美团: 美团图灵机器学习平台性能起飞之内存优化
图灵平台是美团履约平台技术部2018年开始自研的算法平台,提供模型全生命周期的一站式服务,旨在帮助算法同学脱离繁琐的工程化开发,把有限的精力聚焦于业务和算法的迭代优化中。随着美团图灵机器学习平台的发展,图灵技术团队在内存优化、计算优化、磁盘IO优化三个方面沉淀了一系列性能优化技术。我们将以连载的方式为大家揭秘这些技术。本文作为该系列的开篇之作,将重点为大家介绍内存优化。
1. 业务背景
图灵平台主要包括机器学习平台、特征平台、图灵在线服务(Online Serving)、AB实验平台四大功能,具体可参考《一站式机器学习平台建设实践》以及《算法平台在线服务体系的演进与实践》这两篇博客。其中,图灵机器学习平台的离线训练引擎是基于Spark实现的。
随着图灵的用户增长,越来越多算法模型在图灵平台上完成迭代,优化离线训练引擎的性能和吞吐对于节约离线计算资源显得愈发重要。经过半年持续的迭代,我们积累了一系列独特的优化方法,使图灵机器学习平台的离线资源消耗下降80%,生产任务平均耗时下降63%(如下图所示),图灵全平台的训练任务在性能层面都得到了较为明显的提升。
资源消耗下降:
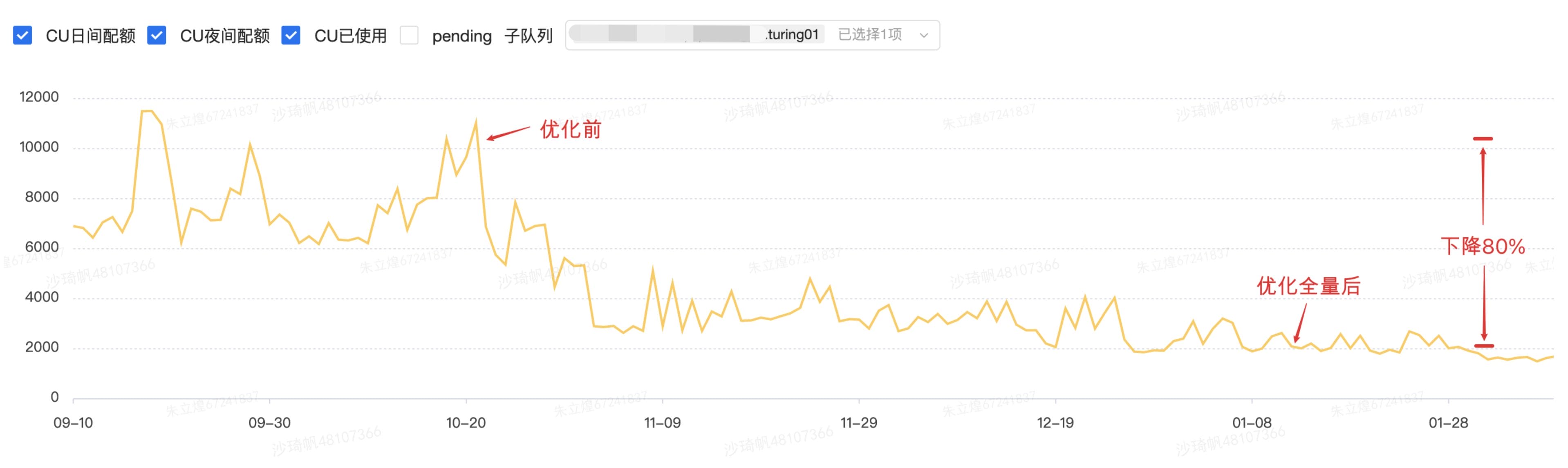
当前平台性能:
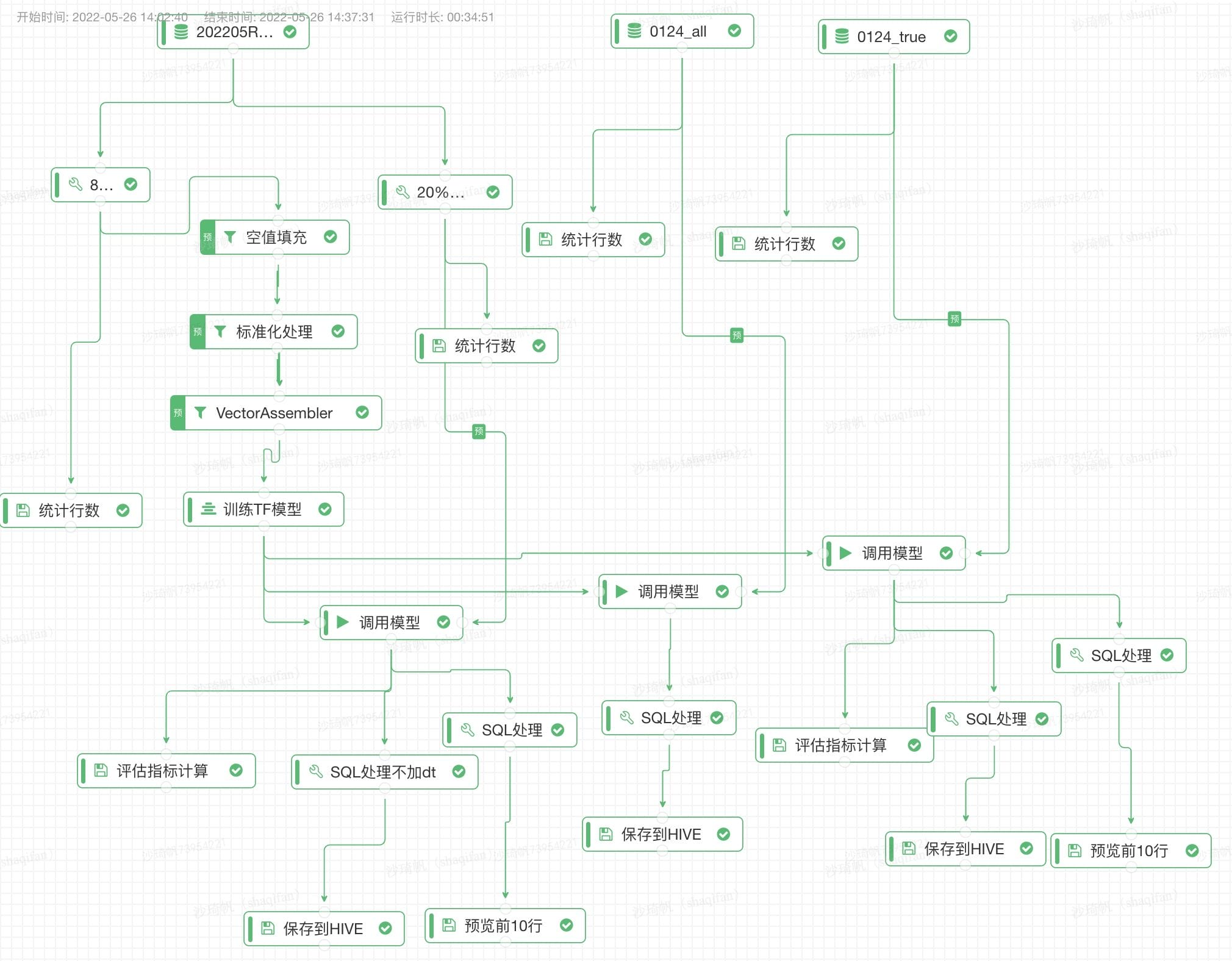
下图是某位图灵用户的实验。使用100万数据训练深度模型,总计约29亿的数据调用深度模型,计算评估指标并保存到Hive,整个实验只需要35分钟。其中Spark开启DynamicAllocation,maxExecutor=400 ,单个Executor为7Core16GB。
2. 图灵训练引擎优化
那么,图灵训练引擎的性能优化是如何做到的呢?我们的优化分为内存优化、计算优化、磁盘IO优化三个层面。
内存优化包括列裁切、自适应Cache、算子优化。我们借鉴Spark SQL原理设计了列裁切,可以自动剔除各组件中用户实际没有使用的字段,以降低内存占用。何时对Dataset Persist和Unpersist一直是Spark代码中的取舍问题,针对用户不熟悉Persist和Unpersist时机这个问题,我们将多年的开发经验沉淀在图灵中,结合列裁切技术实现自适应Cache。在计算优化方面,我们完成了图优化、Spark源码优化、XGB源码优化。在磁盘IO优化方面,我们创新性的实现了自动化小文件保存优化,能够使用一个Action实现多级分区表小文件的合并保存。
此外,我们实现的TFRecord表示优化技术,成功将Spark生成的TFRecord体积减少50%。因图灵平台使用的优化技巧较多,我们将分成多篇文章为大家逐一介绍这些优化技术。

而在众多优化中,收益最高、适用性最广的技术的就是算子优化,这项技术极大提升了图灵训练引擎的吞吐量。本篇文章首先将为大家介绍内存优化中的算子优化技术。
3. Spark算子解读
同样的业务需求,不同的算子实现会有不一样的特性。我们将多年的Spark开发技巧总结在下表中:
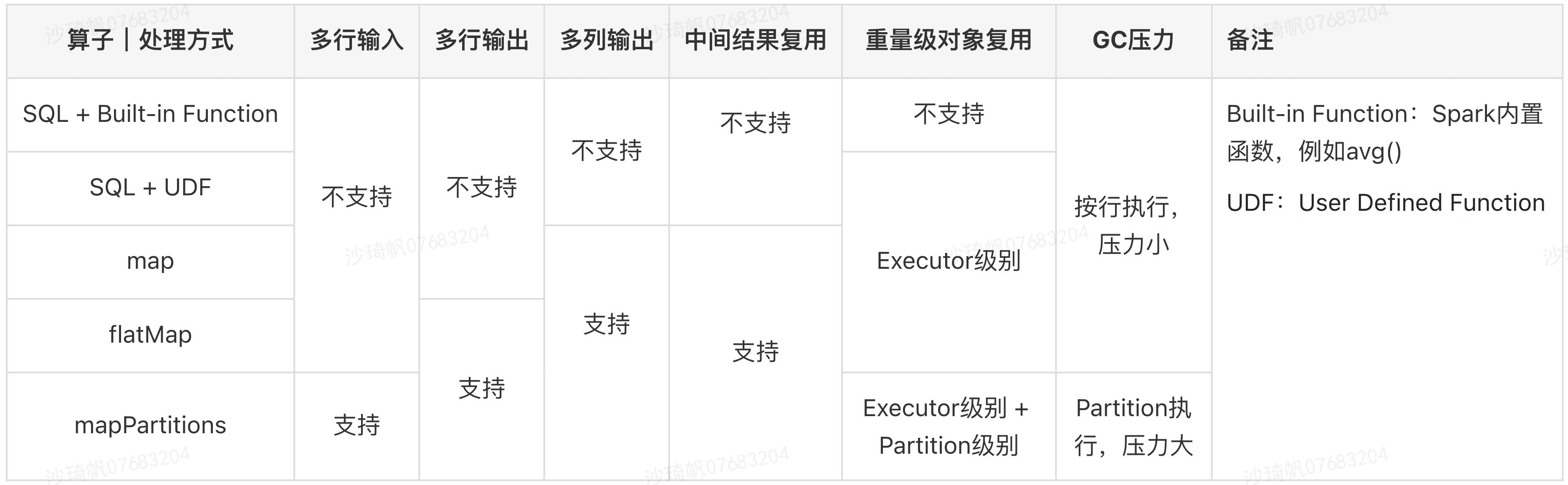
- 多行输入多行输出:多行数据一起进入内存处理。输出多行数据。
- 多列输出:特定场景下,我们希望输出多个字段。
- SQL场景下只能输出Struct,再从Struct中SELECT各字段。
- map/flatMap/mapPartitions可以轻松输出任意个字段。
- 中间结果复用:
- SQL场景下:SQL场景下只能先SELECT一次得到中间变量,再SELECT中间变量完成后续处理。
- map/flatMap/mapPartitions可将计算逻辑封装在函数内。
- 重量级对象复用:
- Executor级别,例如可以通过广播变量实现,或者通过静态类成员变量的“懒汉”模式实现。
- Partition级别,mapPartitions时,先创建对象,后迭代数据,这个对象可在Partition内复用。
通过对比我们发现,mapPartitions是各类算子中最为灵活——可以灵活实现输入M条输出N条数据,可以输出任意数量的字段,还可以实现重量级对象在Partition或Executor级别上的复用。mapPartitions因其强大的功能和灵活可定制性,在图灵训练引擎的开发中有着举足轻重的地位(例如按Batch调用深度模型、上下采样、Partition统计等组件,都是基于该算子实现)。但是mapPartitions也有一个不足之处。
4. mapPartitions之殇
相信大部分读者都曾经写过这样的代码,创建一个重量级对象在Partition内完成复用,而不是像map算子那样每处理一行数据创建一个对象。
mapPartitions模板,重量级对象复用
dataset.mapPartitions((MapPartitionsFunction<Row, Row>) iterator -> {
HeavyObject obj = new HeavyObject();
List<Row> list = new ArrayList<>();
// 遍历处理数据
while (iterator.hasNext()) {
Row row = iterator.next();
// 拼凑batch或逐条处理
// ....
obj.process(row)
// batch add或逐条add
list.add(...);
}
// 返回list的迭代器
return list.iterator();
}, RowEncoder.apply(schema));
熟悉mapPartitions的同学都知道,这段代码完成了重量级对象的复用,相比map算子好像已经减少了大量GC,但这样仍旧非常容易溢出。那么:
- 为什么mapPartitions算子容易溢出呢?
- 当多个mapPartitions算子串联的时候又是如何GC的呢?
5. Spark Pipeline中的mapPartitions
在进行下一部分讲解之前,我们先简要介绍一下Spark的懒执行机制。Spark的算子分为Action和Transformation两大类。RDD的依赖关系构成了数据处理的有向无环图DAG。只有当Action算子出现时,才会执行Action算子与前面一系列Transformation算子构成的DAG。Spark还会根据Shuffle将DAG划分成多个Stage进行计算,Shuffle过程需要跨节点交换数据,会产生大量的磁盘IO和网络IO。而每个Stage内的计算则构成了Pipeline,在内存中进行。
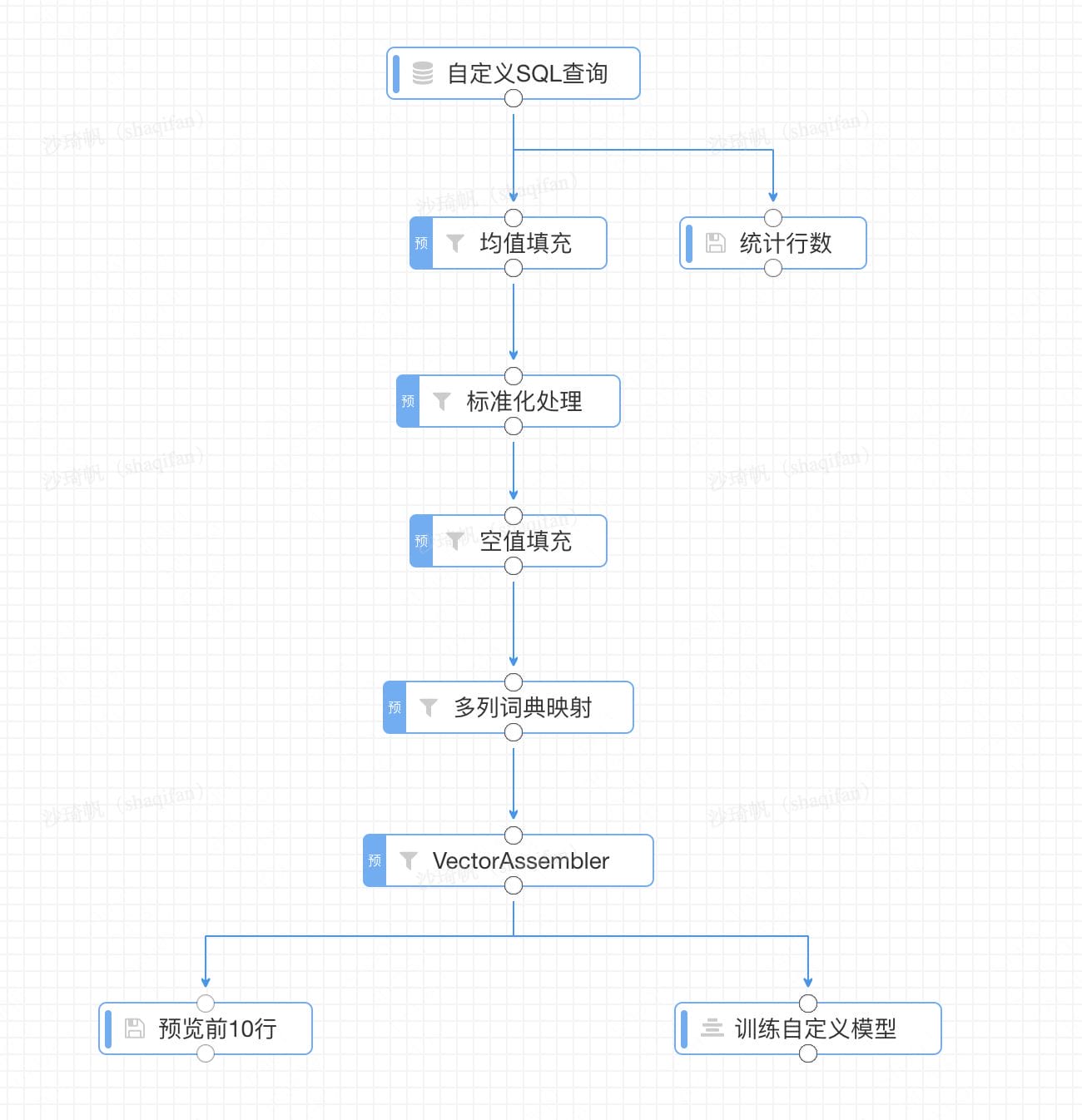
我们以上图为例,该同学实验中的多列词典映射组件,对大量的特征做了词典映射计算。多列词典映射组件包含两个部分,计算词典和应用词典。
- 计算词典:通过去重和collect生成了各个特征的词典,每个特征词典的计算都伴随着1次Shuffle和1次Action。
- 应用词典:将特征根据词典映射成唯一ID,不存在Shuffle。
与Spark StringIndexer的Pipeline优化相似,当进行多个特征的词典映射计算时,图灵机器学习平台会将计算词典的Action单独执行,而多个应用词典则一起执行。
词典生成后,所有应用词典的计算逻辑(mapPartitions Transformation)不存在Shuffle,因此被划分到同一个Stage中,所有mapPartitions算子将串联成一条非常长的Pipeline。最终由后面的Action算子触发提交Job,执行该Pipeline。Stage的划分可参考下图:
应用词典的实现中,每个mapPartitionsFunction中都新建了一个ArrayList充当Buffer来存储计算后的数据,最终返回ArrayList.iterator()。执行时,每次应用词典都会将整个Partition的数据拉入ArrayList当中。上述词典映射串联构成Pipeline的时候,内存中会有多少数据呢?
带着这个疑问,让我们走进Spark的源代码,看看mapPartitionsFunction是如何构成Spark Pipeline的。
Spark的一个Stage中会划分为多个Task,除了union和coalesce的场景,1个Partition对应1个Task。Task的执行通过抽象方法runTask()完成,以实现类ResultTask为例,最后runTask()方法调用了rdd.iterator()。
ResultTask.scala
override def runTask(context: TaskContext): U = {
...... // 源码缩略不进行展示:初始化一些需要的对象
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
// 这里的func()调用了rdd.iterator()
func(context, rdd.iterator(partition, context))
}
而RDD的iterator方法的源码如下,其调用逻辑最终都会进入computeOrReadCheckpoint方法,若没有CheckPoint则进入compute方法执行计算。以MapPartitionsRDD类为例,获取父RDD的Iterator并传入自己的计算逻辑函数f中。
RDD.scala
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context) // 内部依然调用下面的computeOrReadCheckpoint(partition, context)
} else {
computeOrReadCheckpoint(split, context)
}
}
// StorageLevel不为NONE时调用的方法
private[spark] def getOrCompute(partition: Partition, context: TaskContext): Iterator[T] = {
...... // 初始化相关变量
SparkEnv.get.blockManager.getOrElseUpdate(blockId, storageLevel, elementClassTag, () => {
readCachedBlock = false
// 内部依然调用iterator()中的computeOrReadCheckpoint方法
computeOrReadCheckpoint(partition, context)
}) match {
...... // 源码缩略不进行展示:按case包装为对应iterator返回
}
}
// 默认调用该方法
private[spark] def computeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T] = {
if (isCheckpointedAndMaterialized) {
// 有checkpoint或materialized则返回依赖关系中第一个父RDD的iterator
firstParent[T].iterator(split, context)
} else {
// 调用当前RDD的compute方法计算,内部的计算逻辑包含了用户编写的代码
compute(split, context)
}
}
MapPartitionsRDD.scala
override def compute(split: Partition, context: TaskContext): Iterator[U] =
// 用户编写的代码逻辑被封装为函数‘f’,在此接受参数后执行
f(context, split.index, firstParent[T].iterator(split, context))
为了更清晰的解释这个问题,以下述代码为例。
Example
val rddA = initRDD(); // 获取一个RDD
//funcA、funcB、funcC均为用户的代码逻辑
val rddB = rddA.mapPartitions(funcA)
val rddC = rddB.mapPartitions(funcB)
val rddD = rddC.mapPartitions(funcC)
rddD.count()
在遇到count算子时会进行RDD回溯,最终的形成计算链路为fCount(funcC(funcB(funcA(rddA.iterator=>iterator)))),由此构成了Pipeline,以多个mapPartitions + ArrayList.iterator()串联的代码展开则如下所示:
Example
iteratorA => // iteratorA:初始RDD对应Partition的输出迭代器
var list = List[Row]()
while (iteratorA.hasNext) {
list = process(iteratorA.next()) +: list // funcA:每条拉至内存处理后加入resultList
}
val iteratorB = list.iterator
iteratorB => // iteratorB:rddA对应Partition的输出迭代器
var list = List[Row]()
while (iteratorB.hasNext) {
list = process(iteratorB.next()) +: list // funcB:每条数据拉至内存处理后加入resultList
}
val iteratorC = list.iterator
iteratorC => // iteratorC:rddB对应Partition的输出迭代器
var list = List[Row]()
while (iteratorC.hasNext) {
list = process(iteratorC.next()) +: list // funcC:每条数据拉至内存处理后加入resultList
}
val iteratorD = list.iterator
iteratorD => count()
回看mapPartitions模板,作为Buffer的ArrayList是每个mapPartitionsFunction的局部变量,ArrayList.iterator()引用了这个Buffer,结合上面的源码我们知道,子RDD会引用父RDD的Iterator。结合该同学的实验分析,每个RDD中的计算都形成了一个Array Buffer,在RDD的function调用链路中Array Buffer2依赖Array Buffer1.iterator(),Array Buffer3依赖Array Buffer2.iterator()。
以此类推,在计算RDD-3时,RDD-1的func1已经出栈,且RDD-3不依赖Array Buffer1.iterator(),因此局部变量Array Buffer1可以被GC。由此可见在Stage-应用多个词典的计算过程中,内存占用的峰值达到了两个Array Buffer,也就是两倍partitionSize。
为了完全证实这个想法,又进行了实际的测试验证:初始化1个单Partition的RDD,并且该Partition的数据量为300万,占用内存大约为180M。接着将这些数据利用多个mapPartitions + ArrayList.iterator()串联,每输入1个对象,生成1个新对象放入Buffer中,最后用rdd.count()触发Action,整个执行流程中只包含一个Stage。运行的JVM堆内存设置为512M,以此来观察堆内存中的实例对象及其GC活动是否符合只有两个Buffer的预期。
观察结果如下,每一行数据以一个GenericRowWithSchema实例存在并加入ArrayList中,其计算过程中最大的峰值正好为600万即两倍的分区数据量。GC以周期性的活动去销毁上上个mapPartitions中的无用Buffer,并且堆内存保持在了最大约两倍的数据占用量(约360M),因此验证了推断。以下是测试中的GenericRowWithSchema对象实例计数图、内存实时占用以及GC活动统计图。
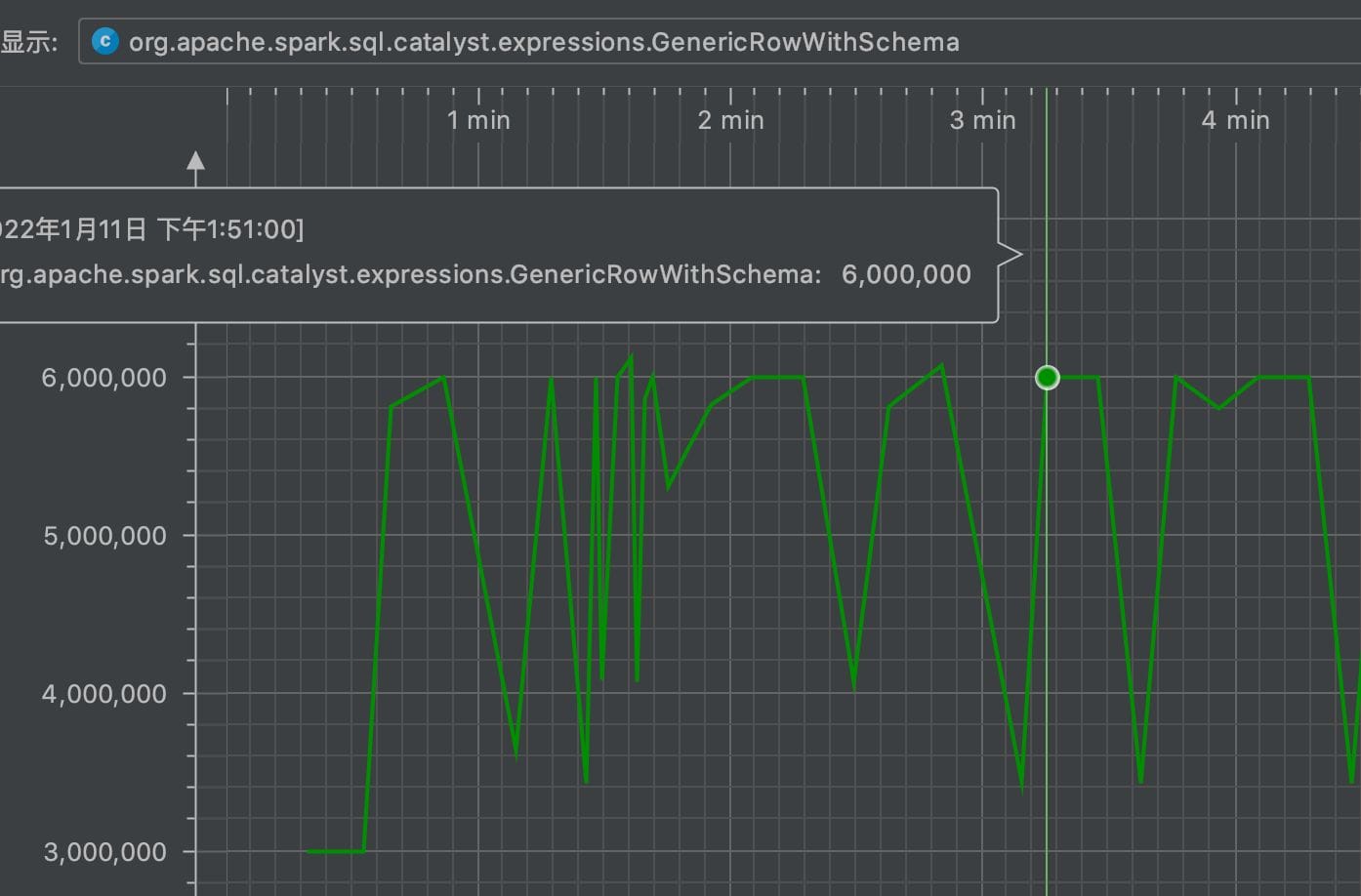
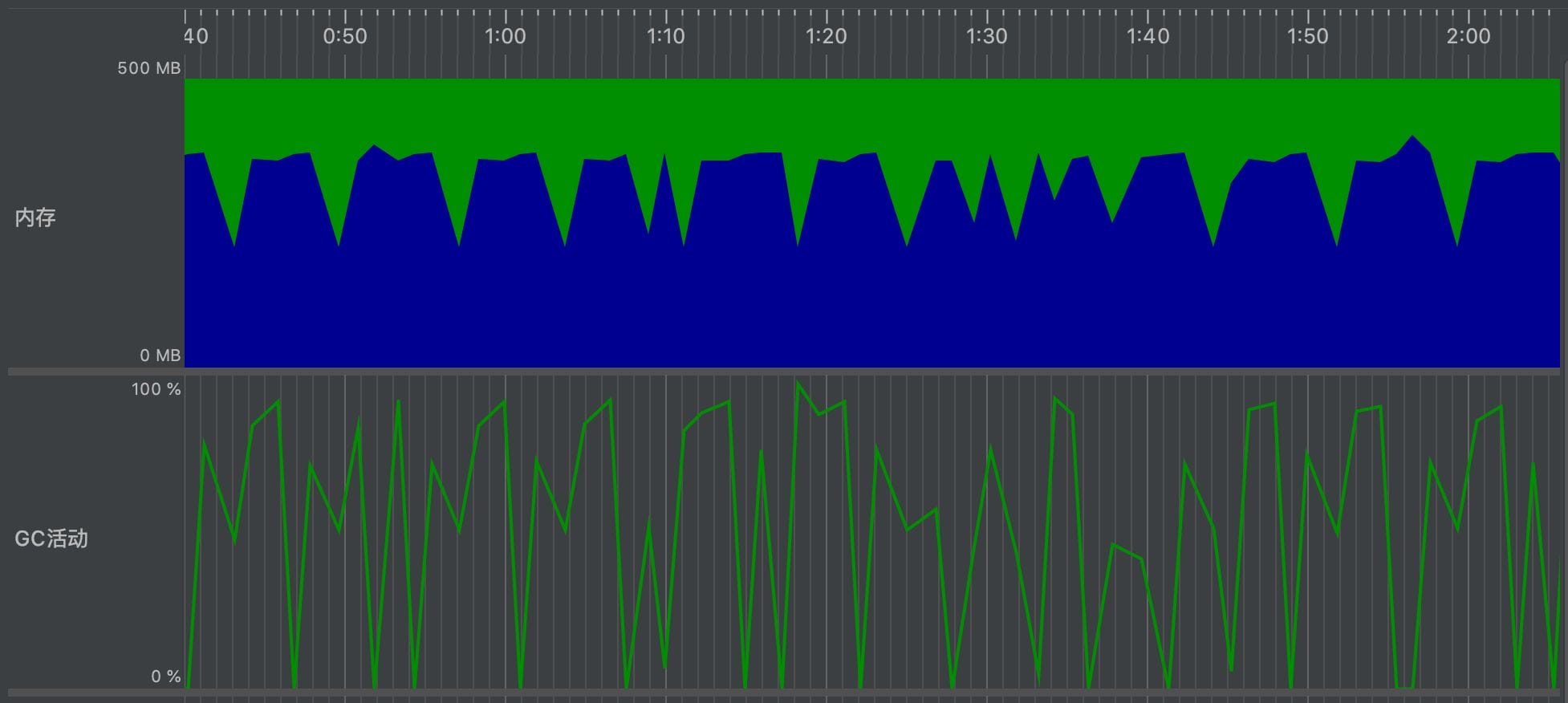
经过测试验证,mapPartitions + ArrayList.iterator()导致了两倍partitionSize的内存占用。
使用mapPartitions + ArrayList.iterator()仅仅只是造成OOM或GC压力大吗?偏偏不巧,在Spark的内存管理中另有一番天地,会牵扯到更多的性能问题。
Spark内存管理机制
Spark从2.0开始使用的是统一内存管理机制,主要分为四大区域,System Reserved、User Memory、Storage Memory和Execution Memory。System Reserved是为系统预留使用的内存,User Memory是用户定义的数据结构和Spark的元数据。存储内存Storage Memory与执行内存Execution Memory在运行期间会共享一块内存区域,默认有由spark.storage.storageFraction参数控制。Spark使用动态占用机制来管理这两块内存。
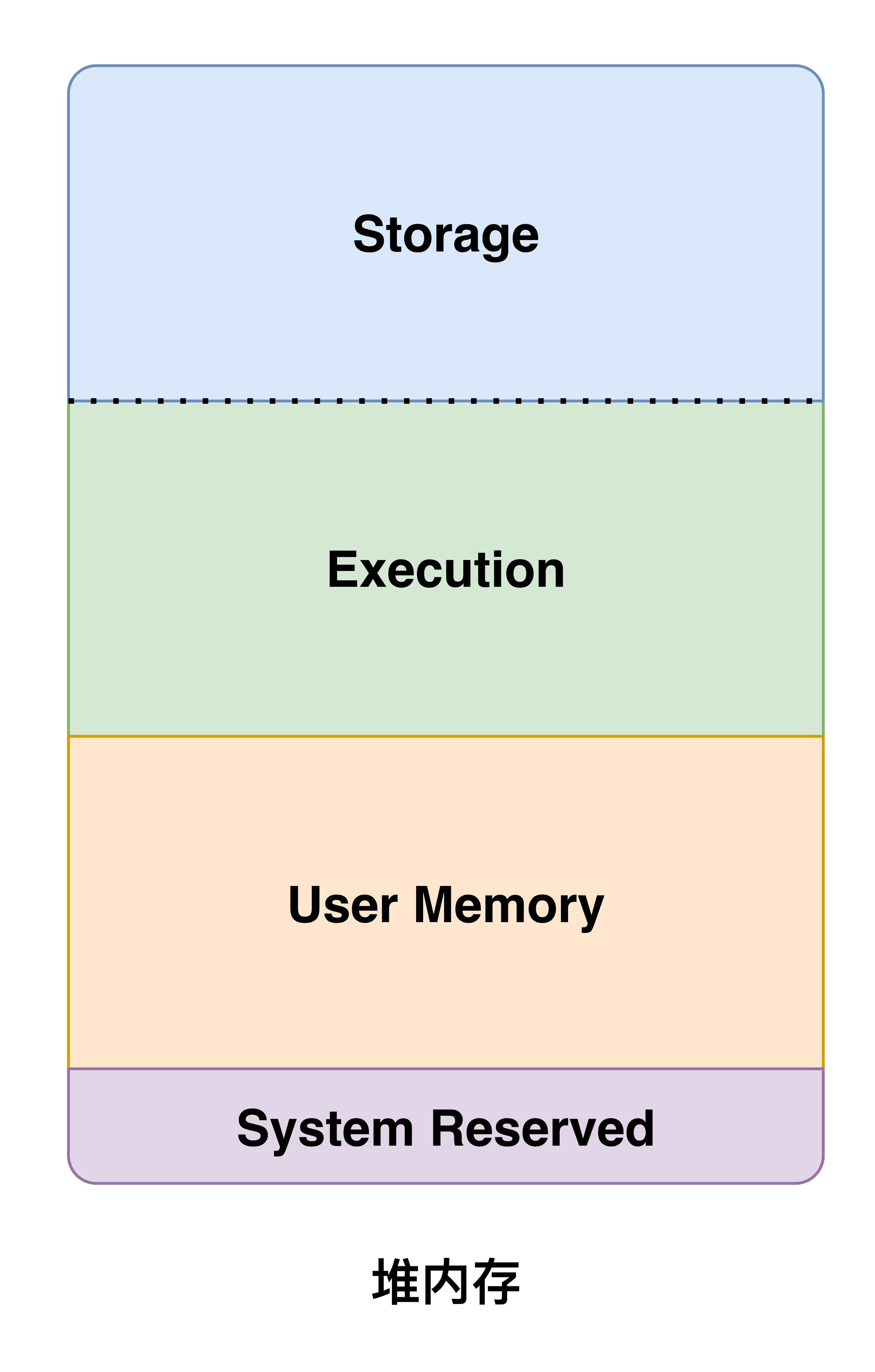
Storage和Execution的动态占用机制
- 当Storage或Execution的内存不足、而对方的内存空余时,可以占用对方的内存空间。
- Storage占用Execution时,如果Execution需要更多内存,则会将Storage占用的内存淘汰(根据RDD的StorageLevel决定是溢写到磁盘还是直接删除),归还借用的内存空间。
- Execution占用Storage时,如果Storage需要更多内存,则直接发生淘汰(Execution的逻辑复杂,归还内存的难度非常高)。
- 从Storage中淘汰掉的RDD Cache会在RDD重新使用时再次Cache。
在涉及到mapPartitions + ArrayList.iterator()的执行过程中,由于大量的内存占用,导致Execution Memory不足,借用Storage Memory,并且借用后仍存在内存不足情况时,Storage Memory中的已缓存的Block会进行淘汰机制,根据其存储级别进行落盘或直接删除,这会导致缓存数据多次的IO操作与重复计算,极大的降低了数据处理的效率。
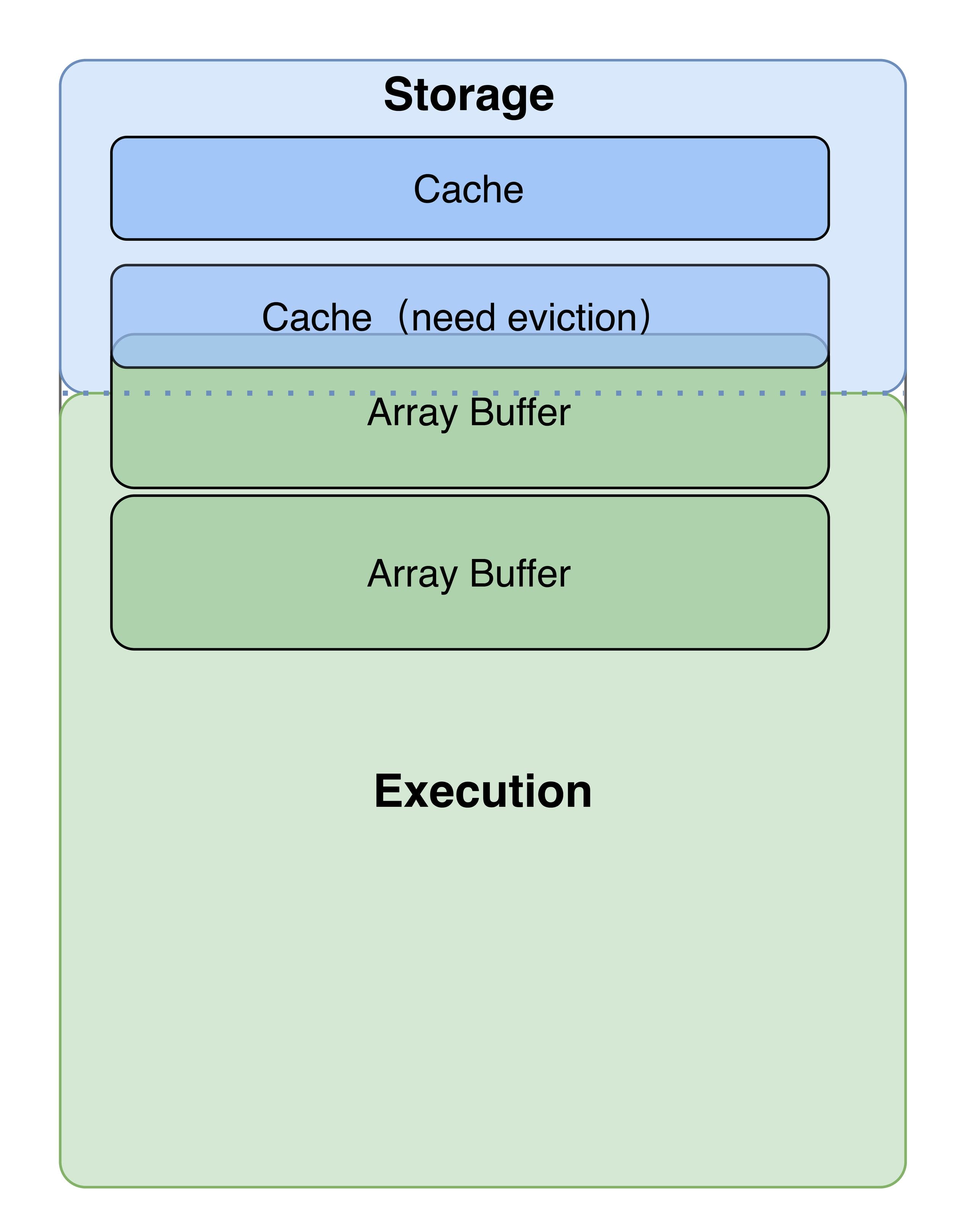
让我们小结一下mapPartitions + ArrayList.iterator()的实现方式:
- Spark通过mapPartitionsFunction嵌套实现Pipeline,例如fCount(funcC(funcB(funcA))),func中的Buffer是方法中的局部变量。
- 在mapPartitionsFunction中使用不限制长度的Buffer,会导致partitionSize两倍的数据拉入内存。
- 可能触发Spark内存管理的淘汰机制,导致缓存数据多次的IO操作与重复计算。
6. 最佳实践
以多输入多输出为例,假设我们需要处理一批单个分区数据量达到千万级别的数据集,以单个分区中每5行数据为一批次,每批次随机输出2行数据,那么在mapPartitions基础上,可以这样写:
BatchIteratorDemo:mapPartitions处理多输入->多输出——以单分区每5行数据为一批次,每批次随机输出2行数据的Demo
Dataset<Row> dataset = initDataset();// 初始化数据集
// mapPartitions中调用BatchIterator完成计算逻辑
Dataset<Row> result = dataset.mapPartitions((MapPartitionsFunction<Row, Row>) inputIterator -> new Iterator<Row>() {
// 一批处理的数据行数
private static final int INPUT_BATCH_PROCESS_SIZE = 5;
// 当前批次处理的数据集
private final List<Row> batchRows = new ArrayList<>(INPUT_BATCH_PROCESS_SIZE);
// 当前批次输出iterator
private Iterator<Row> batchResult = Collections.emptyIterator();
@Override
public boolean hasNext() {
// 本轮结果已全部消费,进入下一批次batch
if (!batchResult.hasNext()) {
batchRows.clear();
int count = 0;
// 按一个 batch 5条数据加入集合
while (count++ < INPUT_BATCH_PROCESS_SIZE && inputIterator.hasNext()) {
batchRows.add(inputIterator.next());
}
// 上游数据全部消费
if (batchRows.size() == 0) {
return false;
}
// 随机获取2条数据
batchResult = processBatch(batchRows);// 随机抽取2条数据创建新对象返回
}
return true;
}
@Override
public Row next() {
return batchResult.next();// 消费当前批次的结果
}
}, RowEncoder.apply(dataset.schema()));
当该方式应用到fCount(funcC(funcB(funcA(rddA.iterator=>iterator))))构成的Pipeline时,以多个mapPartitions + ArrayList.iterator()串联的代码展开则如下所示:
Example
iteratorA => iteratorB = // iteratorA:初始RDD对应Partition的输出迭代器
new Iterator[Row] {
override def hasNext: Boolean = {
processBatch(iteratorA) // 只处理一个batch的数据
}
override def next(): Row = nextInBatch() // 获取当前batch的下个输出
}
iteratorB => iteratorC = // iteratorB:rddA对应Partition的结果迭代器
new Iterator[Row] {
override def hasNext: Boolean = {
processBatch(iteratorB) // 只处理一个batch的数据
}
override def next(): Row = nextInBatch() // 获取当前batch的下个输出
}
iteratorC => iteratorD = // iteratorC:rddB对应Partition的结果迭代器
new Iterator[Row] {
override def hasNext: Boolean = {
processBatch(iteratorC) // 只处理一个batch的数据
}
override def next(): Row = nextInBatch() // 获取当前batch的下个输出
}
iteratorD => count()
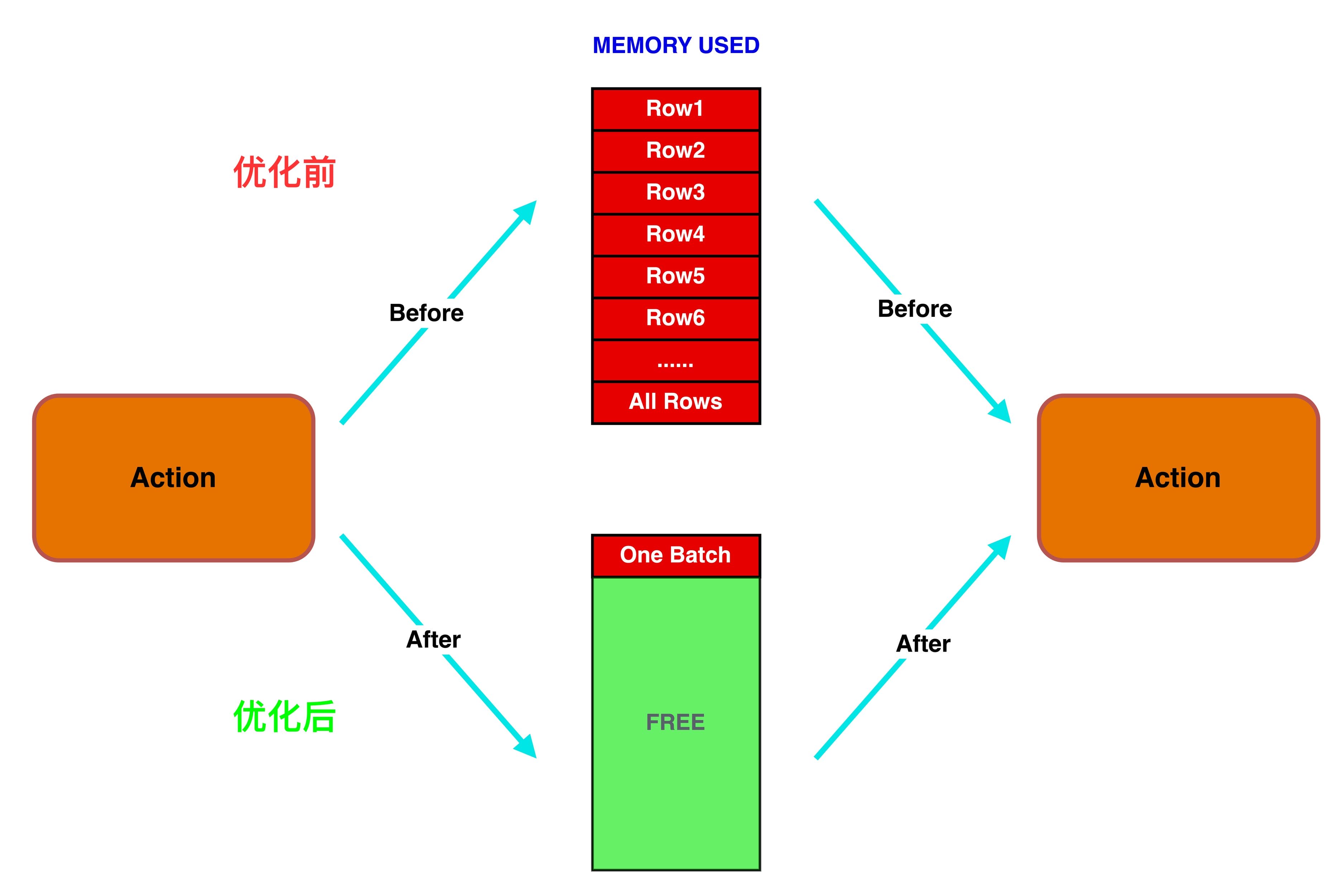
我们可以看到,多输入多输出Demo以inputBatch=5、outputBatch=2作为消费单位,内存占用只有Batch=7(inputBatch + outputBatch),每次处理完一个批次,直到当前批次产生的2条数据全部被下一个RDD Iterator消费完之后,才会继续尝试从上一个RDD Iterator读取下一个批次进入内存计算,不需要为了返回分区Iterator而直接消费整个分区数据。将随机抽取数据的逻辑串联处理,其Stage将如下图所示,每个Buffer仅为一个Batch,内存消耗几乎可以忽略不计。
最终的数据处理效果对比如下图:
7. 总结
本文作为《图灵机器学习平台性能起飞的秘密》系列的第一篇,主要讲述了内存优化中的算子优化技巧,深入分析了mapPartitions算子的原理,并提供了mapPartitions算子的最佳实践。图灵机器学习平台基于此方案进一步开发了BufferIterator框架,能够灵活应对输入M条数据输出N条数据的场景,极大提升了图灵的吞吐量。后续我们将继续为大家介绍更多的优化技巧,敬请期待。
文章来源
转载说明:
- 作者:琦帆、立煌、兆军等,均来自美团到家事业群/履约平台技术部。
- 版权声明:本文为「美团技术团队」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
- 原文链接:https://tech.meituan.com/2022/11/10/meituan-ai-turing-platform-spark-operator-optimization.html