ES详解 - 聚合:聚合查询之Pipline聚合详解
前文主要讲了 ElasticSearch提供的三种聚合方式之指标聚合(Metric Aggregation),本文主要讲讲管道聚合(Pipeline Aggregation)。简单而言就是让上一步的聚合结果成为下一个聚合的输入,这就是管道。@pdai
如何理解pipeline聚合
如何理解管道聚合呢?最重要的是要站在设计者角度看这个功能的要实现的目的:让上一步的聚合结果成为下一个聚合的输入,这就是管道。
管道机制的常见场景
首先回顾下,我们之前在Tomcat管道机制中向你介绍的常见的管道机制设计中的应用场景。
责任链模式
管道机制在设计模式上属于责任链模式,如果你不理解,请参看如下文章:
责任链模式(Chain of responsibility pattern): 通过责任链模式, 你可以为某个请求创建一个对象链. 每个对象依序检查此请求并对其进行处理或者将它传给链中的下一个对象。
FilterChain
在软件开发的常接触的责任链模式是FilterChain,它体现在很多软件设计中:
- 比如Spring Security框架中
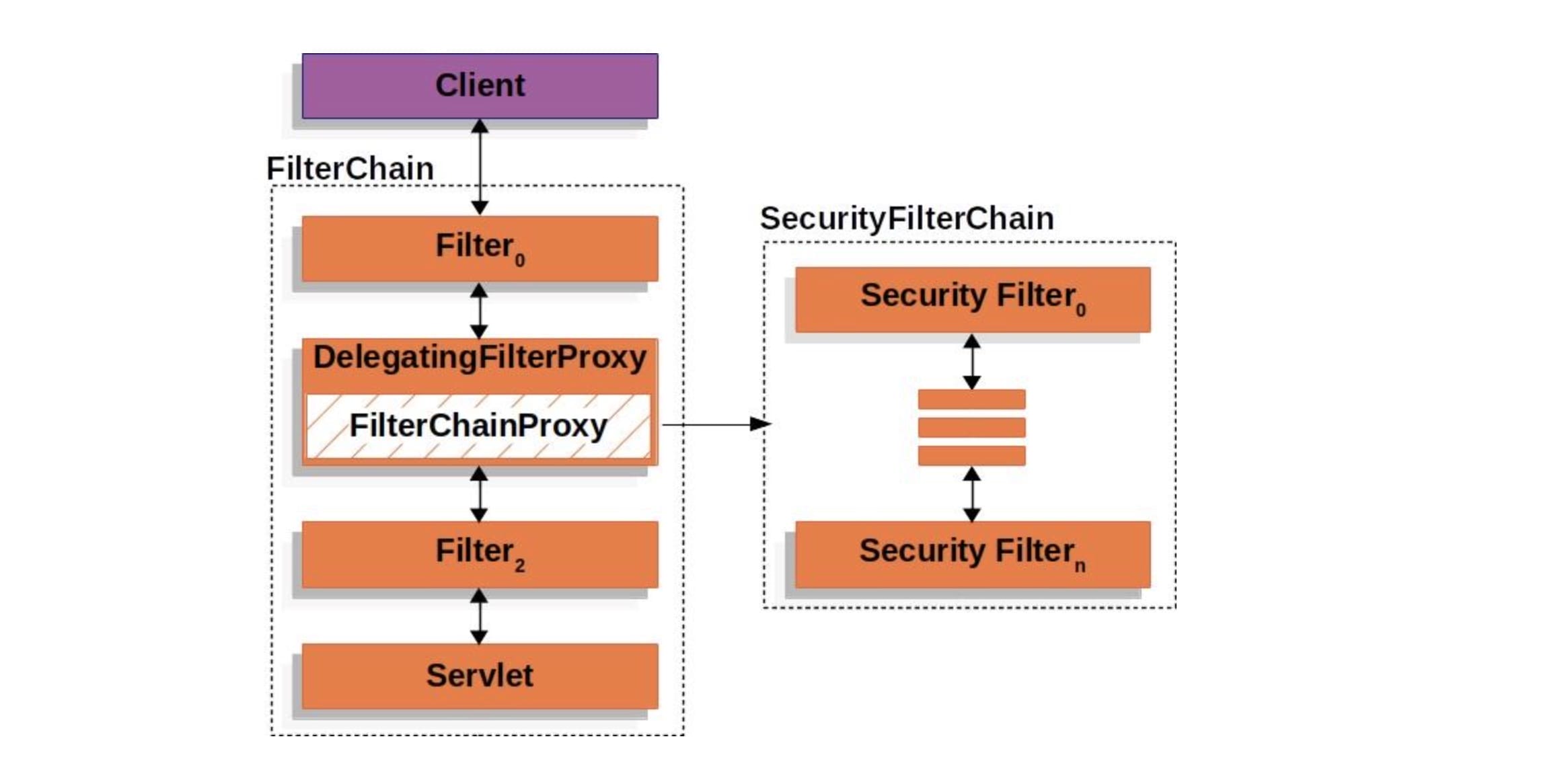
- 比如HttpServletRequest处理的过滤器中
当一个request过来的时候,需要对这个request做一系列的加工,使用责任链模式可以使每个加工组件化,减少耦合。也可以使用在当一个request过来的时候,需要找到合适的加工方式。当一个加工方式不适合这个request的时候,传递到下一个加工方法,该加工方式再尝试对request加工。
网上找了图,这里我们后文将通过Tomcat请求处理向你阐述。

ElasticSearch设计管道机制
简单而言:让上一步的聚合结果成为下一个聚合的输入,这就是管道。
接下来,无非就是对不同类型的聚合有接口的支撑,比如:
第一个维度:管道聚合有很多不同类型,每种类型都与其他聚合计算不同的信息,但是可以将这些类型分为两类:
- 父级 父级聚合的输出提供了一组管道聚合,它可以计算新的存储桶或新的聚合以添加到现有存储桶中。
- 兄弟 同级聚合的输出提供的管道聚合,并且能够计算与该同级聚合处于同一级别的新聚合。
第二个维度:根据功能设计的意图
比如前置聚合可能是Bucket聚合,后置的可能是基于Metric聚合,那么它就可以成为一类管道
进而引出了:xxx bucket(是不是很容易理解了 @pdai)
- Bucket聚合 -> Metric聚合: bucket聚合的结果,成为下一步metric聚合的输入
- Average bucket
- Min bucket
- Max bucket
- Sum bucket
- Stats bucket
- Extended stats bucket
对构建体系而言,理解上面的已经够了,其它的类型不过是锦上添花而言。
一些例子
这里我们通过几个简单的例子看看即可,具体如果需要使用看看文档即可。@pdai
Average bucket 聚合
POST _search
{
"size": 0,
"aggs": {
"sales_per_month": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"avg_monthly_sales": {
// tag::avg-bucket-agg-syntax[]
"avg_bucket": {
"buckets_path": "sales_per_month>sales",
"gap_policy": "skip",
"format": "#,##0.00;(#,##0.00)"
}
// end::avg-bucket-agg-syntax[]
}
}
}
- 嵌套的bucket聚合:聚合出按月价格的直方图
- Metic聚合:对上面的聚合再求平均值。
字段类型:
- buckets_path:指定聚合的名称,支持多级嵌套聚合。
- gap_policy 当管道聚合遇到不存在的值,有点类似于term等聚合的(missing)时所采取的策略,可选择值为:skip、insert_zeros。
- skip:此选项将丢失的数据视为bucket不存在。它将跳过桶并使用下一个可用值继续计算。
- format 用于格式化聚合桶的输出(key)。
输出结果如下
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
}
}
]
},
"avg_monthly_sales": {
"value": 328.33333333333333,
"value_as_string": "328.33"
}
}
}
Stats bucket 聚合
进一步的stat bucket也很容易理解了
POST /sales/_search
{
"size": 0,
"aggs": {
"sales_per_month": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"stats_monthly_sales": {
"stats_bucket": {
"buckets_path": "sales_per_month>sales"
}
}
}
}
返回
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
}
}
]
},
"stats_monthly_sales": {
"count": 3,
"min": 60.0,
"max": 550.0,
"avg": 328.3333333333333,
"sum": 985.0
}
}
}
参考文章
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-pipeline.html