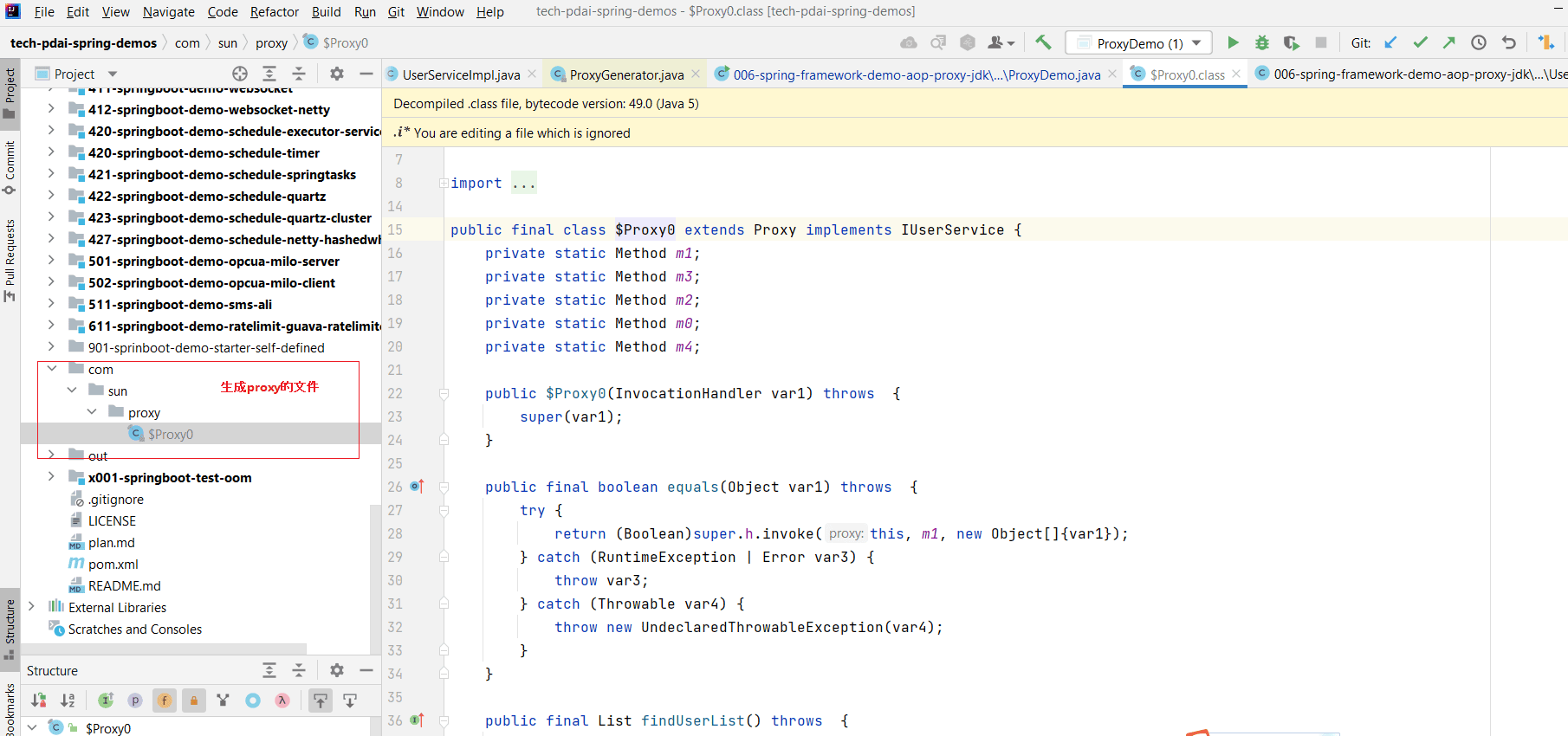
- Spring进阶 - Spring AOP实现原理详解之JDK代理实现
- 上文我们学习了SpringAOP Cglib动态代理的实现,本文主要是SpringAOP JDK动态代理的案例和实现部分。
- Spring进阶 - SpringMVC实现原理之DispatcherServlet初始化的过程
- 前文我们有了IOC的源码基础以及SpringMVC的基础,我们便可以进一步深入理解SpringMVC主要实现原理,包含DispatcherServlet的初始化过程和DispatcherServlet处理请求的过程的源码解析。本文是第一篇:DispatcherServlet的初始化过程的源码解析。
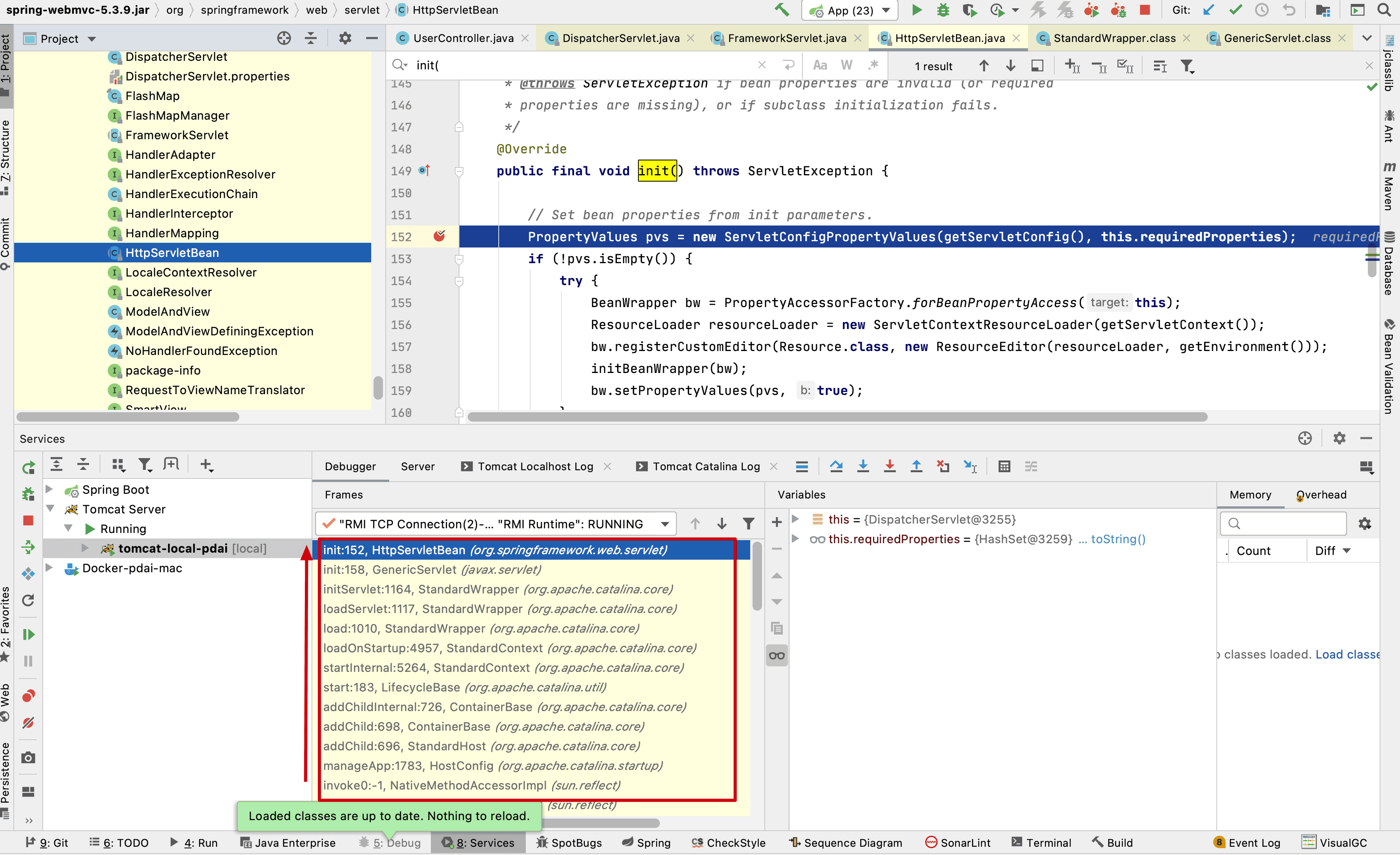
- Spring进阶 - SpringMVC实现原理之DispatcherServlet处理请求的过程
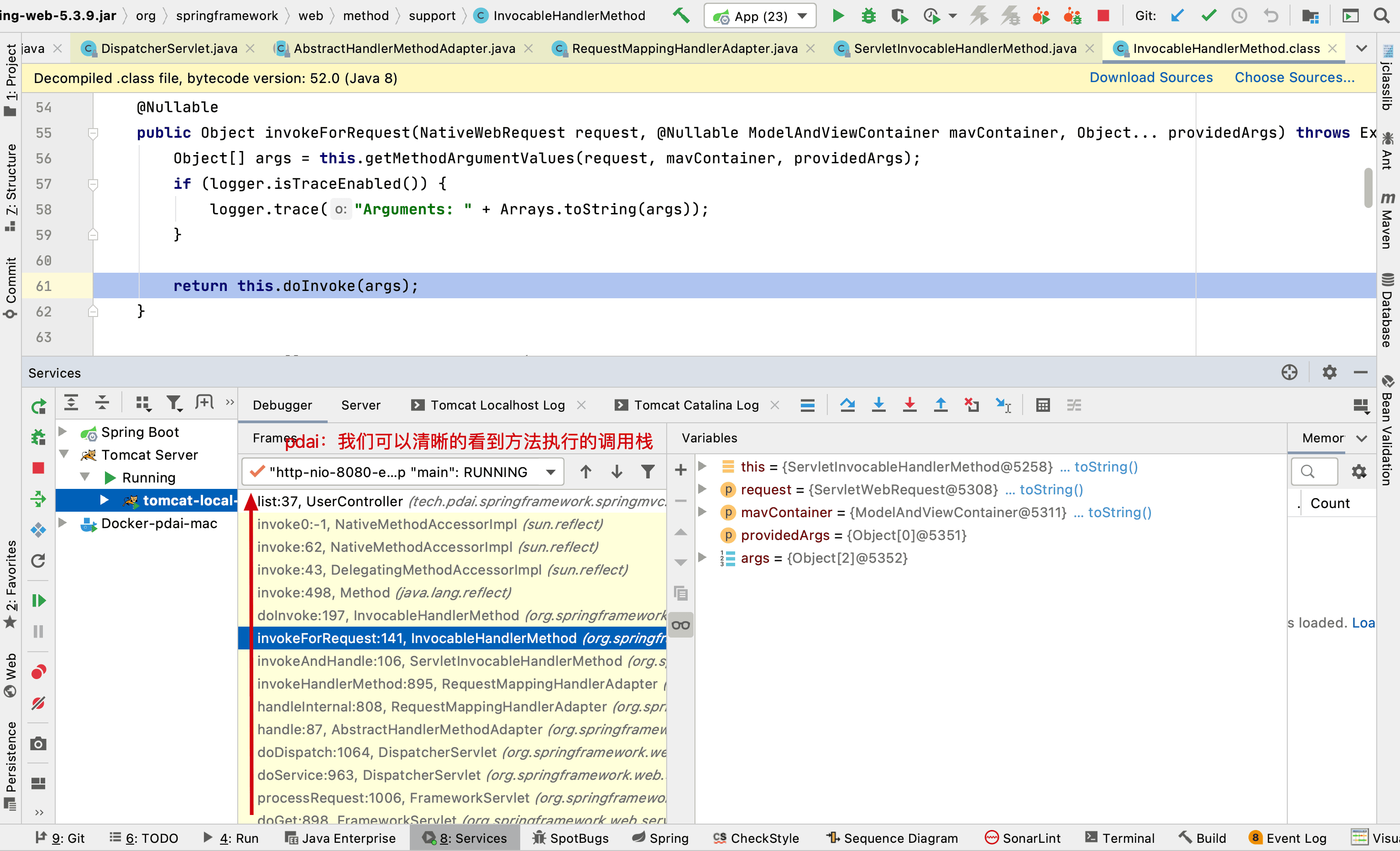
- 前文我们有了IOC的源码基础以及SpringMVC的基础,我们便可以进一步深入理解SpringMVC主要实现原理,包含DispatcherServlet的初始化过程和DispatcherServlet处理请求的过程的源码解析。本文是第二篇:DispatcherServlet处理请求的过程的源码解析。
SpringBoot入门(helloworld,banner,logback,分层设计)
首先,在开始SpringBoot开发时,我们了解一些技术栈背景并通过Hello World级别应用程序开始延伸出SpringBoot入门应用的开发。
- SpringBoot入门 - SpringBoot 简介
- 为什么有了SpringFramework还会诞生SpringBoot?简单而言,因为虽然Spring的组件代码是轻量级的,但它的配置却是重量级的;所以SpringBoot的设计策略是通过开箱即用和约定大于配置 来解决配置重的问题的。
- SpringBoot入门 - 创建第一个Hello world工程
- 我们了解了SpringBoot和SpringFramework的关系之后,我们可以开始创建一个Hello World级别的项目了。
- SpringBoot入门 - 对Hello world进行MVC分层
- 上文中我们创建一个简单的Hello Wold级别的web应用程序,但是存在一个问题,我们将所有代码都放在一个类中的, 这显然是不合理的,那么一个经典的CRUD项目如何分包呢?本文结合常见的MVC分层思路带你学习常见的包结构划分。
- SpringBoot入门 - 添加内存数据库H2
- 上文我们展示了通过学习经典的MVC分包结构展示了一个用户的增删查改项目,但是我们没有接入数据库;本文将在上文的基础上,增加一个H2内存数据库,并且通过Spring 提供的数据访问包JPA进行数据查询。
- SpringBoot入门 - 定制自己的Banner
- 我们在启动Spring Boot程序时,有SpringBoot的Banner信息,那么如何自定义成自己项目的信息呢?
- SpringBoot入门 - 添加Logback日志
- SpringBoot开发中如何选用日志框架呢? 出于性能等原因,Logback 目前是springboot应用日志的标配; 当然有时候在生产环境中也会考虑和三方中间件采用统一处理方式。
- SpringBoot入门 - 配置热部署devtools工具
- 在SpringBoot开发调试中,如果我每行代码的修改都需要重启启动再调试,可能比较费时间;SpringBoot团队针对此问题提供了spring-boot-devtools(简称devtools)插件,它试图提升开发调试的效率。
- SpringBoot入门 - 开发中还有哪些常用注解
- SpringBoot中常用的注解
SpringBoot接口设计和实现(封装,校验,异常,加密,幂等)
接着, 站在接口设计和实现的角度,从实战开发中梳理出,关于接口开发的技术要点。
- SpringBoot接口 - 如何统一接口封装
- 在以SpringBoot开发Restful接口时,统一返回方便前端进行开发和封装,以及出现时给出响应编码和信息。
- SpringBoot接口 - 如何对参数进行校验
- 在以SpringBoot开发Restful接口时, 对于接口的查询参数后台也是要进行校验的,同时还需要给出校验的返回信息放到上文我们统一封装的结构中。那么如何优雅的进行参数的统一校验呢?
- SpringBoot接口 - 如何参数校验国际化
- 上文我们学习了如何对SpringBoot接口进行参数校验,但是如果需要有国际化的信息,应该如何优雅处理呢?
- SpringBoot接口 - 如何统一异常处理
- SpringBoot接口如何对异常进行统一封装,并统一返回呢?以上文的参数校验为例,如何优雅的将参数校验的错误信息统一处理并封装返回呢?
- SpringBoot接口 - 如何提供多个版本接口
- 在以SpringBoot开发Restful接口时,由于模块,系统等业务的变化,需要对同一接口提供不同版本的参数实现(老的接口还有模块或者系统在用,不能直接改,所以需要不同版本)。如何更加优雅的实现多版本接口呢?
- SpringBoot接口 - 如何生成接口文档
- SpringBoot开发Restful接口,有什么API规范吗?如何快速生成API文档呢?
- SpringBoot接口 - 如何访问外部接口
- 在SpringBoot接口开发中,存在着本模块的代码需要访问外面模块接口或外部url链接的需求, 比如调用外部的地图API或者天气API。那么有哪些方式可以调用外部接口呢?
- SpringBoot接口 - 如何对接口进行加密
- 在以SpringBoot开发后台API接口时,会存在哪些接口不安全的因素呢?通常如何去解决的呢?本文主要介绍API接口有不安全的因素以及常见的保证接口安全的方式,重点实践如何对接口进行签名。
- SpringBoot接口 - 如何保证接口幂等
- 在以SpringBoot开发Restful接口时,如何防止接口的重复提交呢? 本文主要介绍接口幂等相关的知识点,并实践常见基于Token实现接口幂等。
- SpringBoot接口 - 如何实现接口限流之单实例
- 在以SpringBoot开发Restful接口时,当流量超过服务极限能力时,系统可能会出现卡死、崩溃的情况,所以就有了降级和限流。在接口层如何做限流呢? 本文主要回顾限流的知识点,并实践单实例限流的一种思路。
- SpringBoot接口 - 如何实现接口限流之分布式
- 上文中介绍了单实例下如何在业务接口层做限流,本文主要介绍分布式场景下限流的方案,以及什么样的分布式场景下需要在业务层加限流而不是接入层; 并且结合kailing开源的ratelimiter-spring-boot-starter为例, 学习思路+代码封装+starter封装。
SpringBoot集成MySQL(JPA,MyBatis,MyBatis-Plus)
接下来,我们学习SpringBoot如何集成数据库,比如MySQL数据库,常用的方式有JPA和MyBatis。
- SpringBoot集成MySQL - 基于JPA的封装
- 在实际开发中,最为常见的是基于数据库的CRUD封装等,比如SpringBoot集成MySQL数据库,常用的方式有JPA和MyBatis; 本文主要介绍基于JPA方式的基础封装思路。
- SpringBoot集成MySQL - MyBatis XML方式
- 上文介绍了用JPA方式的集成MySQL数据库,JPA方式在中国以外地区开发而言基本是标配,在国内MyBatis及其延伸框架较为主流。本文主要介绍MyBatis技栈的演化以及SpringBoot集成基础的MyBatis XML实现方式的实例。
- SpringBoot集成MySQL - MyBatis 注解方式
- 上文主要介绍了Spring集成MyBatis访问MySQL,采用的是XML配置方式;我们知道除了XML配置方式,MyBatis还支持注解方式。本文主要介绍SpringBoot+MyBatis注解方式。
- SpringBoot集成MySQL - MyBatis PageHelper分页
- 前文中,我们展示了Spring Boot与MyBatis的集成,但是没有展示分页实现。本文专门介绍分页相关知识体系和基于MyBatis的物理分页PageHelper。
- SpringBoot集成MySQL - MyBatis 多个数据源
- 前文介绍的SpringBoot集成单个MySQL数据库的情形,那么什么场景会使用多个数据源以及什么场景会需要多个数据源的动态切换呢?本文主要介绍上述场景及SpringBoot+MyBatis实现多个数据源的方案和示例。
- SpringBoot集成MySQL - MyBatis-Plus方式
- MyBatis-Plus(简称 MP)是一个 MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。MyBatis-Plus在国内也有很多的用户,本文主要介绍MyBatis-Plus和SpringBoot的集成。
- SpringBoot集成MySQL - MyBatis-Plus代码自动生成
- 本文主要介绍 MyBatis-Plus代码自动生成,以及产生此类代码生成工具的背景和此类工具的基本实现原理。
- SpringBoot集成MySQL - MyBatis-Plus基于字段隔离的多租户
- 本文主要介绍 MyBatis-Plus的基于字段隔离的多租户实现,以及MyBatis-Plus的基于字段的隔离方式实践和原理。
SpringBoot集成ShardingJDBC(分表分库,读写分离,多租户)
随着数据量和业务的增长,我们还需要进行分库分表,这里主要围绕ShardingSphere中间件来实现分库分表,读写分离和多租户等。
- SpringBoot集成ShardingJDBC - Sharding-JDBC简介和基于MyBatis的单库分表
- 本文主要介绍分表分库,以及SpringBoot集成基于ShardingJDBC的单库分表实践。
- SpringBoot集成ShardingJDBC - 基于JPA的单库分表
- 上文介绍SpringBoot集成基于ShardingJDBC的读写分离实践,本文在此基础上介绍SpringBoot集成基于ShardingJDBC+JPA的单库分表实践。
- SpringBoot集成ShardingJDBC - 基于JPA的读写分离
- 本文主要介绍分表分库,以及SpringBoot集成基于ShardingJDBC的读写分离实践。
- SpringBoot集成ShardingJDBC - 基于JPA的DB隔离多租户方案
- 本文主要介绍ShardingJDBC的分片算法和分片策略,并在此基础上通过SpringBoot集成ShardingJDBC的几种策略(标准分片策略,行表达式分片策略和hint分片策略)向你展示DB隔离的多租户方案。
SpringBoot集成连接池(HikariCP,Druid)
为了提高对数据库操作的性能,引出了数据库连接池,它负责分配、管理和释放数据库连接。历史舞台上出现了C3P0,DBCP,BoneCP等均已经被淘汰,目前最为常用(也是SpringBoot2标配的)是HikariCP,与此同时国内阿里Druid(定位为基于数据库连接池的监控)也有一些市场份额。
- SpringBoot集成连接池 - 数据库连接池和默认连接池HikariCP
- 本文主要介绍数据库连接池,以及SpringBoot集成默认的HikariCP的实践。
- SpringBoot集成连接池 - 集成数据库Druid连接池
- 上文介绍默认数据库连接池HikariCP,本文主要介绍SpringBoot集成阿里的Druid连接池的实践; 客观的来说,阿里Druid只能说是中文开源中功能全且广泛的连接池为基础的监控组件,但是(仅从连接池的角度)在生态,维护性,开源规范性,综合性能等方面和HikariCP比还是有很大差距。
SpringBoot集成数据迁移(Liquibase,Flyway)
在实际上线的应用中,随着版本的迭代,经常会遇到需要变更数据库表和字段,必然会遇到需要对这些变更进行记录和管理,以及回滚等等;同时只有脚本化且版本可管理,才能在让数据库实现真正的DevOps(自动化执行 + 回滚等)。在这样的场景下出现了Liquibase, Flyway等数据库迁移管理工具。
- SpringBoot数据库管理 - 用Liquibase对数据库管理和迁移
- Liquibase是一个用于用于跟踪、管理和应用数据库变化的开源工具,通过日志文件(changelog)的形式记录数据库的变更(changeset),然后执行日志文件中的修改,将数据库更新或回滚(rollback)到一致的状态。它的目标是提供一种数据库类型无关的解决方案,通过执行schema类型的文件来达到迁移。本文主要介绍SpringBoot与Liquibase的集成。
- SpringBoot数据库管理 - 用flyway对数据库管理和迁移
- 上文介绍了Liquibase,以及和SpringBoot的集成。除了Liquibase之外,还有一个组件Flyway也是经常被使用到的类似的数据库版本管理中间件。本文主要介绍Flyway, 以及SpringBoot集成Flyway。
SpringBoot集成PostgreSQL(JPA,MyBatis-Plus,Json)
在企业级应用场景下开源数据库PostgreSQL对标的是Oracle,它的市场份额稳步攀升,并且它在自定义函数,NoSQL等方面也支持,所以PostgreSQL也是需要重点掌握的。
- SpringBoot集成PostgreSQL - 基于JPA封装基础数据操作
- PostgreSQL在关系型数据库的稳定性和性能方面强于MySQL,所以它在实际项目中使用和占比越来越高。对开发而言最为常见的是基于数据库的CRUD封装等,本文主要介绍SpringBoot集成PostgreSQL数据库,以及基于JPA方式的基础封装思路。
- SpringBoot集成PostgreSQL - 基于MyBatis-Plus方式
- 前文介绍SpringBoot+MyBatis-Plus+MySQL的集成,本文主要介绍SpringBoot+MyBatis-Plus+PostgreSQL的集成。
- SpringBoot集成PostgreSQL - NoSQL特性JSONB及自定义函数的封装
SpringBoot集成Redis(Jedis,Luttue,Redission)
学习完SpringBoot和SQL数据库集成后,我们开始学习NoSQL数据库的开发和集成;最重要的是分布式的缓存库Redis,它是最为常用的key-value库。主要包括早前的Jedis集成,目前常见的Luttue和Redission的封装集成;还包括基于此的Redis分布式锁的实现等。
- SpringBoot集成Redis - 基于RedisTemplate+Jedis的数据操作
- Redis是最常用的KV数据库,Spring 通过模板方式(RedisTemplate)提供了对Redis的数据查询和操作功能。本文主要介绍基于RedisTemplate + Jedis方式对Redis进行查询和操作的案例。
- SpringBoot集成Redis - 基于RedisTemplate+Lettuce数据操作
- 在SpringBoot 2.x版本中Redis默认客户端是Lettuce,本文主要介绍SpringBoot 和默认的Lettuce的整合案例。
- SpringBoot集成Redis - 基于RedisTemplate+Lettuce数据类封装
- 前两篇文章介绍了SpringBoot基于RedisTemplate的数据操作,那么如何对这些操作进行封装呢?本文主要介绍基于RedisTemplate的封装。
- SpringBoot集成Redis - Redis分布式锁的实现
- Redis实际使用场景最为常用的还有通过Redis实现分布式锁。本文主要介绍Redis实现分布式锁。
SpringBoot集成其它NoSQL数据库(MongoDB,ElasticSearch,Noe4J)
- SpringBoot集成MongoDB - 基于MongoTemplate的数据操作
- SpringBoot集成ElasticSearch - 基于ElasticSearchTemplate的数据操作
- SpringBoot集成Noe4J - 集成图数据Noe4J
SpringBoot集成Websocket(socket,netty)
进一步,我们看下SpringBoot集成Socket
SpringBoot集成定时任务(springtask,quartz,elastic-job,xxl-job)
开发中常用的还有定时任务,我们看下SpringBoot集成定时任务, 包括Timer,ScheduleExecutorService, HashedWheelTimer, Spring tasks, quartz,elastic-job, xxl-job等。
- SpringBoot集成定时任务 - Timer实现方式
- 定时任务在实际开发中有着广泛的用途,本文主要帮助你构建定时任务的知识体系,同时展示Timer 的schedule和scheduleAtFixedRate例子;后续的文章中我们将逐一介绍其它常见的与SpringBoot的集成。
- SpringBoot集成定时任务 - ScheduleExecutorService实现方式
- 上文介绍的Timer在实际开发中很少被使用, 因为Timer底层是使用一个单线程来实现多个Timer任务处理的,所有任务都是由同一个线程来调度,所有任务都是串行执行。而ScheduledExecutorService是基于线程池的,可以开启多个线程进行执行多个任务,每个任务开启一个线程; 这样任务的延迟和未处理异常就不会影响其它任务的执行了。
- SpringBoot集成定时任务 - Netty HashedWheelTimer方式
- Timer和ScheduledExecutorService是JDK内置的定时任务方案,而业内还有一个经典的定时任务的设计叫时间轮(Timing Wheel), Netty内部基于时间轮实现了一个HashedWheelTimer来优化百万量级I/O超时的检测,它是一个高性能,低消耗的数据结构,它适合用非准实时,延迟的短平快任务,例如心跳检测。本文主要介绍时间轮(Timing Wheel)及其使用。
- SpringBoot集成定时任务 - Spring tasks实现方式
- 前文我们介绍了Timer和ScheduledExecutorService是JDK内置的定时任务方案以及Netty内部基于时间轮实现的HashedWheelTimer;而主流的SpringBoot集成方案有两种,一种是Spring Sechedule, 另一种是Spring集成Quartz; 本文主要介绍Spring Schedule实现方式。
- SpringBoot集成定时任务 - 基础quartz实现方式
- 除了SpringTask,最为常用的Quartz,并且Spring也集成了Quartz的框架。本文主要介绍Quartz和基础的Quartz的集成案例。
- SpringBoot集成定时任务 - 分布式quartz cluster方式
- 通常我们使用quartz只是实现job单实例运行,本例将展示quartz实现基于数据库的分布式任务管理,和控制job生命周期。
- SpringBoot集成定时任务 - 分布式elastic-job方式
- 前文展示quartz实现基于数据库的分布式任务管理和job生命周期的控制,那在分布式场景下如何解决弹性调度、资源管控、以及作业治理等呢?针对这些功能前当当团队开发了ElasticJob,2020 年 5 月 28 日ElasticJob成为 Apache ShardingSphere 的子项目;本文介绍ElasticJob以及SpringBoot的集成。
- SpringBoot集成定时任务 - 分布式xxl-job方式
- 除了前文介绍的ElasticJob,xxl-job在很多中小公司有着应用(虽然其代码和设计等质量并不太高,License不够开放,有着个人主义色彩,但是其具体开箱使用的便捷性和功能相对完善性,这是中小团队采用的主要原因);XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。本文介绍XXL-JOB以及SpringBoot的集成。@pdai
SpringBoot集成视图解析(Thymeleaf,FreeMarker,Velocity,JSP,VueJS)
SpringBoot集成视图解析,包括SpringBoot推荐的Thymeleaf,其它常用的FreeMarker, Velocity, Mustache,甚至JSP;还包括在后端视图的基础上采用主流的前端视图(比如VueJs)的兼容方案等。
- SpringBoot集成视图 - 集成Thymeleaf视图解析
- SpringBoot集成视图 - 集成FreeMarker视图解析
- SpringBoot集成视图 - 集成Velocity视图解析
- SpringBoot集成视图 - 集成Mustache视图解析
- SpringBoot集成视图 - 集成JSP视图解析
- SpringBoot集成视图 - 集成后端视图+VueJS解析
SpringBoot集成缓存(Caffeine,EhCache,CouchBase)
- SpringBoot + Spring Cache + ConcurrentMap
- SpringBoot + Spring Cache + EHCache
- SpringBoot + Spring Cache + Redis
- SpringBoot + Spring Cache + Caffeine
- SpringBoot + Spring Cache + CouchBase
SpringBoot集成认证授权(SpringSecurity,Shiro,Oauth2,SA-Token,Keycloak)
- SpringBoot + Shiro
- SpringBoot + Spring Security
- 常规实现
- Oauth2
- SpringBoot + SA-Token
- SpringBoot + Keycloak
- SpringBoot + 登录验证码
- AJ_Captcha
SpringBoot集成文档操作(上传,PDF,Excel,Word)
开发中常见的文档操作,包括文件的上传和下载,上传又包含大文件的处理;针对不同的文档类型又有些常见的工具,比如POI及衍生框架用来导出Excel, iText框架用来导出PDF等。
- SpringBoot集成文件 - 基础的文件上传和下载
- 项目中常见的功能是需要将数据文件(比如Excel,csv)上传到服务器端进行处理,亦或是将服务器端的数据以某种文件形式(比如excel,pdf,csv,word)下载到客户端。本文主要介绍基于SpringBoot的对常规文件的上传和下载,以及常见的问题等。
- SpringBoot集成文件 - 大文件的上传(异步,分片,断点续传和秒传)
- 上文中介绍的是常规文件的上传和下载,而超大文件的上传技术手段和普通文件上传是有差异的,主要通过基于分片的断点续传和秒传和异步上传等技术手段解决。本文主要介绍SpringBoot集成大文件上传的案例。
- SpringBoot集成文件 - 集成POI之Excel导入导出
- Apache POI 是用Java编写的免费开源的跨平台的 Java API,Apache POI提供API给Java程序对Microsoft Office格式档案读和写的功能。本文主要介绍通过SpringBoot集成POI工具实现Excel的导入和导出功能。
- SpringBoot集成文件 - 集成EasyExcel之Excel导入导出
- EasyExcel是一个基于Java的、快速、简洁、解决大文件内存溢出的Excel处理工具。它能让你在不用考虑性能、内存的等因素的情况下,快速完成Excel的读、写等功能。它是基于POI来封装实现的,主要解决其易用性,封装性和性能问题。本文主要介绍通过SpringBoot集成EasyExcel实现Excel的导入,导出和填充模板等功能。
- SpringBoot集成文件 - 集成EasyPOI之Excel导入导出
- 除了POI和EasyExcel,国内还有一个EasyPOI框架较为常见,适用于没有使用过POI并希望快速操作Excel的入门项目,在中大型项目中并不推荐使用(为了保证知识体系的完整性,把EasyPOI也加了进来)。本文主要介绍SpringBoot集成EasyPOI实现Excel的导入,导出和填充模板等功能。
- SpringBoot集成文件 - 集成POI之Word导出
- 前文我们介绍了通过Apache POI导出excel,而Apache POI包含是操作Office Open XML(OOXML)标准和微软的OLE 2复合文档格式(OLE2)的Java API。所以也是可以通过POI来导出word的。本文主要介绍通过SpringBoot集成POI工具实现Word的导出功能。
- SpringBoot集成文件 - 集成POI-tl之基于模板的Word导出
- 前文我们介绍了通过Apache POI通过来导出word的例子;那如果是word模板方式,有没有开源库通过模板方式导出word呢?poi-tl是一个基于Apache POI的Word模板引擎,也是一个免费开源的Java类库,你可以非常方便的加入到你的项目中,并且拥有着让人喜悦的特性。本文主要介绍通过SpringBoot集成poi-tl实现模板方式的Word导出功能。
- SpringBoot集成文件 - 集成itextpdf之导出PDF
- 除了处理word, excel等文件外,最为常见的就是PDF的导出了。在java技术栈中,PDF创建和操作最为常用的itext了,但是使用itext一定要了解其版本历史和License问题,在早前版本使用的是MPL和LGPL双许可协议,在5.x以上版本中使用的是AGPLv3(这个协议意味着,只有个人用途和开源的项目才能使用itext这个库,否则是需要收费的)。本文主要介绍通过SpringBoot集成itextpdf实现PDF导出功能。
- SpringBoot + 集成PDFBox之PDF操作
- SpringBoot + 集成OpenOffice之文档在线预览
- https://blog.csdn.net/shipfei_csdn/article/details/105141487
- SpringBoot + 集成LibreOffice之文档在线预览
- SpringBoot + 集成kkfileview之文档在线预览
- https://kkfileview.keking.cn
SpringBoot集成消息队列(ActiveMQ,RabbitMQ,ZeroMQ,Kafka)
- SpringBoot + ActiveMQ
- SpringBoot + RabbitMQ
- SpringBoot + ZeroMQ
- SpringBoot + Kafka
SpringBoot集成通知(Email,短信,钉钉,微信)
- SpringBoot + 邮件
- SpringBoot + 钉钉
- SpringBoot + 微信
- SpringBoot + 短信
SpringBoot集成文件系统(minIO,aliyun,tencentCloud,FastDFS)
- SpringBoot + MinIO
- SpringBoot + aliyun
- SpringBoot + TecentCloud
- SpringBoot + FastDFS
SpringBoot集成工作流引擎(activi,jBPM,flowable)
- SpringBoot + activi
- SpringBoot + jBPM
- SpringBoot + flowable
SpringBoot集成其它功能(支付,OPC-UA,JavaFX2)
除了上述的常见的业务上的集成功能外,还有哪些功能或者应用呢?
- SpringBoot集成JavaFX2 - JavaFX 2.0应用
- 很多人对Java开发native程序第一反应还停留在暗灰色单一风格的Java GUI界面,开发方式还停留在AWT或者Swing。本文主要基于SpringBoot和JavaFX开发一个Demo给你展示Java Native应用可以做到什么样的程度。当然JavaFX 2.0没有流行起来也是有原因的,而且目前native的选择很多,前端是个框架都会搞个native...
- SpringBoot + 支付
- SpringBoot + OPC-UA
- ...
SpringBoot应用部署(jar,war,linux,docker,docker-compose)
那么如何将SpringBoot应用打包并部署呢?打包主要有jar,war两种方式;部署包含在linux或者windows上制作成服务,以及制作成docker进行部署;此外也可以结合CI/CD 环境进行部署。
- SpringBoot应用部署 - 打包成jar部署
- 我们知道spring-boot-starter-web默认已经集成了web容器(tomcat),在部署前只需要将项目打包成jar即可。那么怎么将springboot web项目打包成jar呢?本文主要介绍常见的几种方式。
- SpringBoot应用部署 - 使用第三方JAR包
- 在项目中我们经常需要使用第三方的Jar,比如某些SDK,这些SDK没有直接发布到公开的maven仓库中,这种情况下如何使用这些三方JAR呢?本文提供最常用的两种方式。
- SpringBoot应用部署 - 打包成war部署
- 前文我们知道SpringBoot web项目默认打包成jar部署是非常方便的,那什么样的场景下还会打包成war呢?本文主要介绍SpringBoot应用打包成war包的示例。
- SpringBoot应用部署 - 替换tomcat为Jetty容器
- 前文我们知道spring-boot-starter-web默认集成tomcat servlet容器(被使用广泛);而Jetty也是servlet容器,它具有易用性,轻量级,可拓展性等,有些场景(Jetty更满足公有云的分布式环境的需求,而Tomcat更符合企业级环境)下会使用jetty容器。本文主要介绍SpringBoot使用Jetty容器。
- SpringBoot应用部署 - 替换tomcat为Undertow容器
- 前文我们了解到Jetty更满足公有云的分布式环境的需求,而Tomcat更符合企业级环境;那么从性能的角度来看,更为优秀的servlet容器是Undertow。本文将介绍Undertow,以及SpringBoot集成Undertow的示例。
- SpringBoot应用部署 - 在linux环境将jar制作成service
- 前文我们将SpringBoot应用打包成jar,那么如何将jar封装成service呢?本文主要介绍将SpringBoot应用部署成linux的service。
- SpringBoot应用部署 - 在windows环境将jar制作成service
- 前文我们将SpringBoot应用打包成jar并在Linux上封装成service,那么在Windows环境下如何封装呢?本文主要介绍将SpringBoot应用部署成Windows的service。
- SpringBoot应用部署 - docker镜像打包,运行和管理
- 随着软虚拟化docker的流行,基于docker的devops技术栈也开始流行。本文主要介绍通过docker-maven-plugin将springboot应用打包成docker镜像,通过Docker桌面化管理工具或者Idea Docker插件进行管理。
- SpringBoot应用部署 - 使用Docker Compose对容器编排管理
- 如果docker容器是相互依赖的(比如SpringBoot容器依赖另外一个MySQL的数据库容器),那就需要对容器进行编排。本文主要介绍基于Docker Compose的简单容器化编排SpringBoot应用。
SpringBoot集成监控(actuator,springboot-admin,ELK,Grafana,APM)
SpringBoot集成监控,包括SpringBoot自带的actuator,基于actuator的可视化工具springboot admin。监控的日志体系技术栈ELK,监控状态和指标收集prometheus+Grafana,基于Agent的APM性能监控等。
- SpringBoot集成监控 - 集成actuator监控工具
- 当SpringBoot的应用部署到生产环境中后,如何监控和管理呢?比如审计日志,监控状态,指标收集等。为了解决这个问题,SpringBoot提供了Actuator。本文主要介绍Spring Boot Actuator及实现案例。
- SpringBoot集成监控 - 集成springboot admin监控工具
- 上文中展示了SpringBoot提供了Actuator对应用进行监控和管理, 而Spring Boot Admin能够将 Actuator 中的信息进行界面化的展示,也可以监控所有 Spring Boot 应用的健康状况,提供实时警报功能。 本文主要介绍springboot admin以及SpringBoot和springboot admin的集成。
- SpringBoot集成监控 - 日志收集(ELK)
- SpringBoot集成监控 - 状态监控(Prometheus+Grafana)
- SpringBoot集成监控 - 性能监控(APM Agent)
SpringBoot进阶(starter,自动装配原理,各类机制等)
SpringBoot进阶
- SpringBoot进阶 - 实现自动装配原理
- SpringBoot进阶 - 自定义starter
- 如何将自己的模块封装成starter, 并给其它springBoot项目使用呢? 本文主要介绍在Springboot封装一个自定义的Starter的一个Demo,从创建一个模块->封装starter->使用
- SpringBoot进阶 - 嵌入web容器Tomcat原理
- SpringBoot进阶 - 健康检查Actuator原理
开发与工具
开发百宝箱(常用资源)
开发工具清单
- 工具清单 - Overview
- 工具清单 - 项目管理
- 工具清单 - IDE工具
- 工具清单 - 看板工具
- 工具清单 - Bug追踪管理
- 工具清单 - CI & CD
- 工具清单 - API管理
- 工具清单 - 监控工具
- 工具清单 - 文档/Wiki/Notes
- 工具清单 - 文件管理和共享
开发工具详解
- 常用软件工具
- 工具详解 - Git
- Git是分布式代码托管的标杆,这里将提供如何学习Git,以及Git工作流的总结,和常用的操作命令
- 工具详解 - Eclipse,STS,IDEA
- 本文总结常用的IDE工具
- 工具详解 - Maven项目构建
- 在Java开发中,常用构建工具ant,maven和gradle, 其中maven相对主流;本文参考和总结自这里 , 对maven的理解看这一篇就够
- 工具详解 - Jenkins+Gitlab
- 使用Jenkins+Gitlab搭建CI环境
Linux相关
Linux 基础和常用工具总结。
- Linux - Linux基础知识
- Linux基础知识学习梳理
- Linux - Linux 常用
- 本文记录常用的Linux命令, 主要使用CentOS7
- Linux - Curl使用
- 主要总结Linux Curl的一些常见用法
- Linux - Linux创建自建服务
- 以打包自己开发的Java应用到Linux服务器,作为一个服务启动,并开启自启。
- Linux - 内存分析工具pmap
- pmap工具是linux的工具,能够查看进程用了多少内存,还能分析内存用在上面环节,对于一些长期占用内存居高不下的程序可以分析其行为,命令简单,信息简洁。
- Linux - 零拷贝技术
- 磁盘可以说是计算机系统最慢的硬件之一,读写速度相差内存 10 倍以上,所以针对优化磁盘的技术非常的多,比如零拷贝、直接 I/O、异步 I/O 等等,这些优化的目的就是为了提高系统的吞吐量,另外操作系统内核中的磁盘高速缓存区,可以有效的减少磁盘的访问次数。
- Linux - ab压力测试
- ab是apachebench命令的缩写, apache自带的压力测试工具。ab非常实用,它不仅可以对apache服务器进行网站访问压力测试,也可以对或其它类型的服务器进行压力测试。
Docker相关
- Docker - Overview
- 虚拟化技术 - Docker Vs. 虚拟机
- 人们为了提高系统及硬件资源的利用率而引入了虚拟化技术。虚拟化是一种资源管理技术,它可以各种实体资源抽像后再分隔,从而打破实体结构的限制,最大程度的提高资源的利用率。Docker属于软件虚拟化技术中的操作系统层虚拟化技术,它是基于LXC实现的一个应用容器引擎,Docker让开发者可以打包他们的应用及依赖环境到一个可移植的容器中,然后可以将这个容器快速部署开发、测试或生产环境中。了解本文从三个问题着手,什么是虚拟化技术,docker和虚拟机区别,docker可以用来做什么?
- Docker基础 - 入门基础和Helloworld
- 在了解了虚拟化技术和Docker之后,让我们上手Docker,看看Docker是怎么工作的。这里会介绍CentOS环境下Docker的安装和配置,以及会给你展示两个实例,给你一个直观的理解。再啰嗦下,有条件的情况下直接看官网, 网上资料鱼龙混杂,版本也更新不及时。
- Docker基础 - 仓库,镜像,容器详解
- 本文将从仓库,镜像,容器三个方面讲解常用的docker命令和使用等,对于开发而言这块使用的
- Docker基础 - 一个web应用运行实例
- 通过上文我们已经基本了解了docker的结构(仓库,镜像,容器)以及跑docker应用了;本文将通过介绍一个web应用:向你展示如何进行主机与web容器之间的通信,这是web开发者常用的;第二,贯穿上文中内容, 且为我们后续讲解网络提供基础
- Docker基础 - Docker网络使用和配置
- 上文已经向你介绍了,web容器创建和容器互联了,但是容器之间为什么可以直接通信?主机和容器之间为何可以通信?如何进行自定义的配置呢?所以这节就是我们要讲述的Docker网络。
- Docker基础 - Docker数据卷和数据管理
- Docker 容器的数据放哪里呢? 本文带你理解如何在 Docker 内部以及容器之间管理数据。
开发与方法论
开发原则,流程,协议
相关文章
- 软件开发中的原则 - SOLID
- 在软件开发中,前人对软件系统的设计和开发总结了一些原则和模式, 不管用什么语言做开发,都将对我们系统设计和开发提供指导意义。本文主要将总结这些常见的原则,和具体阐述意义。
- 分布式理论 - CAP
- CAP理论是分布式系统、特别是分布式存储领域中被讨论的最多的理论。其中C代表一致性 (Consistency),A代表可用性 (Availability),P代表分区容错性 (Partition tolerance)。CAP理论告诉我们C、A、P三者不能同时满足,最多只能满足其中两个。
- 分布式理论 - BASE
- BASE是“Basically Available, Soft state, Eventually consistent(基本可用、软状态、最终一致性)”的首字母缩写。其中的软状态和最终一致性这两种技巧擅于对付存在分区的场合,并因此提高了可用性。
- 事务理论 - ACID
- 事务的四个基本特性
- 康威定律 - 微服务基础
- 微服务这个概念很早就提出了, 真正火起来是在2016年左右,而康威定律(Conway's Law)就是微服务理论基础。本文整理自肥侠的文章, 帮助大家理解微服务理论体系
- 开发流程详解
- 谈谈我常见的敏捷开发流程的理解
- 开源协议详解
- 开源不等于免费!为了加速我们的开发,我们会使用开源的软件和源码; 为避免商业风险,需要在使用时了解第三方如软件协议,版本,和已知CVE风险等;本文旨在从开源软件再发布过程使用权限的角度入手,总结各个常见开源协议的异同,方便理解。
- 知识共享协议CC 4.0
- 本文主要介绍知识共享许可协议,及本站遵守的多数站点会采用的知识共享协议CC BY-NC-SA 4.0协议,即署名-非商业性使用-相同方式共享协议。
代码规范
相关文章
- 阿里巴巴 Java 开发手册
- 《阿里巴巴 Java 开发手册》是阿里巴巴集团技术团队的集体经验总结,经历了多次大规模一线实战的检验及不断的完善,反馈给广大开发者。现代软件行业的高速发展对开发者的综合素质要求越来越高,因为不仅是编程知识点,其它维度的知识点也会影响到软件的最终交付质量。比如: 数据库的表结构和索引设计缺陷可能带来软件上的架构缺陷或性能风险;工程结构混乱导致后续维护艰难;没有鉴权的漏洞代码易被黑客攻击等等。所以本手册以 Java 开发者为中心视角,划分为编程规约、异常日志、MySQL 数据库、工程结构、安全规约五大块,再根据内容特征,细分成若干二级子目录。根据约束力强弱及故障敏感性,规约依次分为强制、推荐、参考三大类。对于规约条目的延伸信息中,“说明”对内容做了引申和解释;“正例”提倡什么样的编码和实现方式;“反例”说明需要提防的雷区,以及真实的错误案例。
- Google Java 编程风格指南
- Google 出品的 《Google Java Code Style》,由fantasticmao翻译,对应github仓库。
- Twitter Java Style Guide
- 本文是Twitter的Java代码规范。
软件开发模式
软件开发模式相关文章。
相关文章
- 传统模式 - 软件开发生命周期与过程模型(瀑布模型,原型模型和螺旋模型等)
- 软件生命周期(Software Life Cycle,SLC)是软件的产生直到报废或停止使用的生命周期。软件生命周期内有问题定义、可行性分析、总体描述、系统设计、编码、调试和测试、验收与运行、维护升级等阶段。那么如何将上述软件开发过程方法化呢?这就是过程模型。过程模型(Process Models) 意图解决软件过程中的混乱,将软件开发过程中的沟通、计划、建模、构建和部署等活动(activities)有效地组织了起来。他们之间的线性(linear)、迭代(iterative)、演进(evolutionary)和平行(parallel)关系会产生不同的模型。常见的过程模型包括:瀑布模型、原型模型、增量模型、螺旋模型等。
- 传统模式 - 结合软件测试的过程模型演化:V模型,W模型,X模型等
- 对于前文软件开发生命周期的实现,为保障软件质量,将测试工作凸显出来(通过前文介绍的线性(linear)、迭代(iterative)、演进(evolutionary)和平行(parallel)等方式),结合测试又演化出了针对测试的过程模型,主要有V模型,W模型,X模型,H模型等。
- 敏捷开发 - 敏捷软件开发理论及流程
- 敏捷开发以用户的需求进化为核心,采用迭代、循序渐进的方法进行软件开发。在敏捷开发中,软件项目在构建初期被切分成多个子项目,各个子项目的成果都经过测试,具备可视、可集成和可运行使用的特征。换言之,就是把一个大项目分为多个相互联系,但也可独立运行的小项目,并分别完成,在此过程中软件一直处于可使用状态。
- 敏捷开发 - 面向工程管理:极限编程(XP)
- 极限编程(ExtremeProgramming,简称XP)是由KentBeck在1996年提出的,是一种软件工程方法学,是敏捷软件开发中可能是最富有成效的几种方法学之一。XP是一种近螺旋式的开发方法,它将复杂的开发过程分解为一个个相对比较简单的小周期;通过积极的交流、反馈以及其它一系列的方法,开发人员和客户可以非常清楚开发进度、变化、待解决的问题和潜在的困难等,并根据实际情况及时地调整开发过程。极限编程透过引入基本价值、原则、实践方法等概念来达到降低变更成本的目的。
- 敏捷开发 - 面向过程管理:Scrum方式
- Scrum是迭代式增量软件开发过程,是敏捷方法论中的重要框架之一,通常用于敏捷软件开发。Scrum包括了一系列实践和预定义角色的过程骨架。Scrum中的主要角色包括同项目经理类似的Scrum Master角色负责维护过程和任务,Product Owner代表利益所有者,Developer Team包括了所有开发人员。
- 敏捷开发 - 面向过程管理:Kanban方式
- 看板本身源于日本丰田公司对精益制造的实践,后延伸到敏捷开发领域;它的核心是JIT(Just In Time): “让正确的物资,在正确的时间,流动到正确的地方,数量是刚刚好的数量。” 本文主要介绍看板的定义,核心实践以及在研发领域的实践等。
- 敏捷开发 - 开发实践:测试驱动开发(TDD)
- 测试驱动开发(Test Driven Development, 简称TDD)是敏捷开发中的一项核心实践和技术,也是一种设计方法论。TDD的原理是在开发功能代码之前,先编写单元测试用例代码,测试代码确定需要编写什么产品代码。TDD的基本思路就是通过测试来推动整个开发的进行,但测试驱动开发并不只是单纯的测试工作,而是把需求分析,设计,质量控制量化的过程。TDD首先考虑使用需求(对象、功能、过程、接口等),主要是编写测试用例框架对功能的过程和接口进行设计,而测试框架可以持续进行验证。本主要介绍TDD的基础和实践案例,以及很多团队无法使用TDD方式开发的一些思考。
- 敏捷开发 - 开发实践:领域驱动开发(DDD)
- TODO
- 典型的中小团队开发流程详解
- 通过典型的中小团队开发流程谈谈我对常见的敏捷开发流程的理解。
- 精益企业 - 从组织的角度: 集成精益,敏捷,DevOPS等
- Lean Enterprise (精益企业)是指一个产品系列价值流的不同部门同心协力消除浪费,并且按照顾客要求,来拉动生产。本文主要基于Scaled Agile, Inc. (SAI)公司的SAFe的框架(SAFe for Lean Enterprises)向你介绍精益企业的7个核心,并站在更高的视野层级上看敏捷和devops的位置,可以给你更多的启发。
企业开发认证
常见企业开发和系统认证相关文章。
相关文章
- 能力成熟度模型集成认证 - CMMI
- 在美国国防部的支持下,1987年,卡内基·梅隆大学软件工程研究所率先推出了软件工程评估项目的研究成果--软件过程能力成熟度模型(Capability Maturity Model of Software,即CMM),其研究目的是提供一种评价软件承接方能力的方法,同时它可帮助软件组织改进其软件过程。CMM是对软件组织进化阶段的描述,随着软件组织定义、实施、测量、控制和改进其软件过程,软件组织的能力经过这些阶段逐步提高。该能力成熟度模型使软件组织能够较容易的确定其当前过程的成熟度并识别其软件过程执行中的薄弱环节,确定对软件质量和过程改进最为关键的几个问题,从而形成对其过程的改进策略。软件组织只要关注并认真实施一组有限的关键实践活动,就能稳步的改善其全组织的软件过程,使全组织的软件过程能力持续增长。
- 信息安全等级保护认证
- 随着国内对网络安全的逐步重视,以及《网络安全法》的出台, 在金融、电力、广电、医疗、教育等行业,主管单位明确要求从业机构的信息系统(APP)要开展等级保护工作。落实到企业,包含等级保护认证和每年的护网活动等。
- 信息安全管理认证 - ISO27001
- 信息安全管理实用规则ISO/IEC27001的前身为英国的BS7799标准,该标准由英国标准协会(BSI)于1995年2月提出,并于1995年5月修订而成的。1999年BSI重新修改了该标准。BS7799分为两个部分:BS7799-1,信息安全管理实施规则; BS7799-2,信息安全管理体系规范。第一部分对信息安全管理给出建议,供负责在其组织启动、实施或维护安全的人员使用;第二部分说明了建立、实施和文件化信息安全管理体系(ISMS)的要求,规定了根据独立组织的需要应实施安全控制的要求。
设计模式
在软件开发中,前人对软件系统的设计和开发总结了一些原则和模式, 不管用什么语言做开发,都将对我们系统设计和开发提供指导意义。本文主要将对24种设计模式和7个设计原则进行总结,和具体阐述意义。你可以通过这篇文章设计模式 - Overview 了解整体上的知识点。
知识体系系统性梳理
相关文章
第一步:创建型设计模式
- 创建型 - 单例模式(Singleton pattern)
- 单例模式(Singleton pattern): 确保一个类只有一个实例,并提供该实例的全局访问点, 本文介绍6中常用的实现方式
- 创建型 - 简单工厂(Simple Factory)
- 简单工厂(Simple Factory),它把实例化的操作单独放到一个类中,这个类就成为简单工厂类,让简单工厂类来决定应该用哪个具体子类来实例化,这样做能把客户类和具体子类的实现解耦,客户类不再需要知道有哪些子类以及应当实例化哪个子类
- 创建型 - 工厂方法(Factory Method)
- 工厂方法(Factory Method),它定义了一个创建对象的接口,但由子类决定要实例化哪个类。工厂方法把实例化操作推迟到子类
- 创建型 - 抽象工厂(Abstract Factory)
- 抽象工厂(Abstract Factory),抽象工厂模式创建的是对象家族,也就是很多对象而不是一个对象,并且这些对象是相关的,也就是说必须一起创建出来。而工厂方法模式只是用于创建一个对象,这和抽象工厂模式有很大不同
- 创建型 - 生成器(Builder)
- 生成器(Builder),封装一个对象的构造过程,并允许按步骤构造
- 创建型 - 原型模式(Prototype)
- 原型模式(Prototype),使用原型实例指定要创建对象的类型,通过复制这个原型来创建新对象
第二步:结构型设计模式
- 结构型 - 外观(Facade)
- 外观模式(Facade pattern),它提供了一个统一的接口,用来访问子系统中的一群接口,从而让子系统更容易使用
- 结构型 - 适配器(Adapter)
- 适配器模式(Adapter pattern): 将一个类的接口, 转换成客户期望的另一个接口。 适配器让原本接口不兼容的类可以合作无间。 对象适配器使用组合, 类适配器使用多重继承
- 结构型 - 桥接(Bridge)
- 桥接模式(Bridge pattern): 使用桥接模式通过将实现和抽象放在两个不同的类层次中而使它们可以独立改变
- 结构型 - 组合(Composite)
- 组合模式(composite pattern): 允许你将对象组合成树形结构来表现"整体/部分"层次结构. 组合能让客户以一致的方式处理个别对象以及对象组合
- 结构型 - 装饰(Decorator)
- 装饰者模式(decorator pattern): 动态地将责任附加到对象上, 若要扩展功能, 装饰者提供了比继承更有弹性的替代方案
- 结构型 - 享元(Flyweight)
- 享元模式(Flyweight Pattern): 利用共享的方式来支持大量细粒度的对象,这些对象一部分内部状态是相同的。 它让某个类的一个实例能用来提供许多"虚拟实例"
- 结构型 - 代理(Proxy)
- 代理模式(Proxy pattern): 为另一个对象提供一个替身或占位符以控制对这个对象的访问
第三步:行为型设计模式
- 行为型 - 责任链(Chain Of Responsibility)
- 责任链模式(Chain of responsibility pattern): 通过责任链模式, 你可以为某个请求创建一个对象链. 每个对象依序检查此请求并对其进行处理或者将它传给链中的下一个对象
- 行为型 - 策略(Strategy)
- 策略模式(strategy pattern): 定义了算法族, 分别封闭起来, 让它们之间可以互相替换, 此模式让算法的变化独立于使用算法的客户
- 行为型 - 模板方法(Template Method)
- 模板方法模式(Template pattern): 在一个方法中定义一个算法的骨架, 而将一些步骤延迟到子类中. 模板方法使得子类可以在不改变算法结构的情况下, 重新定义算法中的某些步骤
- 行为型 - 命令模式(Command)
- 命令模式(Command pattern): 将"请求"封闭成对象, 以便使用不同的请求,队列或者日志来参数化其他对象. 命令模式也支持可撤销的操作
- 行为型 - 观察者(Observer)
- 观察者模式(observer pattern): 在对象之间定义一对多的依赖, 这样一来, 当一个对象改变状态, 依赖它的对象都会收到通知, 并自动更新
- 行为型 - 访问者(Visitor)
- 访问者模式(visitor pattern): 当你想要为一个对象的组合增加新的能力, 且封装并不重要时, 就使用访问者模式
- 行为型 - 状态(State)
- 状态模式(State pattern): 允许对象在内部状态改变时改变它的行为, 对象看起来好象改了它的类
- 行为型 - 解释器(Interpreter)
- 解释器模式(Interpreter pattern): 使用解释器模式为语言创建解释器,通常由语言的语法和语法分析来定义
- 行为型 - 迭代器(Iterator)
- 迭代器模式(iterator pattern): 提供一种方法顺序访问一个聚合对象中的各个元素, 而又不暴露其内部的表示
- 行为型 - 中介者(Mediator)
- 中介者模式(Mediator pattern) : 使用中介者模式来集中相关对象之间复杂的沟通和控制方式
- 行为型 - 备忘录(Memento)
- 备忘录模式(Memento pattern): 当你需要让对象返回之前的状态时(例如, 你的用户请求"撤销"), 你使用备忘录模式
架构与系统设计
学习思路
基础到方法论
包括架构的概述,特点,目标,本质以及方法论等
- 架构 - 架构基础: 特点,本质...
- 本节总结下架构相关的基础知识:概述,特点,目标,本质...
如何理解架构
理解架构,包括架构的视角,架构的演进,服务化演进,架构的核心要素
- 架构 - 理解构架的视角
- 在学习架构时,我认为首先要理清楚架构的视角,因为你所认知的架构和别人所说的架构可能是两码事。对于不同职位的视角是不一样的,比如开发而言他更多的看到的是开发架构;对售前人员,他可能更多的看到的是业务架构;对于运维人员,他看到的可能是运维架构;而对于技术支持和部署人员,他更多的看到的网络和物理架构。
- 架构 - 理解构架的分层
- 技术框架(technological Framework)是整个或部分技术系统的可重用设计,表现为一组抽象构件及构件实例间交互的方法。于开发者而言,实际工作从通常采用的是分层模型,由于其重要性,这里独立一个章节,总结经典的七层逻辑架构。
- 架构 - 理解架构的演进
- 在学习架构时,第一步不要去学习框架,而是要学习架构的演进。强烈推荐李智慧老师的《大型网站技术架构》,这本书翻起来很快,对构筑你自己的体系很有帮助,本文的内容来源于它,在此基础上拓展了下。
- 架构 - 理解架构的服务演化
- Kubernetes、Service Mesh 和 Serverless应该是最近比较火的了,而上文主要从逻辑架构角度分析了架构演进,本文将从服务演化和容器编排化的角度帮你增强对架构演进的认识。
- 架构 - 理解架构的模式1
- 架构演进中有很多知识点,总体上可以归结为以下模式,这里说的模式本质是架构中技术点的抽象。强烈推荐李智慧老师的《大型网站技术架构》,本文的内容也是来源于它,在此基础上拓展了下。
- 架构 - 理解架构的模式2
- 本文整理自朱晔的互联网架构实践心得, 他是结合了 微软给出的云架构的一些模式的基础上加入他自己的理解来总结互联网架构中具体的一些模式。我在此基础上进行了些微小的调整。
- 架构 - 理解架构的核心要素
- 一般来说软件架构需要关注性能、可用性、伸缩性、扩展性和安全性这5个架构要素。
架构高并发和高可用
架构高并发和高可用技术点主要包含如下方面。
- 架构之高并发:缓存
- 高并发实现的三板斧:缓存,限流和降级。缓存在高并发系统中有者极其广阔的应用,需要重点掌握,本文重点介绍下缓存及其实现。
- 架构之高并发:限流
- 每个系统都有服务的上线,所以当流量超过服务极限能力时,系统可能会出现卡死、崩溃的情况,所以就有了降级和限流。限流其实就是:当高并发或者瞬时高并发时,为了保证系统的稳定性、可用性,系统以牺牲部分请求为代价或者延迟处理请求为代价,保证系统整体服务可用。
- 架构之高并发:降级和熔断
- 在高并发环境下,服务之间的依赖关系导致调用失败,解决的方式通常是: 限流->熔断->隔离->降级, 其目的是防止雪崩效应。
- 架构之高可用:负载均衡
- 负载均衡(Load Balance),意思是将负载(工作任务,访问请求)进行平衡、分摊到多个操作单元(服务器,组件)上进行执行。是解决高性能,单点故障(高可用),扩展性(水平伸缩)的终极解决方案。
- 架构之高可用:容灾备份,故障转移
- 容灾技术是系统的高可用性技术的一个组成部分,容灾系统更加强调处理外界环境对系统的影响,特别是灾难性事件对整个IT节点的影响,提供节点级别的系统恢复功能。故障转移(failover),即当活动的服务或应用意外终止时,快速启用冗余或备用的服务器、系统、硬件或者网络接替它们工作。故障恢复是在计划内或计划外中断解决后切换回主站点的过程。
架构的安全
此外还需要关注下架构的安全。
- 架构 - 保障架构安全
- 本文对架构安全知识点梳理。
架构参考资料
书籍推荐
F. 架构参考资料:此外还会总结下架构里面比较好的学习资料。
1. 《大型网站技术架构:核心原理与案例分析》
这是比较早,比较系统介绍大型网站技术架构的书,通俗易懂又充满智慧,即便你之前完全没接触过网站开发,通读前几章,也能快速获取到常见的网站技术架构及其应用场景。非常赞。
2. 《亿级流量网站架构核心技术》
相比《大型网站技术架构》的高屋建瓴,开涛的这本《亿级流量网站架构核心技术》则落实到细节,网站架构中常见的各种技术,比如缓存、队列、线程池、代理……,统统都讲到了,而且配有核心代码。甚至连 Nginx 的配置都有!
如果你想在实现大流量网站时找参考技术和代码,这本书最合适啦。
3. 《架构即未来》
这是一本“神书”啦,超越具体技术层面,着重剖析架构问题的根源,帮助我们弄清楚应该以何种方式管理、领导、组织和配置团队。
4. 《分布式服务架构:原理、设计与实战》
这本书全面介绍了分布式服务架构的原理与设计,并结合作者在实施微服务架构过程中的实践经验,总结了保障线上服务健康、可靠的最佳方案,是一本架构级、实战型的重量级著作。
5. 《聊聊架构》
这算是架构方面的一本神书了,从架构的原初谈起,从业务的拆分谈起,谈到架构的目的,架构师的角色,架构师如何将架构落地……强烈推荐。
不过,对于没有架构实践经验的小伙伴来讲,可能会觉得这本书比较虚,概念多,实战少。但如果你有过一两个项目的架构经验,就会深深认同书中追本溯源探讨的架构理念。
6. 《软件架构师的12项修炼》
大多数时候所谓的“技术之玻璃天花板”其实只是缺乏软技能而已。这些技能可以学到,缺乏的知识可以通过决定改变的努力来弥补。
微服务与服务网格TBD
微服务
Spring Cloud
Kubernetes
Service Mesh
产品与团队
技术人通常沉溺于技术的本身,高估了技术本身的价值,而忽视了其它要素的重要性。@pdai
- 从产品的角度:产品的本身是解决人性上的需求等
- 从个人的角度:自身成长,身心建设,认知提升,相关理论等
- 从团队的角度:承认个体的局限性,关注其它角色和要素的重要性等
- 从生活的角度:与上面几点而言,生活的本身才是最重要的,保持身心健康,去爱你所爱,不虚此生!
个人成长
个人成长相关
- 知识体系:如何构建自己的知识体系
- 这个网站区别于其它博客和公众号是期望构建知识体系,构建知识体系帮助了我很大程度上提升了认知效率。偶然看到36氪分享的一篇文章,也是关于如何构建知识体系的,基本和我的做法一致,现在分享给大家。
- 自我迭代:从复盘中获得自我迭代
- 在工作学习生活中,一味的埋头苦干是不行的,如何实现快速的自我迭代,一定是复盘 - 对做过的事加以回顾,从中探寻规律、总结经验、提升解决问题的能力!知乎上有一个相关的讨论,本文站在个人复盘的角度总结一些经验(复盘最重要的还是自我实践,然后持之以恒,当然首先要对自己诚实)。
- 如何提问:提问的智慧
- 平时我们工作学习中都会遇到很多问题,如何更好的提问,从而促进问题的解决呢?问对问题才有会有正确的答案。这里强烈推荐看这篇《提问的智慧》,本文翻译自How To Ask Questions The Smart Way,原文在GitHub有几万的赞,足以见得本文被推崇的程度。
- 问题分析:5W2H分析法
- 平时遇到问题,如何应用一些分析方法来帮助我们系统性思考呢?5W2H分析法。
- 人的需求:马斯洛需求模型
- 人都潜藏着各种需求,作为团队中一员或者团队的管理者,如果能从人核心的需求出发,解决他的底层需求,就能增强团队的满足感。
- 个人价值:个人价值冰山模型
- 你的收入是由什么决定呢, 站在理论角度如何提高收入呢?这里分享一篇文章主要从冰山模型谈个人价值、个人回报。
- 人生效率:如何做好人生效率管理
- 虽然我也鼓励别人积极学习生活,但是时常也会焦虑,那么如何去调整心态,积极的去面对呢?这里分享一篇 PM熊叔 的文章《如何做好人生效率管理》,一起做好人生效率的管理,一起共勉。
- 思维模型:查理芒格推荐的100个思维模型
- 我对查理芒格的《穷查理宝典》印象比较深的一个观点是:在手里拿着一把锤子的人眼中,世界就像一颗钉子。大多数人试图以一种思维模型来解决所有问题,而其思维往往只来自某一专业学科;但你必须要知道各种重要学科的重要理论,才能洞察问题本质。本文标题就不去纠结了,100个思维模式可以供你参考。
- 年轻心态:张一鸣 - Stay hungry, Stay young
- 张一鸣在“2016今日头条Bootcamp”上对研发&产品部门应届毕业生发表了题目为“Stay hungry, Stay young”的演讲。多年以后来看,他提的优秀年轻人的五个特质很值得年轻人深思,同样也适合工作老鸟保持年轻的心态。
- 反内耗:停止心理内耗才能变更强
- 真正厉害的人,都是“反内耗”体质,只有停止心理内耗,这样才会一步步变强。很多人抱怨开发越来越卷,而实际上多数人的卷来源自己的'内心的卷'(心理上的内耗),本文主要转载自知乎上一个关于人是如何变强的回答,希望能给你一些启发。
产品相关
产品相关
- 张小龙:微信背后的产品观
- 之前虎嗅曾发表了“和菜头”写的《张小龙:微信背后的产品观》。那篇文章虽基于张小龙的产品经验分享,其实相当多的内容是来自和菜头本人的理解,现在,虎嗅再根据点点网CEO许朝军的博客内容,把张小龙的现场分享实录呈现给大家。
- Martin Fowler: 关注成效而非产出
- 近两年pdai所接触到的项目,很多功能并没有解决用户的痛点,而只是开发设计人员觉得它应该有,这些应该有的背后其实就是Martin Fowler所反对的,他的观点是我们应该关注成效而非产出(用代码量、功能点、还是用户故事) 。本文转载了TW翻译的Martin Fowler的这篇文章,希望能给你带来启发。
- 产品歪楼:如何做好产品决策中的内部环境分析
- 很多时候,产品经理在做产品的过程中,发现产品做着做着就歪楼了,然后就开始烂尾。有些时候,你或许经常会像彩霞仙子一样感叹:“我猜中了开头,却没有猜中者结局!”
团队相关
团队相关
- 华为:软件开发团队如何管理琐碎、突发性任务
- 如何管理琐碎、突发性任务? 请看华为团队的分享。
- 张一鸣:做CEO要避免理性的自负
- “Context,not Control”。 成功的创业者必然会面对公司从小变大的结果。CEO作为创造者与执掌者,需要不断更新自我,及时应对公司发展带来的管理挑战。在源码资本2017年码会上,今日头条创始人CEO张一鸣为码会高低年级的同学分享重量级管理心得:做CEO要避免理性的自负。
- 美团: 研发团队资源成本优化实践
- 很多管理者在业务发展的较前期阶段,可能并没有意识到资源成本膨胀所带来的压力。等到业务到了一定规模,拿到机器账单的时候,惊呼“机器怎么这么费钱”,再想立即降低成本,可能已经错过了最佳时机,因为技术本身是一个相对长期的改造过程。资源成本优化宜早不宜迟。本文我们将分享美团到餐研发团队的资源成本优化实践。
- 哈啰:团队过程管理演进之路
- 职能团队依据业务领域需要划分为跨职能团队,怎么让团队运转起来?怎么组织跨团队的事情?怎么提升团队的自组织能力?怎么了解团队的效能情况?怎么拉通价值流上的角色?本文为你阐述团队管理的进化、精细化之路。本文主要分享哈啰技术团队的文章。
其它分享
其它分享
- 陈春花、赵海然:共生型组织四个特征和四重境界
- 向你推荐关于未来组织架构的可能演进,作为一个技术人提早做好准备是很有必要的。
关于本站点和我
感恩
感恩活着,感谢岁月静好。@pdai
关于我
A. 关于我:如果你我本人以及我是如何构建知识体系等,可以在如下章节中了解。
相关文章
- 关于 - 我
- 你的时间花在哪里,你的收获就在哪里。技术只是技术,生活中的一小部分,仅此而已
- 等在合适的时机会放出我的微信,并且会建学习讨论圈,尽请期待
- 关于 - 赞赏❤️的用途
- 感谢各位读者的支持,能感受到每个留言和每一笔赞赏背后的热情❤️,这是我坚持的动力。我特意整理了超过20元的赞赏者和留言(因为无法导出赞赏记录,我是一条条找记录一个字一个字输入的,只能保留一相对靠前的,以示我对赞赏者的敬意;后续每一笔超过20元的赞赏和留言都会持续记录...)
- 关于 - 如何构建知识体系
- 本文主要小结下我在构建一个知识体系时的思考
- 关于 - 如何自我驱动
- 本文主要介绍我总结这个知识体系所用的工具栈和自我驱动(类似于公司里敏捷开发)
关于本站点:内容,构建和部署
B. 关于本站点:如果你对这个站点感兴趣,可以在如下章节了解,包含排版,搭建,编译,部署,域名,https以及备案等。
相关文章
- 关于文档 - 文档的内容
- 你觉的《Java 全栈知识体系》还应该有哪些内容,或者现有的章节中你发现有好的资源也可以推荐,请在这里留言区向我推荐吧
- 关于 - 网站错误反馈
- 感谢读者Tony的反馈,现增加一个专门放错误反馈的地方。
- 关于 - 最新日更更新清单
- 本文主要记录本站的更新记录, 2021年之前的更新没有记录,2021年一月份开始记录日更清单。
- 关于文档 - 文档的排版
- 统一中文文案、排版的相关用法,降低团队成员之间的沟通成本,增强网站气质。本文来源于 中文文案排版指北,以此规范来约束本站的所有文档
- 关于文档 - 文档的搭建
- 搭建博客有很多选择,平台性的比如: 知名的CSDN, 博客园, 知乎,简书等;自己搭建比如 Hexo, Gitbook, Docisify等等。我有一颗不安分的心,每种我都用过...但是最后的最后我还是选择了将博客逐移至自己搭建的vuepress
- 关于文档 - 文档的自动编译
- 文档托管在Github,有几种选择: Github自带的Github Actions,或者插件Travis CI, 或者插件Circle CI;本文简述本站是如何实现自动化编译的
- 关于文档 - 文档的自动部署
- 本文主要介绍 当前文档是如何在我自己的服务器自动编译部署的
- 关于文档 - 文档的域名,HTTPS,备案
- 本文主要记录 本文档的域名,HTTPS,备案。 文档的域名,HTTPS,备案 这三个步骤不能反,因为存在依赖关系。
关于内容版权
本站点申明如下:
- 我的初衷?:希望我的总结可以帮助到在后端开发迷茫的IT从业者, 永远相信助人者自助;
- 非商业用途?:纯个人学习站点,不会用于商业用途;
- 内容来源?:目前站点内容大约50%内容为原创,50%内容系整合或者转载,我在每篇文章中尽量注明了出处;针对转载或引用的内容,侵删;
- 可以转载?:遵循行业内知识共享协议CC 4.0下可以注明出处转载;
关于我的读书
TODO,这里会总结以下我读过的觉得有意义的书
关于我的技术观
TODO,这里会写一些我的技术观
关于我的小结
TODO, 这里会写一些我的阶段性总结
后面还有哪些内容
注意
本知识体系导读的后续的章节还在紧锣密鼓的添加中, 还有大量的内容即将添加进来,尽请期待...@pdai
感谢您的关注!
有些章节其实我已经梳理或者写过了(可以看其它章节部分,这里我暂时没给链接;还有一部分我隐藏掉了),暂时还没放到这里是因为我觉的还不成体系,我会再次梳理和丰富下并且将BAT大厂的题目融合进来。请多给我一些时间,尽请期待!@pdai