大数据处理基础架构
大数据架构旨在处理对传统数据库系统来说太大或太复杂的数据的采集、处理和分析。目前大数据的含义已经不再是数据量的大小,而是越来越多偏向于通过高级分析从数据集中提取的价值。本文主要介绍大数据含义以及基础的大数据架构包含的模块。@pdai
什么是大数据架构
大数据架构旨在处理对传统数据库系统来说太大或太复杂的数据的采集、处理和分析。对于某些人来说,这可能意味着数百 GB 的数据,而对于其他人来说,这意味着数百 TB 的数据。随着处理大数据集的工具不断进步,大数据的意义也在不断发展。目前大数据的含义已经不再是数据量的大小,而是越来越多偏向于通过高级分析从数据集中提取的价值。
多年来,数据格局发生了变化,这些变化体现如下,这些都是大数据架构寻求解决的挑战。
- 我们对期望对数据执行的操作发生变化,以往我们可能只是简单查询,而现在我们期望从数据中挖掘更多的有价值的信息
- 存储成本已大幅下降,而收集数据的方式却在不断增长
- 有些数据来得很快,需要不断地收集和观察;其他数据到达速度较慢,但以非常大的块形式出现,通常以长时间的历史数据的形式出现
- 此外对于高级分析问题,还需要机器学习分析
大数据解决方案通常应用场景如下:
- 静态大数据源的批处理
- 实时处理运动中的大数据
- 大数据交互探索
- 预测分析和机器学习
当我们需要时考虑大数据架构,需要考虑:
- 存储和处理对于传统数据库而言过大的数据量。
- 转换非结构化数据以进行分析和报告。
- 实时或低延迟捕获、处理和分析无限制的数据流。
基础的大数据架构
下图显示了适合大数据架构的逻辑组件,个别解决方案可能不包含数据环节。
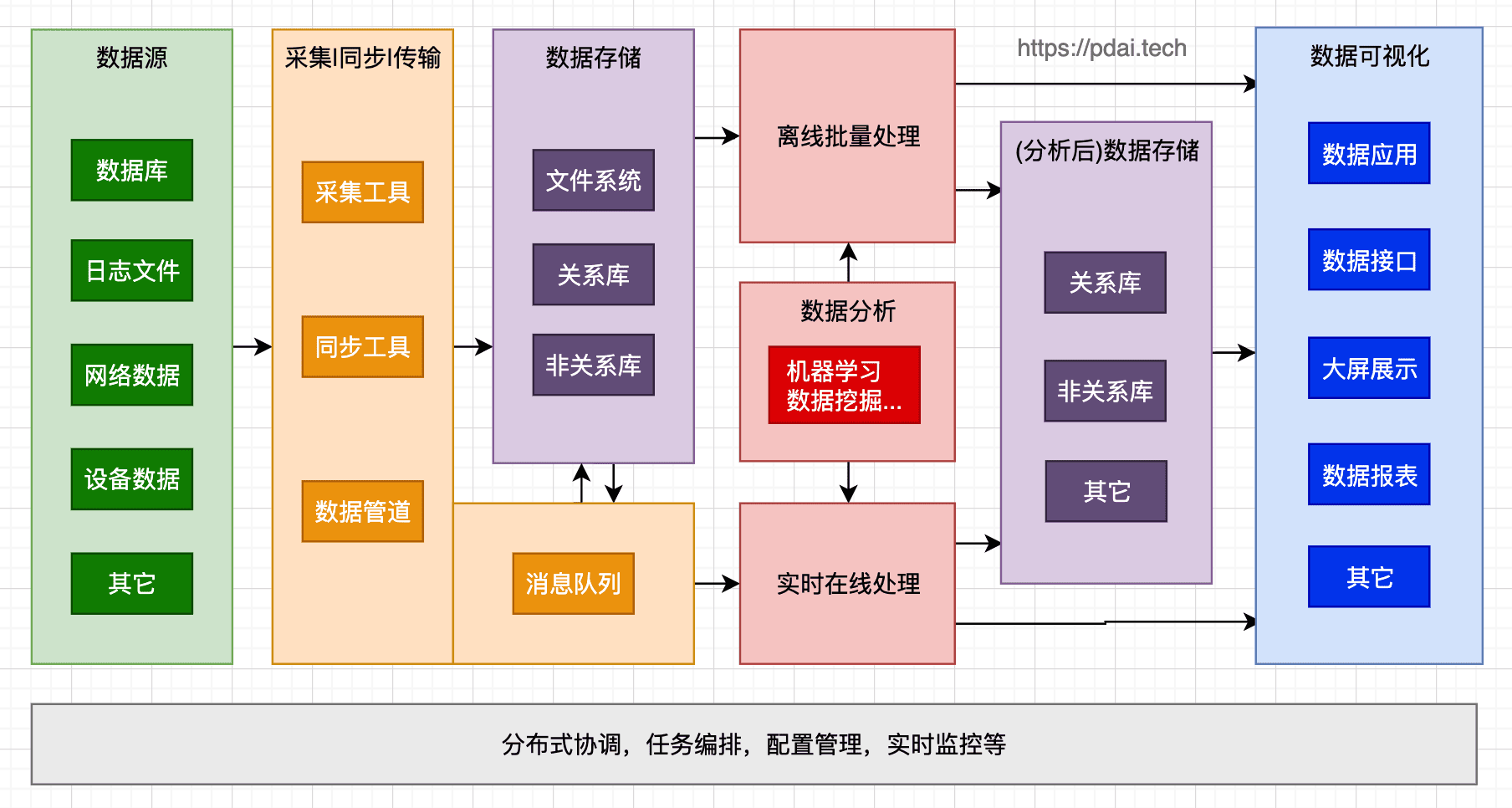
大多数大数据架构包括以下部分或全部组件:
数据源(数据采集)
所有大数据解决方案都从一个或多个数据源开始。例子包括:
- 应用程序数据存储,例如关系数据库。
- 应用程序生成的静态文件,例如 Web 服务器日志文件。
- 实时数据源,例如 IoT 设备。
数据存储
批处理操作的数据通常存储在分布式文件存储中,该存储可以保存大量各种格式的大文件。这种存储通常称为数据湖。
从广义的数据存储上理解
对于数据仓库和数据湖的差别,具体可以看:数据湖 vs. 数据仓库 vs. 数据湖仓库
- 数据仓库
- 数据湖
- 数据湖仓库
从狭义的数据存储上理解
- 关系型数据库
- 常规: Oracle、MySQL, PostgreSQL
- 分布式: DRDS、TiDB、GreenPlum、Cobar、Aurora、Mycat
- 非关系型数据库
- 分析型数据库: Kylin、AnalyticDB、Druid、Clickhouse、Vertica、MonetDB、InfiniDB、LucidDB
- 搜索数据库: Elasticsearch、Solr、OpenSearch
- 图数据库: Titan、Neo4J、ArangoDB、OrientDB、MapGraph、ALLEGROGRAPH
- 列存储数据库: Phoenix、Cassandra、Hbase、Kudu、Hypertable
- 文档数据库: MongoDb、DocumentDB、CouchDB、OrientDB、MarkLogic
- 键值存储数据库: Redis、Memcached、Tair
- 时序数据库: influxdb, promousedb
- 文件/对象存储系统: HDFS、OpenStack Swift、Ceph、GlusterFS、Lustre、AFS、OSS
批处理
由于数据集非常大,大数据解决方案通常必须使用长时间运行的批处理作业来处理数据文件,以过滤、聚合和以其他方式准备数据以供分析。通常这些作业涉及读取源文件、处理它们以及将输出写入新文件。选项包括在 Azure Data Lake Analytics 中运行 U-SQL 作业,在 HDInsight Hadoop 群集中使用 Hive、Pig 或自定义 Map/Reduce 作业,或者在 HDInsight Spark 群集中使用 Java、Scala 或 Python 程序。
实时消息采集
如果解决方案包含实时源,则架构必须包含一种捕获和存储实时消息以进行流处理的方法。这可能是一个简单的数据存储,传入的消息被放入一个文件夹中进行处理。但是,许多解决方案需要一个消息摄取存储来充当消息的缓冲区,并支持横向扩展处理、可靠传递和其他消息队列语义。流架构的这一部分通常称为流缓冲。选项包括 Azure 事件中心、Azure IoT 中心和 Kafka。
流处理
捕获实时消息后,解决方案必须通过过滤、聚合和以其他方式准备数据以供分析来处理它们。然后将处理后的流数据写入输出接收器。Azure 流分析提供基于永久运行的 SQL 查询的托管流处理服务,这些查询在无界流上运行。您还可以在 HDInsight 群集中使用开源 Apache 流技术,例如 Storm 和 Spark Streaming。
分析后数据存储
许多大数据解决方案为分析准备数据,然后以结构化格式提供处理后的数据,可以使用分析工具进行查询。用于服务于这些查询的分析数据存储可以是 Kimball 风格的关系数据仓库,如大多数传统商业智能 (BI) 解决方案中所见。或者,数据可以通过低延迟 NoSQL 技术(例如 HBase)或交互式 Hive 数据库呈现,该数据库提供对分布式数据存储中数据文件的元数据抽象。Azure Synapse Analytics 为大规模、基于云的数据仓库提供托管服务。HDInsight 支持 Interactive Hive、HBase 和 Spark SQL,它们也可用于提供数据以供分析。
分析和报告
大多数大数据解决方案的目标是通过分析和报告提供对数据的洞察。为了使用户能够分析数据,该体系结构可能包括数据建模层,例如 Azure Analysis Services 中的多维 OLAP 多维数据集或表格数据模型。它还可能支持自助式 BI,使用 Microsoft Power BI 或 Microsoft Excel 中的建模和可视化技术。分析和报告也可以采用数据科学家或数据分析师进行交互式数据探索的形式。对于这些场景,许多 Azure 服务都支持分析笔记本,例如 Jupyter,使这些用户能够利用他们现有的 Python 或 R 技能。对于大规模数据探索,您可以使用独立的 Microsoft R Server 或与 Spark 一起使用。
编排
大多数大数据解决方案由重复的数据处理操作组成,封装在工作流中,转换源数据,在多个源和接收器之间移动数据,将处理后的数据加载到分析数据存储中,或者将结果直接推送到报告或仪表板。要自动化这些工作流,您可以使用 Azure 数据工厂或 Apache Oozie 和 Sqoop 等编排技术。