Hadoop简介 - 起源,发展和版本等
什么是Hadoop
Apache™ Hadoop® 项目开发用于可靠、可扩展的分布式计算的开源软件。
Apache Hadoop 软件库是一个框架,允许使用简单的编程模型跨计算机集群分布式处理大型数据集。它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。该库本身旨在检测和处理应用层的故障,而不是依靠硬件来提供高可用性,因此可以在计算机集群之上提供高可用性服务,而每台计算机都可能容易出现故障。
Hadoop的起源和发展
Hadoop最早起源于lucene下的Nutch,并由Doug Cutting基于谷歌大数据解决方案的论文完成了相应的开源实现HDFS和MapReduce,并从Nutch中剥离成为独立项目Hadoop。
Hadoop最早起源于lucene下的Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
- 2003年、2004年谷歌发表的三篇论文为该问题提供了可行的解决方案。
- 分布式文件系统(GFS),可用于处理海量网页的存储。// HDFS
- 分布式计算框架MapReduce,可用于处理海量网页的索引计算问题。// MapReduce
- 分布式的结构化数据存储系统Bigtable,用来处理海量结构化数据。// HBase
Doug Cutting基于这三篇论文完成了相应的开源实现HDFS和MapReduce,并从Nutch中剥离成为独立项目Hadoop,到2008年1月,Hadoop成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
Hadoop的优点
Hadoop 是一个能够让用户轻松架构和使用的分布式计算的平台。用户可以轻松地在 Hadoop 发和运行处理海量数据的应用程序。其优点主要有以下几个:
(1) 高可靠性 :数据存储有多个备份,集群设置在不同机器上,可以防止一个节点宕机造成集群损坏。当数据处理请求失败后,Hadoop会自动重新部署计算任务。Hadoop框架中有备份机制和检验模式,Hadoop会对出现问题的部分进行修复,也可以通过设置快照的方式在集群出现问题时回到之前的一个时间点。
(2) 高扩展性 :Hadoop是在可用的计算机集群间分配数据并完成计算任务的,为集群添加新的节点并不复杂,所以集群可以很容易进行节点的扩展,扩大集群。
(3) 高效性 :Hadoop能够在节点之间动态地移动数据,在数据所在节点进行并发处理,并保证各个节点的动态平衡,因此处理速度非常快。
(4) 高容错性 :Hadoop的分布式文件系统HDFS在存储文件时会在多个节点或多台机器上存储文件的备份副本,当读取该文档出错或者某一台机器宕机了,系统会调用其他节点上的备份文件,保证程序顺利运行,如果启动的任务失败,Hadoop会重新运行该任务或启用其他任务来完成这个任务没有完成的部分。
(5) 低成本 :Hadoop 是开源的,既不需要支付任何费用即可下载并安装使用,节省了软件购买的成本。
(6) 构建在廉价机器上 :Hadoop不要求机器的配置达到极高的水准,大部分普通商用服务器就可以满足要求,它通过提供多个副本和容错机制来提高集群的可靠性。
Hadoop的版本变更
Hadoop目前的版本是3.x,从1.x到3.x有和变化呢?
Hadoop 1.x版本
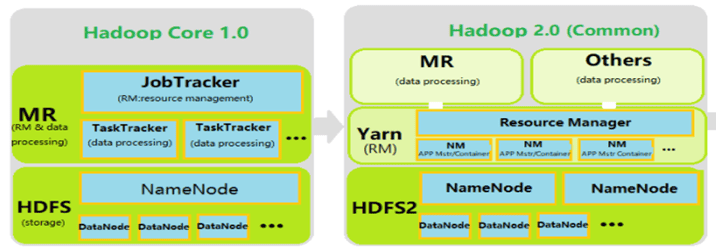
Hadoop 1.x为早期版本,核心组件为HDFS及MapReduce,MapReduce分管了资源及运算,并且在安全、日志及数据量上(元数据大小、可支持节点数)较为不足。
存在的问题
- HDFS单点故障
- 只有一个NameNode,所有元数据由唯一的NameNode负责管理。如果该NameNode失效,则任何与集群有关的历史操作都将失效,整个集群也就处于基本不可用状态。
- HDFS水平扩展性差
- 元数据存储在NameNode的内存中,因此集群规模受限于单个NameNode的内存大小
- MapReduce扩展性差、低可靠性、资源利用率低、无法执行非MapReduce任务无法支持多种计算框架
- 在MRv1中,JobTracker同时兼备了集群资源的管理和作业的调度与控制两大功能,使得JobTracker负载过重,增加了JobTracker失效的风险,造成Hadoop集群的扩展性差和低可靠性
- MRv1采用了基于槽位(slot)的资源分配模型,需要为map任务和reduce任务预先配置tasktracker槽位,当一个任务用不完槽位对应的所有资源其他任务也无法使用,而且为map任务保留的slot无法用于reduce任务,这造成资源利用率低
- MRv1中资源管理器JobTracker、TaskTracker耦合高,导致MRv1无法执行非MapReduce任务
Hadoop 2.x版本
Hadoop 2.x 重点解决了1.x中HDFS单点问题及水平扩展问题,以及将原有的资源调度从MapReduce中剥离为独立的Yarn。
HDFS
- Hadoop2.0增加了HDFS HA(高可用)机制,解决了HDFS 1.0中的单点故障问题,通过HA进行Standby NameNode的热备份。
- Hadoop2.0增加了HDFS Federation(联邦)水平扩展,支持多个NameNode同时运行,每一个NameNode分管一批目录,然后共享所有DataNode的存储资源,从而解决1.0当中单个NameNode节点内存受限问题。
MapReduce
在Hadoop2.0当中增加了YARN框架,针对hadoop1.0中主JobTracker压力太大的不足,把JobTracker资源分配和作业控制分开,利用Resource Manager在NameNode上进行资源管理调度,利用ApplicationMaster进行任务管理和任务监控。由NodeManager替代TaskTracker进行具体任务的执行,因此MapReduce2.0只是一个计算框架。对比hadoop1.0中相关资源的调用全部给Yarn框架管理。
Hadoop 3.x版本
Hadoop2.0之后版本就相对稳定,大部分实际生产环境中都使用的是2.0+。Hadoop3.0主要增加了一些性能上的优化和支持:
- java运行环境升级为1.8,对低版本的java不再支持
- HDFS3.0支持数据的擦除编码,调高存储空间的使用率
- 一些默认端口的改变
- 增加一些MapReduce的调优
Hadoop基础的模块
本系列研究的都是以3.x版本为主,该项目包括以下模块:
- Hadoop Common:支持其他 Hadoop 模块的通用实用程序。
- Hadoop 分布式文件系统 (HDFS™):一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。
- Hadoop YARN:作业调度和集群资源管理的框架。
- Hadoop MapReduce:一个基于 YARN 的系统,用于并行处理大型数据集。
Hadoop的发行版本
目前而言,不收费的Hadoop版本主要有三个(均是国外厂商),分别是:
- Apache版本(最原始的版本,所有发行版均基于这个版本进行改进)、
- Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称CDH)、
- Hortonworks版本(Hortonworks Data Platform,简称“HDP”)
(2018 年 Hortonworks已经被 Cloudera 公司收购)
Hortonworks Hadoop区别于其他的Hadoop发行版(如Cloudera)的根本就在于,Hortonworks的产品均是百分之百开源;Cloudera有免费版和企业版,企业版只有试用期;apache hadoop则是原生的hadoop。目前在中国流行的是apache hadoop,Cloudera CDH,当然Hortonworks也有用的。
Hortonworks这个名字源自儿童书中一只叫Horton的大象。众所周知,Hadoop的名字取自一只毛绒玩具象。类似的取名方式说明Hortonworks围绕Hadoop展开业务。2011年,雅虎剥离Hadoop业务,由Eric Bladeschweiler,雅虎主导Hadoop开发的副总裁,带领二十几个核心成员成立Hortonworks。成立伊始,Hortonworks即获雅虎和Benchmark 2300万美金投资,可谓含着金钥匙出生。此后Hortonworks一直受到资本市场追捧,IPO前一共获得五轮2.48亿美金的融资,并于2014年底登陆纳斯达克。
Hortonworks有两款核心产品:HDP和HDF,都是企业级数据管理平台。HDP的核心是YARN和HDFS,YARN是资源管理系统,可以使用户同时多种方式处理数据,而HDFS则提供高效、分布式、高容错的大数据存储。HDF是2015年推出的实时数据流管理平台,是对HDP的补充。
不同于传统软件提供商,Hortonworks没有对产品收费,而是将这两款产品完全开放,将核心技术放在Hadoop开源社区中,每个人都可以看到并使用这两款产品。开公司又不是做慈善,Hortonworks靠什么来赚钱?同redhat一样,采用订阅的方式收取服务费。
Hadoop演化出的项目
- 2010年5月— Avro脱离Hadoop项目,成为Apache顶级项目。
- 2010年5月— HBase脱离Hadoop项目,成为Apache顶级项目。
- 2010年9月— Hive( Facebook) 脱离Hadoop,成为Apache顶级项目。
- 2010年9月— Pig脱离Hadoop,成为Apache顶级项目。
- 2011年1月— ZooKeeper 脱离Hadoop,成为Apache顶级项目。