Java 17 新特性概述
JDK 17 在 2021 年 9 月 14 号正式发布了!根据发布的规划,这次发布的 JDK 17 是一个长期维护的版本(LTS)。Java 17 提供了数千个性能、稳定性和安全性更新,以及 14 个 JEP(JDK 增强提案),进一步改进了 Java 语言和平台,以帮助开发人员提高工作效率。JDK 17 包括新的语言增强、库更新、对新 Apple (Mx CPU)计算机的支持、旧功能的删除和弃用,并努力确保今天编写的 Java 代码在未来的 JDK 版本中继续工作而不会发生变化。它还提供语言功能预览和孵化 API,以收集 Java 社区的反馈。@pdai
知识体系
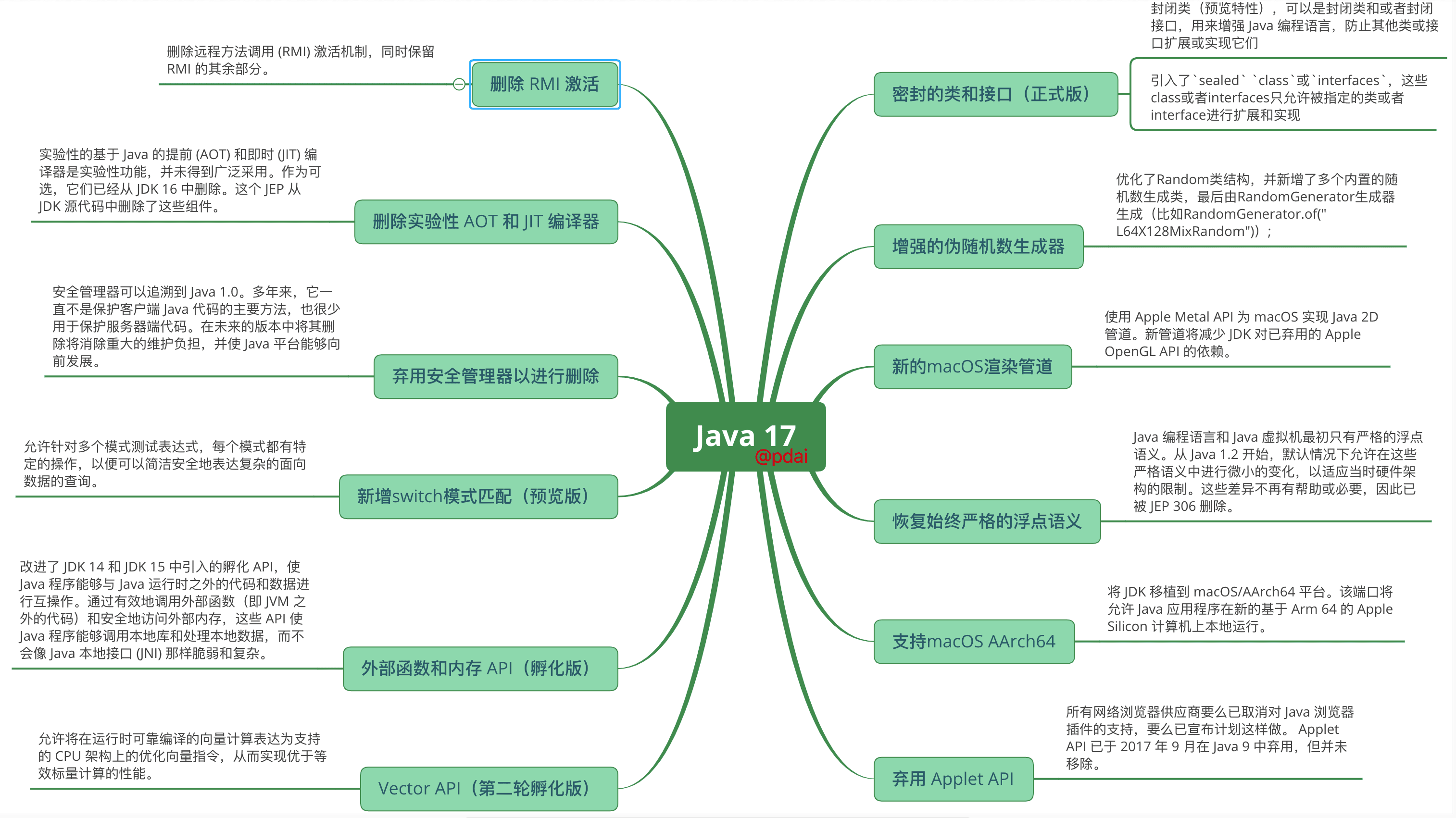
语言特性增强
密封的类和接口(正式版)
封闭类可以是封闭类和或者封闭接口,用来增强 Java 编程语言,防止其他类或接口扩展或实现它们。这个特性由Java 15的预览版本晋升为正式版本。
- 密封的类和接口解释和应用
因为我们引入了sealed class或interfaces,这些class或者interfaces只允许被指定的类或者interface进行扩展和实现。
使用修饰符sealed,您可以将一个类声明为密封类。密封的类使用reserved关键字permits列出可以直接扩展它的类。子类可以是最终的,非密封的或密封的。
之前我们的代码是这样的。
public class Person { } //人
class Teacher extends Person { }//教师
class Worker extends Person { } //工人
class Student extends Person{ } //学生
但是我们现在要限制 Person类 只能被这三个类继承,不能被其他类继承,需要这么做。
// 添加sealed修饰符,permits后面跟上只能被继承的子类名称
public sealed class Person permits Teacher, Worker, Student{ } //人
// 子类可以被修饰为 final
final class Teacher extends Person { }//教师
// 子类可以被修饰为 non-sealed,此时 Worker类就成了普通类,谁都可以继承它
non-sealed class Worker extends Person { } //工人
// 任何类都可以继承Worker
class AnyClass extends Worker{}
//子类可以被修饰为 sealed,同上
sealed class Student extends Person permits MiddleSchoolStudent,GraduateStudent{ } //学生
final class MiddleSchoolStudent extends Student { } //中学生
final class GraduateStudent extends Student { } //研究生
很强很实用的一个特性,可以限制类的层次结构。
- 补充:它是由Amber项目孵化而来(会经历两轮以上预览版本)
什么是Amber项目?
Amber 项目的目标是探索和孵化更小的、以生产力为导向的 Java 语言功能,这些功能已被 OpenJDK JEP 流程接受为候选 JEP。本项目由 Compiler Group 赞助。 大多数 Amber 功能在成为 Java 平台的正式部分之前至少要经过两轮预览。对于给定的功能,每轮预览和最终标准化都有单独的 JEP。此页面仅链接到某个功能的最新 JEP。此类 JEP 可能会酌情链接到该功能的早期 JEP。
工具库的更新
JEP 306:恢复始终严格的浮点语义
Java 编程语言和 Java 虚拟机最初只有严格的浮点语义。从 Java 1.2 开始,默认情况下允许在这些严格语义中进行微小的变化,以适应当时硬件架构的限制。这些差异不再有帮助或必要,因此已被 JEP 306 删除。
JEP 356:增强的伪随机数生成器
为伪随机数生成器 (PRNG) 提供新的接口类型和实现。这一变化提高了不同 PRNG 的互操作性,并使得根据需求请求算法变得容易,而不是硬编码特定的实现。简单而言只需要理解如下三个问题: @pdai
JDK 17之前如何生成随机数?
- Random 类
典型的使用如下,随机一个int值
// random int
new Random().nextInt();
/**
* description 获取指定位数的随机数
*
* @param length 1
* @return java.lang.String
*/
public static String getRandomString(int length) {
String base = "abcdefghijklmnopqrstuvwxyz0123456789";
Random random = new Random();
StringBuilder sb = new StringBuilder();
for (int i = 0; i < length; i++) {
int number = random.nextInt(base.length());
sb.append(base.charAt(number));
}
return sb.toString();
}
- ThreadLocalRandom 类
提供线程间独立的随机序列。它只有一个实例,多个线程用到这个实例,也会在线程内部各自更新状态。它同时也是 Random 的子类,不过它几乎把所有 Random 的方法又实现了一遍。
/**
* nextInt(bound) returns 0 <= value < bound; repeated calls produce at
* least two distinct results
*/
public void testNextIntBounded() {
// sample bound space across prime number increments
for (int bound = 2; bound < MAX_INT_BOUND; bound += 524959) {
int f = ThreadLocalRandom.current().nextInt(bound);
assertTrue(0 <= f && f < bound);
int i = 0;
int j;
while (i < NCALLS &&
(j = ThreadLocalRandom.current().nextInt(bound)) == f) {
assertTrue(0 <= j && j < bound);
++i;
}
assertTrue(i < NCALLS);
}
}
- SplittableRandom 类
非线程安全,但可以 fork 的随机序列实现,适用于拆分子任务的场景。
/**
* Repeated calls to nextLong produce at least two distinct results
*/
public void testNextLong() {
SplittableRandom sr = new SplittableRandom();
long f = sr.nextLong();
int i = 0;
while (i < NCALLS && sr.nextLong() == f)
++i;
assertTrue(i < NCALLS);
}
为什么需要增强?
- 上述几个类实现代码质量和接口抽象不佳
- 缺少常见的伪随机算法
- 自定义扩展随机数的算法只能自己去实现,缺少统一的接口
增强后是什么样的?
代码的优化自不必说,我们就看下新增了哪些常见的伪随机算法

如何使用这个呢?可以使用RandomGenerator
RandomGenerator g = RandomGenerator.of("L64X128MixRandom");
JEP 382:新的macOS渲染管道
使用 Apple Metal API 为 macOS 实现 Java 2D 管道。新管道将减少 JDK 对已弃用的 Apple OpenGL API 的依赖。
目前默认情况下,这是禁用的,因此渲染仍然使用OpenGL API;要启用metal,应用程序应通过设置系统属性指定其使用:
-Dsun.java2d.metal=true
Metal或OpenGL的使用对应用程序是透明的,因为这是内部实现的区别,对Java API没有影响。Metal管道需要macOS 10.14.x或更高版本。在早期版本上设置它的尝试将被忽略。
新的平台支持
JEP 391:支持macOS AArch64
将 JDK 移植到 macOS/AArch64 平台。该端口将允许 Java 应用程序在新的基于 Arm 64 的 Apple Silicon 计算机上本地运行。
旧功能的删除和弃用
JEP 398:弃用 Applet API
所有网络浏览器供应商要么已取消对 Java 浏览器插件的支持,要么已宣布计划这样做。 Applet API 已于 2017 年 9 月在 Java 9 中弃用,但并未移除。
JEP 407:删除 RMI 激活
删除远程方法调用 (RMI) 激活机制,同时保留 RMI 的其余部分。
JEP 410:删除实验性 AOT 和 JIT 编译器
实验性的基于 Java 的提前 (AOT) 和即时 (JIT) 编译器是实验性功能,并未得到广泛采用。作为可选,它们已经从 JDK 16 中删除。这个 JEP 从 JDK 源代码中删除了这些组件。
JEP 411:弃用安全管理器以进行删除
安全管理器可以追溯到 Java 1.0。多年来,它一直不是保护客户端 Java 代码的主要方法,也很少用于保护服务器端代码。在未来的版本中将其删除将消除重大的维护负担,并使 Java 平台能够向前发展。
新功能的预览和孵化API
JEP 406:新增switch模式匹配(预览版)
允许针对多个模式测试表达式,每个模式都有特定的操作,以便可以简洁安全地表达复杂的面向数据的查询。
JEP 412:外部函数和内存api (第一轮孵化)
改进了 JDK 14 和 JDK 15 中引入的孵化 API,使 Java 程序能够与 Java 运行时之外的代码和数据进行互操作。通过有效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存,这些 API 使 Java 程序能够调用本地库和处理本地数据,而不会像 Java 本地接口 (JNI) 那样脆弱和复杂。这些 API 正在巴拿马项目中开发,旨在改善 Java 和非 Java 代码之间的交互。
JEP 414:Vector API(第二轮孵化)
如下内容来源于https://xie.infoq.cn/article/8304c894c4e38318d38ceb116,作者是九叔
AVX(Advanced Vector Extensions,高级向量扩展)实际上是 x86-64 处理器上的一套 SIMD(Single Instruction Multiple Data,单指令多数据流)指令集,相对于 SISD(Single instruction, Single dat,单指令流但数据流)而言,SIMD 非常适用于 CPU 密集型场景,因为向量计算允许在同一个 CPU 时钟周期内对多组数据批量进行数据运算,执行性能非常高效,甚至从某种程度上来看,向量运算似乎更像是一种并行任务,而非像标量计算那样,在同一个 CPU 时钟周期内仅允许执行一组数据运算,存在严重的执行效率低下问题。

随着 Java16 的正式来临,开发人员可以在程序中使用 Vector API 来实现各种复杂的向量计算,由 JIT 编译器 Server Compiler(C2)在运行期将其编译为对应的底层 AVX 指令执行。当然,在讲解如何使用 Vector API 之前,我们首先来看一个简单的标量计算程序。示例:
void scalarComputation() {
var a = new float[10000000];
var b = new float[10000000];
// 省略数组a和b的赋值操作
var c = new float[10000000];
for (int i = 0; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
在上述程序示例中,循环体内每次只能执行一组浮点运算,总共需要执行约 1000 万次才能够获得最终的运算结果,可想而知,这样的执行效率必然低效。值得庆幸的是,从 Java6 的时代开始,Java 的设计者们就在 HotSpot 虚拟机中引入了一种被称之为 SuperWord 的自动向量优化算法,该算法缺省会将循环体内的标量计算自动优化为向量计算,以此来提升数据运算时的执行效率。当然,我们可以通过虚拟机参数-XX:-UseSuperWord来显式关闭这项优化(从实际测试结果来看,如果不开启自动向量优化,存在约 20%~22%之间的性能下降)。
在此大家需要注意,尽管 HotSpot 缺省支持自动向量优化,但局限性仍然非常明显,首先,JIT 编译器 Server Compiler(C2)仅仅只会对循环体内的代码块做向量优化,并且这样的优化也是极不可靠的;其次,对于一些复杂的向量运算,SuperWord 则显得无能为力。因此,在一些特定场景下(比如:机器学习,线性代数,密码学等),建议大家还是尽可能使用 Java16 为大家提供的 Vector API 来实现复杂的向量计算。示例:
// 定义256bit的向量浮点运算
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_256;
void vectorComputation(float[] a, float[] b, float[] c) {
var i = 0;
var upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.mul(va).
add(vb.mul(vb)).
neg();
vc.intoArray(c, i);
}
for (; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
值得注意的是,Vector API 包含在 jdk.incubator.vector 模块中,程序中如果需要使用 Vector API 则需要在 module-info.java 文件中引入该模块。:
module java16.test{
requires jdk.incubator.vector;
}
JEP 389:外部链接器 API(孵化器)
该孵化器 API 提供了静态类型、纯 Java 访问原生代码的特性,该 API 将大大简化绑定原生库的原本复杂且容易出错的过程。Java 1.1 就已通过 Java 原生接口(JNI)支持了原生方法调用,但并不好用。Java 开发人员应该能够为特定任务绑定特定的原生库。它还提供了外来函数支持,而无需任何中间的 JNI 粘合代码。
JEP 393:外部存储器访问 API(第三次孵化)
在 Java 14 和 Java 15 中作为孵化器 API 引入的这个 API 使 Java 程序能够安全有效地对各种外部存储器(例如本机存储器、持久性存储器、托管堆存储器等)进行操作。它提供了外部链接器 API 的基础。
如下内容来源于https://xie.infoq.cn/article/8304c894c4e38318d38ceb116,作者是九叔
在实际的开发过程中,绝大多数的开发人员基本都不会直接与堆外内存打交道,但这并不代表你从未接触过堆外内存,像大家经常使用的诸如:RocketMQ、MapDB 等中间件产品底层实现都是基于堆外存储的,换句话说,我们几乎每天都在间接与堆外内存打交道。那么究竟为什么需要使用到堆外内存呢?简单来说,主要是出于以下 3 个方面的考虑:
- 减少 GC 次数和降低 Stop-the-world 时间;
- 可以扩展和使用更大的内存空间;
- 可以省去物理内存和堆内存之间的数据复制步骤。
在 Java14 之前,如果开发人员想要操作堆外内存,通常的做法就是使用 ByteBuffer 或者 Unsafe,甚至是 JNI 等方式,但无论使用哪一种方式,均无法同时有效解决安全性和高效性等 2 个问题,并且,堆外内存的释放也是一个令人头痛的问题。以 DirectByteBuffer 为例,该对象仅仅只是一个引用,其背后还关联着一大段堆外内存,由于 DirectByteBuffer 对象实例仍然是存储在堆空间内,只有当 DirectByteBuffer 对象被 GC 回收时,其背后的堆外内存才会被进一步释放。
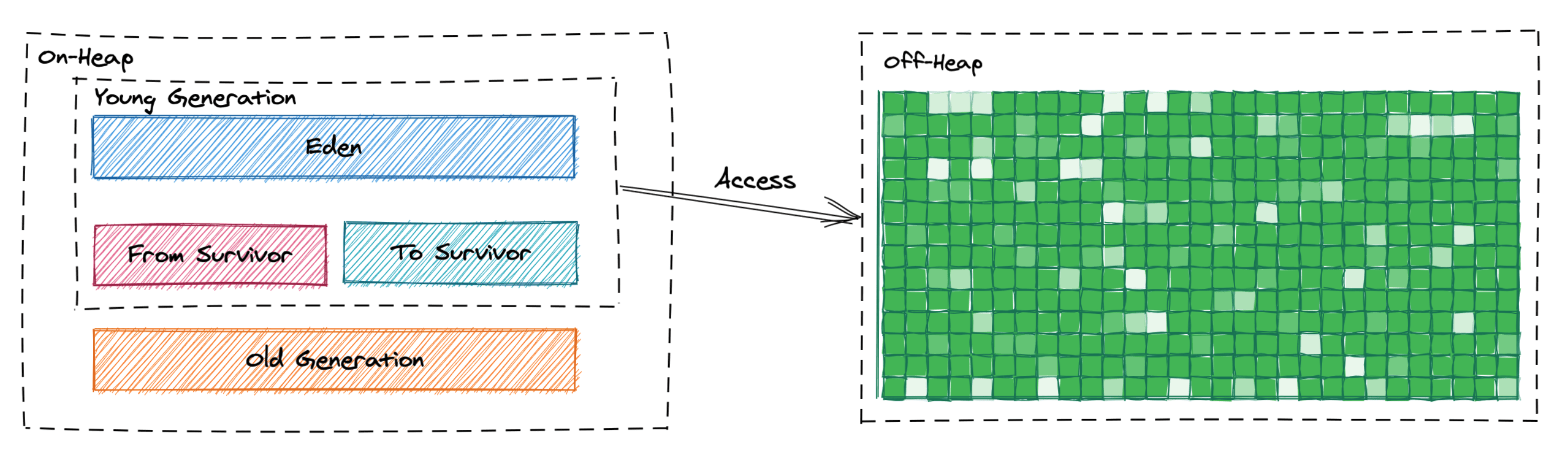
在此大家需要注意,程序中通过 ByteBuffer.allocateDirect()方法来申请物理内存资源所耗费的成本远远高于直接在 on-heap 中的操作,而且实际开发过程中还需要考虑数据结构如何设计、序列化/反序列化如何支撑等诸多难题,所以与其使用语法层面的 API 倒不如直接使用 MapDB 等开源产品来得更实惠。
如今,在堆外内存领域,我们似乎又多了一个选择,从 Java14 开始,Java 的设计者们在语法层面为大家带来了崭新的 Memory Access API,极大程度上简化了开发难度,并得以有效的解决了安全性和高效性等 2 个核心问题。示例:
// 获取内存访问var句柄
var handle = MemoryHandles.varHandle(char.class,
ByteOrder.nativeOrder());
// 申请200字节的堆外内存
try (MemorySegment segment = MemorySegment.allocateNative(200)) {
for (int i = 0; i < 25; i++) {
handle.set(segment, i << 2, (char) (i + 1 + 64));
System.out.println(handle.get(segment, i << 2));
}
}
关于堆外内存段的释放,Memory Access API 提供有显式和隐式 2 种方式,开发人员除了可以在程序中通过 MemorySegment 的 close()方法来显式释放所申请的内存资源外,还可以注册 Cleaner 清理器来实现资源的隐式释放,后者会在 GC 确定目标内存段不再可访问时,释放与之关联的堆外内存资源。
参考文章
https://www.oracle.com/news/announcement/oracle-releases-java-17-2021-09-14/
https://openjdk.java.net/projects/amber/
https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/random/package-summary.html