Redis进阶 - 运维监控:Redis的监控详解
Redis实战中包含开发,集群 和 运维,Redis用的好不好,如何让它更好,这是运维要做的;本文主要在 Redis自身状态及命令,可视化监控工具,以及Redis监控体系等方面帮助你构建对redis运维/监控体系的认知,它是性能优化的前提。@pdai
如何理解Redis监控呢
Redis运维和监控的意义不言而喻,我认为主要从如下三方面去构建认知体系:
首先是Redis自身提供了哪些状态信息,以及有哪些常见的命令可以获取Redis的监控信息;
其次需要知道一些常见的UI工具可以可视化的监控Redis;
最后需要理解Redis的监控体系;
Redis自身状态及命令
如果只是想简单看一下Redis的负载情况的话,完全可以用它提供的一些命令来完成。
状态信息 - info
Redis提供的INFO命令不仅能够查看实时的吞吐量(ops/sec),还能看到一些有用的运行时信息。
- info查看所有状态信息
[root@redis_test_vm ~]# redis-cli -h 127.0.0.1
127.0.0.1:6379> auth xxxxx
OK
127.0.0.1:6379> info
# Server
redis_version:3.2.3 #redis版本号
redis_git_sha1:00000000 #git sha1摘要值
redis_git_dirty:0 #git dirty标识
redis_build_id:443e50c39cbcdbe0 #redis构建id
redis_mode:standalone #运行模式:standalone、sentinel、cluster
os:Linux 3.10.0-514.16.1.el7.x86_64 x86_64 #服务器宿主机操作系统
arch_bits:64 服务器宿主机CUP架构(32位/64位)
multiplexing_api:epoll #redis IO机制
gcc_version:4.8.5 #编译 redis 时所使用的 GCC 版本
process_id:1508 #服务器进程的 PID
run_id:b4ac0f9086659ce54d87e41d4d2f947e19c28401 #redis 服务器的随机标识符 (用于 Sentinel 和集群)
tcp_port:6380 #redis服务监听端口
uptime_in_seconds:520162 #redis服务启动以来经过的秒数
uptime_in_days:6 #redis服务启动以来经过的天数
hz:10 #redis内部调度(进行关闭timeout的客户端,删除过期key等等)频率,程序规定serverCron每秒运行10次
lru_clock:16109450 #自增的时钟,用于LRU管理,该时钟100ms(hz=10,因此每1000ms/10=100ms执行一次定时任务)更新一次
executable:/usr/local/bin/redis-server
config_file:/data/redis-6380/redis.conf 配置文件的路径
# Clients
connected_clients:2 #已连接客户端的数量(不包括通过从属服务器连接的客户端)
client_longest_output_list:0 #当前连接的客户端当中,最长的输出列表
client_biggest_input_buf:0 #当前连接的客户端当中,最大输入缓存
blocked_clients:0 #正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
# Memory
used_memory:426679232 #由 redis 分配器分配的内存总量,以字节(byte)为单位
used_memory_human:406.91M #以可读的格式返回 redis 分配的内存总量(实际是used_memory的格式化)
used_memory_rss:443179008 #从操作系统的角度,返回 redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps等命令的输出一致
used_memory_rss_human:422.65M # redis 的内存消耗峰值(以字节为单位)
used_memory_peak:426708912
used_memory_peak_human:406.94M
total_system_memory:16658403328
total_system_memory_human:15.51G
used_memory_lua:37888 # Lua脚本存储占用的内存
used_memory_lua_human:37.00K
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
mem_fragmentation_ratio:1.04 # used_memory_rss/ used_memory
mem_allocator:jemalloc-4.0.3
# Persistence
loading:0 #服务器是否正在载入持久化文件,0表示没有,1表示正在加载
rdb_changes_since_last_save:3164272 #离最近一次成功生成rdb文件,写入命令的个数,即有多少个写入命令没有持久化
rdb_bgsave_in_progress:0 #服务器是否正在创建rdb文件,0表示否
rdb_last_save_time:1559093160 #离最近一次成功创建rdb文件的时间戳。当前时间戳 - rdb_last_save_time=多少秒未成功生成rdb文件
rdb_last_bgsave_status:ok #最近一次rdb持久化是否成功
rdb_last_bgsave_time_sec:-1 #最近一次成功生成rdb文件耗时秒数
rdb_current_bgsave_time_sec:-1 #如果服务器正在创建rdb文件,那么这个域记录的就是当前的创建操作已经耗费的秒数
aof_enabled:0 #是否开启了aof
aof_rewrite_in_progress:0 #标识aof的rewrite操作是否在进行中
aof_rewrite_scheduled:0 #rewrite任务计划,当客户端发送bgrewriteaof指令,如果当前rewrite子进程正在执行,那么将客户端请求的bgrewriteaof变为计划任务,待aof子进程结束后执行rewrite
aof_last_rewrite_time_sec:-1 #最近一次aof rewrite耗费的时长
aof_current_rewrite_time_sec:-1 #如果rewrite操作正在进行,则记录所使用的时间,单位秒
aof_last_bgrewrite_status:ok #上次bgrewriteaof操作的状态
aof_last_write_status:ok #上次aof写入状态
# Stats
total_connections_received:10 #服务器已经接受的连接请求数量
total_commands_processed:9510792 #redis处理的命令数
instantaneous_ops_per_sec:1 #redis当前的qps,redis内部较实时的每秒执行的命令数
total_net_input_bytes:1104411373 #redis网络入口流量字节数
total_net_output_bytes:66358938 #redis网络出口流量字节数
instantaneous_input_kbps:0.04 #redis网络入口kps
instantaneous_output_kbps:3633.35 #redis网络出口kps
rejected_connections:0 #拒绝的连接个数,redis连接个数达到maxclients限制,拒绝新连接的个数
sync_full:0 #主从完全同步成功次数
sync_partial_ok:0 #主从部分同步成功次数
sync_partial_err:0 #主从部分同步失败次数
expired_keys:0 #运行以来过期的key的数量
evicted_keys:0 #运行以来剔除(超过了maxmemory后)的key的数量
keyspace_hits:87 #命中次数
keyspace_misses:17 #没命中次数
pubsub_channels:0 #当前使用中的频道数量
pubsub_patterns:0 #当前使用的模式的数量
latest_fork_usec:0 #最近一次fork操作阻塞redis进程的耗时数,单位微秒
migrate_cached_sockets:0 #是否已经缓存了到该地址的连接
# Replication
role:master #实例的角色,是master or slave
connected_slaves:0 #连接的slave实例个数
master_repl_offset:0 #主从同步偏移量,此值如果和上面的offset相同说明主从一致没延迟,与master_replid可被用来标识主实例复制流中的位置
repl_backlog_active:0 #复制积压缓冲区是否开启
repl_backlog_size:1048576 #复制积压缓冲大小
repl_backlog_first_byte_offset:0 #复制缓冲区里偏移量的大小
repl_backlog_histlen:0 #此值等于 master_repl_offset - repl_backlog_first_byte_offset,该值不会超过repl_backlog_size的大小
# CPU
used_cpu_sys:507.00 #将所有redis主进程在核心态所占用的CPU时求和累计起来
used_cpu_user:280.48 #将所有redis主进程在用户态所占用的CPU时求和累计起来
used_cpu_sys_children:0.00 #将后台进程在核心态所占用的CPU时求和累计起来
used_cpu_user_children:0.00 #将后台进程在用户态所占用的CPU时求和累计起来
# Cluster
cluster_enabled:0
# Keyspace
db0:keys=5557407,expires=362,avg_ttl=604780497
db15:keys=1,expires=0,avg_ttl=0
- 查看某个section的信息
127.0.0.1:6379> info memory
# Memory
used_memory:1067440
used_memory_human:1.02M
used_memory_rss:9945088
used_memory_rss_human:9.48M
used_memory_peak:1662736
used_memory_peak_human:1.59M
total_system_memory:10314981376
total_system_memory_human:9.61G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
mem_fragmentation_ratio:9.32
mem_allocator:jemalloc-4.0.3
监控执行命令 - monitor
monitor用来监视服务端收到的命令。
127.0.0.1:6379> monitor
OK
1616045629.853032 [10 192.168.0.101:37990] "PING"
1616045629.858214 [10 192.168.0.101:37990] "PING"
1616045632.193252 [10 192.168.0.101:37990] "EXISTS" "test_key_from_app"
1616045632.193607 [10 192.168.0.101:37990] "GET" "test_key_from_app"
1616045632.200572 [10 192.168.0.101:37990] "SET" "test_key_from_app" "1616045625017"
1616045632.200973 [10 192.168.0.101:37990] "SET" "test_key_from_app" "1616045622621"
监控延迟
- 监控延迟 - latency
[root@redis_test_vm ~]# redis-cli --latency -h 127.0.0.1
min: 0, max: 1, avg: 0.21
如果我们故意用DEBUG命令制造延迟,就能看到一些输出上的变化:
[root@redis_test_vm ~]# redis-cli -h 127.0.0.1
127.0.0.1:6379> debug sleep 2
OK
(2.00s)
127.0.0.1:6379> debug sleep 3
OK
(3.00s)
观测延迟
[root@redis_test_vm ~]# redis-cli --latency -h 127.0.0.1
min: 0, max: 1995, avg: 1.60 (492 samples)
- 客户端监控 - ping
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> ping
PONG
同时monitor
127.0.0.1:6379> monitor
OK
1616045629.853032 [10 192.168.0.101:37990] "PING"
1616045629.858214 [10 192.168.0.101:37990] "PING"
- 服务端 - 内部机制
服务端内部的延迟监控稍微麻烦一些,因为延迟记录的默认阈值是0。尽管空间和时间耗费很小,Redis为了高性能还是默认关闭了它。所以首先我们要开启它,设置一个合理的阈值,例如下面命令中设置的100ms:
127.0.0.1:6379> CONFIG SET latency-monitor-threshold 100
OK
因为Redis执行命令非常快,所以我们用DEBUG命令人为制造一些慢执行命令:
127.0.0.1:6379> debug sleep 2
OK
(2.00s)
127.0.0.1:6379> debug sleep .15
OK
127.0.0.1:6379> debug sleep .5
OK
下面就用LATENCY的各种子命令来查看延迟记录:
LATEST:四列分别表示事件名、最近延迟的Unix时间戳、最近的延迟、最大延迟。HISTORY:延迟的时间序列。可用来产生图形化显示或报表。GRAPH:以图形化的方式显示。最下面以竖行显示的是指延迟在多久以前发生。RESET:清除延迟记录。
127.0.0.1:6379> latency latest
1) 1) "command"
1) (integer) 1616058778
2) (integer) 500
3) (integer) 2000
127.0.0.1:6379> latency history command
1) 1) (integer) 1616058773
2) (integer) 2000
2) 1) (integer) 1616058776
2) (integer) 150
3) 1) (integer) 1616058778
2) (integer) 500
127.0.0.1:6379> latency graph command
command - high 2000 ms, low 150 ms (all time high 2000 ms)
--------------------------------------------------------------------------------
#
|
|
|_#
666
mmm
在执行一条DEBUG命令会发现GRAPH图的变化,多出一条新的柱状线,下面的时间2s就是指延迟刚发生两秒钟:
127.0.0.1:6379> debug sleep 1.5
OK
(1.50s)
127.0.0.1:6379> latency graph command
command - high 2000 ms, low 150 ms (all time high 2000 ms)
--------------------------------------------------------------------------------
#
| #
| |
|_#|
2222
333s
mmm
还有一个子命令DOCTOR,它能列出一些指导建议,例如开启慢日志进一步追查问题原因,查看是否有大对象被踢出或过期,以及操作系统的配置建议等。
127.0.0.1:6379> latency doctor
Dave, I have observed latency spikes in this Redis instance. You don't mind talking about it, do you Dave?
1. command: 3 latency spikes (average 883ms, mean deviation 744ms, period 210.00 sec). Worst all time event 2000ms.
I have a few advices for you:
- Check your Slow Log to understand what are the commands you are running which are too slow to execute. Please check http://redis.io/commands/slowlog for more information.
- Deleting, expiring or evicting (because of maxmemory policy) large objects is a blocking operation. If you have very large objects that are often deleted, expired, or evicted, try to fragment those objects into multiple smaller objects.
- I detected a non zero amount of anonymous huge pages used by your process. This creates very serious latency events in different conditions, especially when Redis is persisting on disk. To disable THP support use the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled', make sure to also add it into /etc/rc.local so that the command will be executed again after a reboot. Note that even if you have already disabled THP, you still need to restart the Redis process to get rid of the huge pages already created.
如果你沒有配置 CONFIG SET latency-monitor-threshold <milliseconds>., 会返回如下信息
127.0.0.1:6379> latency doctor
I'm sorry, Dave, I can't do that. Latency monitoring is disabled in this Redis instance. You may use "CONFIG SET latency-monitor-threshold <milliseconds>." in order to enable it. If we weren't in a deep space mission I'd suggest to take a look at http://redis.io/topics/latency-monitor.
- 度量延迟Baseline - intrinsic-latency
延迟中的一部分是来自环境的,比如操作系统内核、虚拟化环境等等。Redis提供了让我们度量这一部分延迟基线(Baseline)的方法:
[root@redis_test_vm ~]# redis-cli --intrinsic-latency 100 -h 127.0.0.1
Could not connect to Redis at 127.0.0.1:6379: Connection refused
Max latency so far: 1 microseconds.
Max latency so far: 62 microseconds.
Max latency so far: 69 microseconds.
Max latency so far: 72 microseconds.
Max latency so far: 102 microseconds.
Max latency so far: 438 microseconds.
Max latency so far: 5169 microseconds.
Max latency so far: 9923 microseconds.
1435096059 total runs (avg latency: 0.0697 microseconds / 69.68 nanoseconds per run).
Worst run took 142405x longer than the average latency.
–intrinsic-latency后面是测试的时长(秒),一般100秒足够了。
Redis可视化监控工具
在谈Redis可视化监控工具时,要分清工具到底是仅仅指标的可视化,还是可以融入监控体系(比如包含可视化,监控,报警等; 这是生产环境长期监控生态的基础)
- 只能可视化指标不能监控:
redis-stat、RedisLive、redmon等工具 - 用于生产环境: 基于
redis_exporter以及grafana可以做到指标可视化,持久化,监控以及报警等
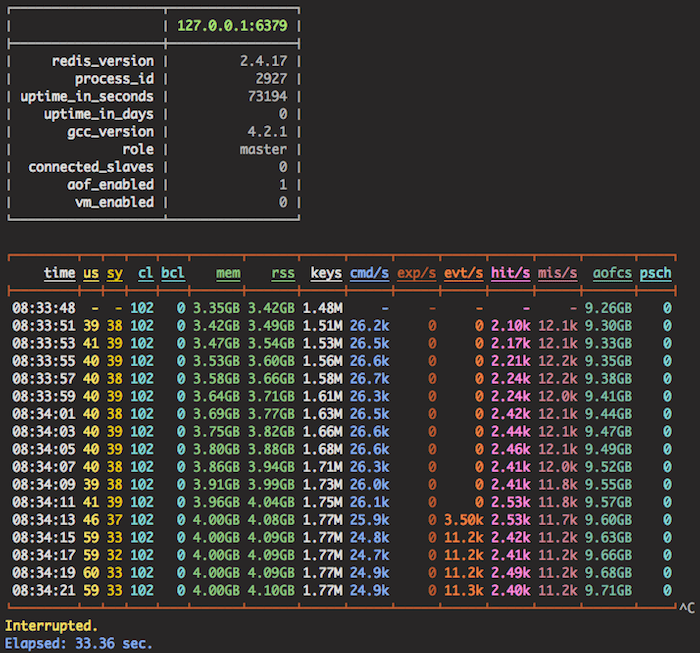
redis-stat
redis-stat是一个比较有名的redis指标可视化的监控工具,采用ruby开发,基于redis的info和monitor命令来统计,不影响redis性能。
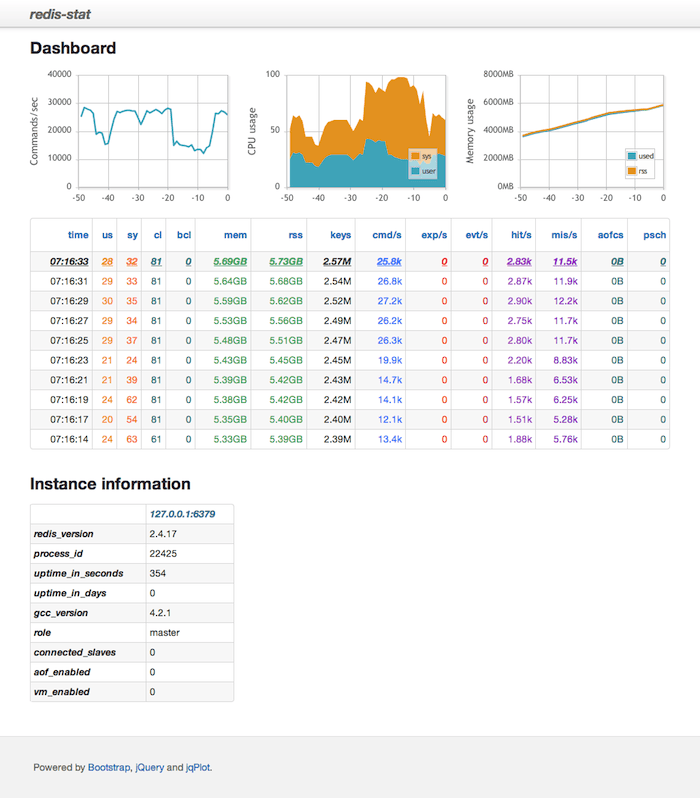
它提供了命令行彩色控制台展示模式
和web模式
RedisLive
RedisLive是采用python开发的redis的可视化及查询分析工具
docker运行
docker run --name redis-live -p 8888:8888 -d snakeliwei/redislive
运行实例图
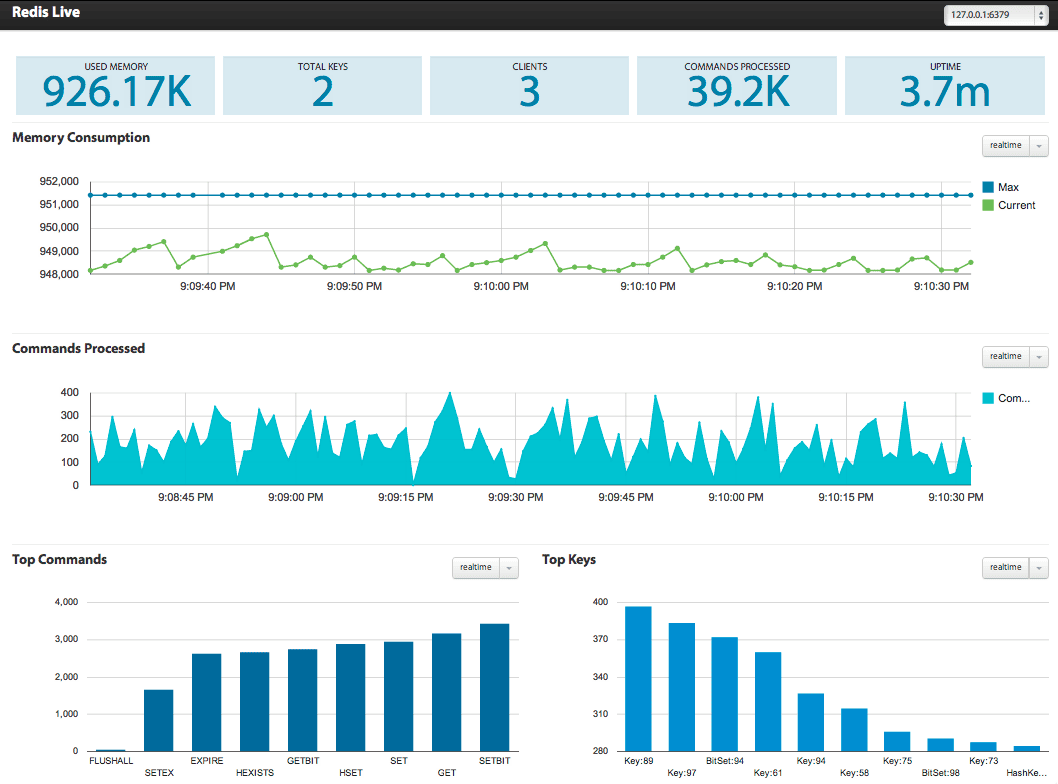
访问http://192.168.99.100:8888/index.html
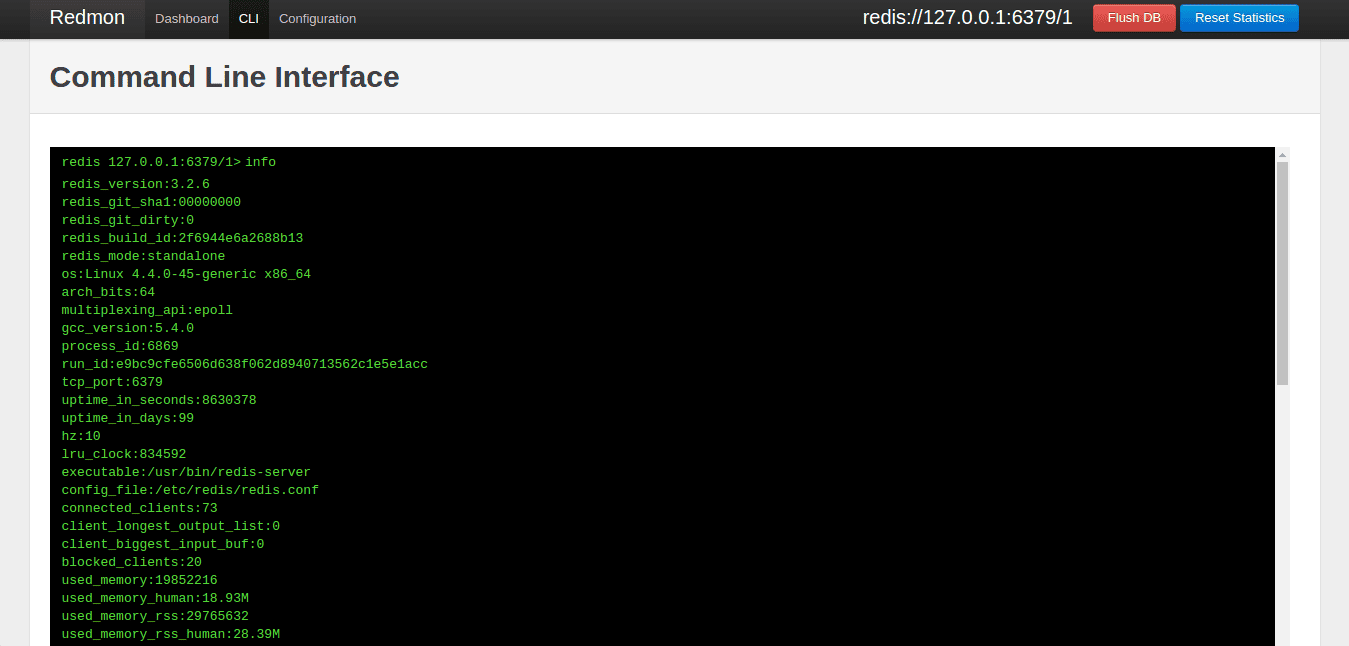
redmon
redmon提供了cli、admin的web界面,同时也能够实时监控redis
docker运行
docker run -p 4567:4567 -d vieux/redmon -r redis://192.168.99.100:6379
监控

cli
动态更新配置
redis_exporter
redis_exporter为Prometheus提供了redis指标的exporter,支持Redis 2.x, 3.x, 4.x, 5.x, and 6.x,配合Prometheus以及grafana的Prometheus Redis插件,可以在grafana进行可视化及监控
运行实例图
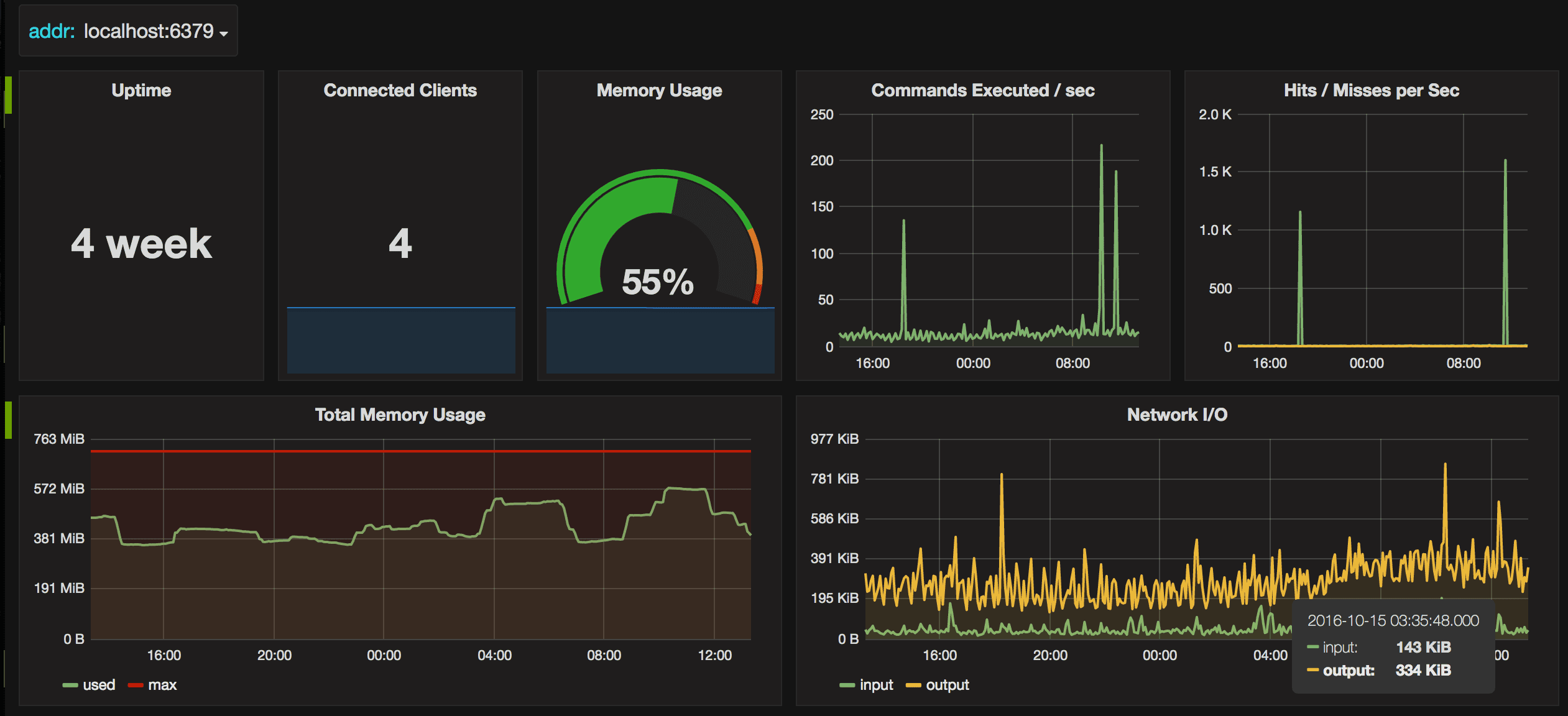
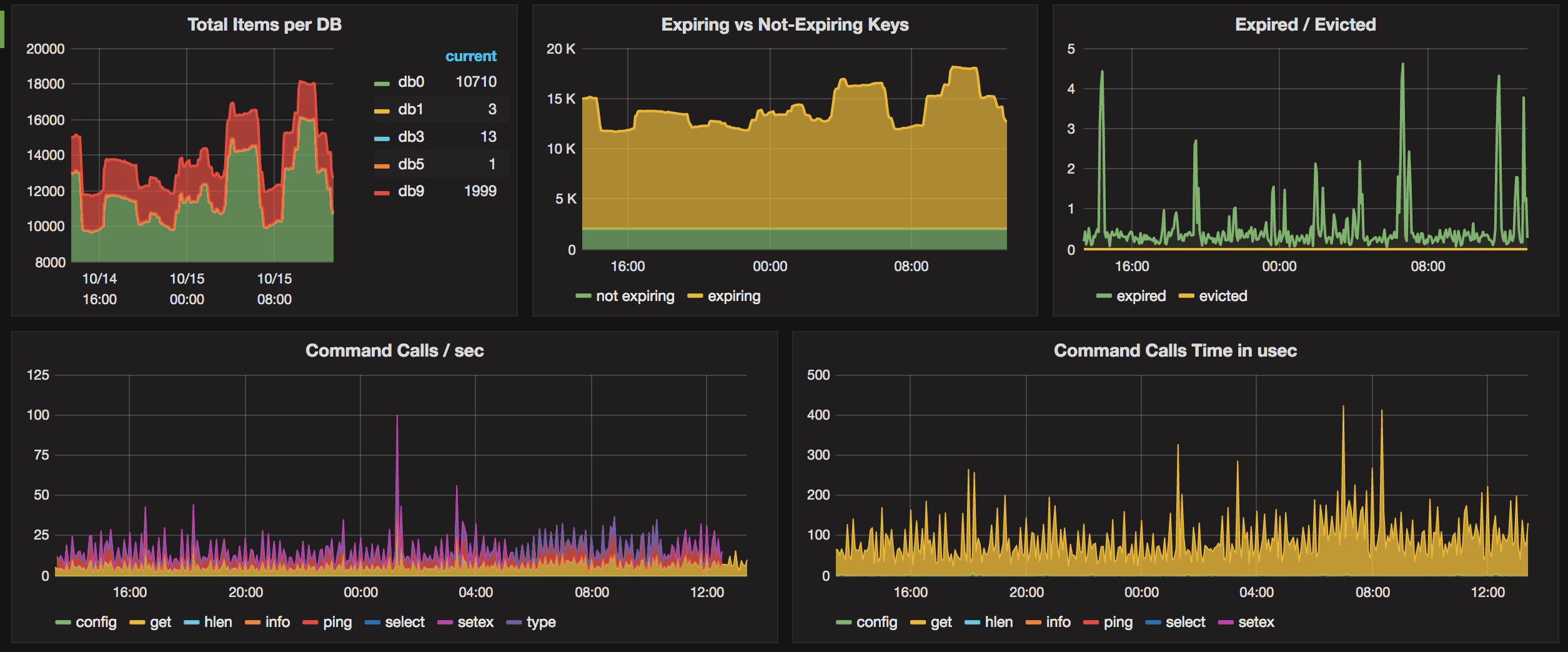
Redis监控体系
那么上面我们谈到的监控体系到底应该考虑什么? redis这类敏感的纯内存、高并发和低延时的服务,一套完善的监控告警方案,是精细化运营的前提。
我们从以下几个角度来理解:
- 什么样的场景会谈到redis监控体系?
- 构建Redis监控体系具备什么价值?
- 监控体系化包含哪些维度?
- 具体的监控指标有哪些呢?
- 有哪些成熟的监控方案呢?
什么样的场景会谈到redis监控体系?
一个大型系统引入了Redis作为缓存中间件,具体描述如下:
- 部署架构采用Redis-Cluster模式;
- 后台应用系统有几十个,应用实例数超过二百个;
- 所有应用系统共用一套缓存集群;
- 集群节点数几十个,加上容灾备用环境,节点数量翻倍;
- 集群节点内存配置较高。

问题描述
系统刚开始关于Redis的一切都很正常,随着应用系统接入越来越多,应用系统子模块接入也越来越多,开始出现一些问题,应用系统有感知,集群服务端也有感知,如下描述:
- 集群节点崩溃;
- 集群节点假死;
- 某些后端应用访问集群响应特别慢。
其实问题的根源都是架构运维层面的欠缺,对于Redis集群服务端的运行监控其实很好做,上文也介绍了很多直接的命令方式,但只能看到服务端的一些常用指标信息,无法深入分析,治标不治本,对于Redis的内部运行一无所知,特别是对于业务应用如何使用Redis集群一无所知:
- Redis集群使用的热度问题?
- 哪些应用占用的Redis内存资源多?
- 哪些应用占用Redis访问数最高?
- 哪些应用使用Redis类型不合理?
- 应用系统模块使用Redis资源分布怎么样?
- 应用使用Redis集群的热点问题?
构建Redis监控体系具备什么价值?
Redis监控告警的价值对每个角色都不同,重要的几个方面:
- redis故障快速通知,定位故障点;
- 分析redis故障的Root cause
- redis容量规划和性能管理
- redis硬件资源利用率和成本
redis故障快速发现,定位故障点和解决故障
当redis出现故障时,运维人员应在尽可能短时间内发现告警;如果故障对服务是有损的(如大面积网络故障或程序BUG),需立即通知SRE和RD启用故障预案(如切换机房或启用emergency switch)止损。
如果没完善监控告警; 假设由RD发现服务故障,再排查整体服务调用链去定位;甚于用户发现用问题,通过客服投诉,再排查到redis故障的问题;整个redis故障的发现、定位和解决时间被拉长,把一个原本的小故障被”无限”放大。
分析redis故障的Root cause
任何一个故障和性能问题,其根本“诱因”往往只有一个,称为这个故障的Root cause。
一个故障从DBA发现、止损、分析定位、解决和以后规避措施;最重要一环就是DBA通过各种问题表象,层层分析到Root cause;找到问题的根据原因,才能根治这类问题,避免再次发生。
完善的redis监控数据,是我们分析root cause的基础和证据。
问题表现是综合情的,一般可能性较复杂,这里举2个例子:
- 服务调用Redis响应时间变大的性能总是;可能网络问题,redis慢查询,redis QPS增高达到性能瓶颈,redis fork阻塞和请求排队,redis使用swap, cpu达到饱和(单核idle过低),aof fsync阻塞,网络进出口资源饱和等等
- redis使用内存突然增长,快达到maxmemory; 可能其个大键写入,键个数增长,某类键平均长度突增,fork COW, 客户端输入/输出缓冲区,lua程序占用等等
Root cause是要直观的监控数据和证据,而非有技术支撑的推理分析。
- redis响应抖动,分析定位root casue是bgsave时fork导致阻塞200ms的例子。而不是分析推理:redis进程rss达30gb,响应抖动时应该有同步,fork子进程时,页表拷贝时要阻塞父进程,估计页表大小xx,再根据内存copy连续1m数据要xx 纳秒,分析出可能fork阻塞导致的。(要的不是这种分析)
Redis容量规划和性能管理
通过分析redis资源使用和性能指标的监控历史趋势数据;对集群进行合理扩容(Scale-out)、缩容(Scale-back);对性能瓶颈优化处理等。
Redis资源使用饱和度监控,设置合理阀值;
一些常用容量指标:redis内存使用比例,swap使用,cpu单核的饱和度等;当资源使用容量预警时,能及时扩容,避免因资源使用过载,导致故障。
另一方面,如果资源利用率持续过低,及时通知业务,并进行redis集群缩容处理,避免资源浪费。
进一步,容器化管理redis后,根据监控数据,系统能自动地弹性扩容和缩容。
Redis性能监控管理,及时发现性能瓶颈,进行优化或扩容,把问题扼杀在”萌芽期“,避免它”进化“成故障。
Redis硬件资源利用率和成本
从老板角度来看,最关心的是成本和资源利用率是否达标。
如果资源不达标,就得推进资源优化整合;提高硬件利用率,减少资源浪费。砍预算,减成本。
资源利用率是否达标的数据,都是通过监控系统采集的数据。
监控体系化包含哪些维度?
监控的目的不仅仅是监控Redis本身,而是为了更好的使用Redis。传统的监控一般比较单一化,没有系统化,但对于Redis来说,个人认为至少包括:一是服务端,二是应用端,三是服务端与应用端联合分析。
服务端
服务端首先是操作系统层面,常用的CPU、内存、网络IO,磁盘IO,服务端运行的进程信息等;
Redis运行进程信息,包括服务端运行信息、客户端连接数、内存消耗、持久化信息 、键值数量、主从同步、命令统计、集群信息等;
Redis运行日志,日志中会记录一些重要的操作进程,如运行持久化时,可以有效帮助分析崩溃假死的程序。
应用端
应用端、获取应用端使用Redis的一些行为,具体哪些应用哪些模块最占用 Redis资源、哪些应用哪些模块最消耗Redis资源、哪些应用哪些模块用法有误等。
联合分析
联合分析结合服务端的运行与应用端使用的行为,如:一些造成服务端突然阻塞的原因,可能是应用端设置了一个很大的缓存键值,或者使用的键值列表,数据量超大造成阻塞。
具体的监控指标有哪些呢?
redis监控的数据采集,数据采集1分钟一次,分为下面几个方面:
- 服务器系统数据采集
- Redis Server数据采集
- Redis响应时间数据采集
- Redis监控Screen
服务器系统监控数据采集
服务器系统的数据采集,这部分包含数百个指标. 采集方式现在监控平台自带的agent都会支持
我们从redis使用资源的特性,分析各个子系统的重要监控指标。
- 服务器存活监控
- ping监控告警
- CPU
- 平均负载 (Load Average): 综合负载指标(暂且归类cpu子系统),当系统的子系统出现过度使用时,平均负载会升高。可说明redis的处理性能下降(平均响应时间变长、吞吐量降低)。
- CPU整体利用率或饱和度 (cpu.busy): redis在高并发或时间复杂度高的指令,cpu整体资源饱和,导致redis性能下降,请求堆积。
- CPU单核饱和度 (cpu.core.idle/core=0): redis是单进程模式,常规情况只使用一个cpu core, 单某个实例出现cpu性能瓶颈,导致性能故障,但系统一般24线程的cpu饱和度却很低。所以监控cpu单核心利用率也同样重样。
- CPU上下文切换数 (cpu.switches):context swith过高xxxxxx
- 内存和swap
- 系统内存余量大小 (mem.memfree):redis是纯内存系统,系统内存必须保有足够余量,避免出现OOM,导致redis进程被杀,或使用swap导致redis性能骤降。
- 系统swap使用量大小 (mem.swapused):redis的”热数据“只要进入swap,redis处理性能就会骤降; 不管swap分区的是否是SSD介质。OS对swap的使用材质还是disk store. 这也是作者早期redis实现VM,后来又放弃的原因。
- 磁盘
- 磁盘分区的使用率 (df.bytes.used.percent):磁盘空间使用率监控告警,确保有足磁盘空间用AOF/RDB, 日志文件存储。不过 redis服务器一般很少出现磁盘容量问题
- 磁盘IOPS的饱和度(disk.io.util):如果有AOF持久化时,要注意这类情况。如果AOF持久化,每秒sync有堆积,可能导致写入stall的情况。 另外磁盘顺序吞吐量还是很重要,太低会导致复制同步RDB时,拉长同步RDB时间。(期待diskless replication)
- 网络
- 网络吞吐量饱和度(net.if.out.bytes/net.if.in.bytes):如果服务器是千兆网卡(Speed: 1000Mb/s),单机多实例情况,有异常的大key容量导致网卡流量打滿。redis整体服务等量下降,苦于出现故障切换。
- 丢包率 :Redis服务响应质量受影响
Redis Server监控数据采集
通过redis实例的状态数据采集,采集监控数据的命令
ping,info all, slowlog get/len/reset/cluster info/config get
- Redis存活监控
- redis存活监控 (redis_alive):redis本地监控agent使用ping,如果指定时间返回PONG表示存活,否则redis不能响应请求,可能阻塞或死亡。
- redis uptime监控 (redis_uptime):uptime_in_seconds
- Redis 连接数监控
- 连接个数 (connected_clients):客户端连接个数,如果连接数过高,影响redis吞吐量。常规建议不要超过5000.
- 连接数使用率(connected_clients_pct): 连接数使用百分比,通过(connected_clients/macclients)计算;如果达到1,redis开始拒绝新连接创建。
- 拒绝的连接个数(rejected_connections): redis连接个数达到maxclients限制,拒绝新连接的个数。
- 新创建连接个数 (total_connections_received): 如果新创建连接过多,过度地创建和销毁连接对性能有影响,说明短连接严重或连接池使用有问题,需调研代码的连接设置。
- list阻塞调用被阻塞的连接个数 (blocked_clients): BLPOP这类命令没使用过,如果监控数据大于0,还是建议排查原因。
- Redis内存监控
- redis分配的内存大小 (used_memory): redis真实使用内存,不包含内存碎片;单实例的内存大小不建议过大,常规10~20GB以内。
- redis内存使用比例(used_memory_pct): 已分配内存的百分比,通过(used_memory/maxmemory)计算;对于redis存储场景会比较关注,未设置淘汰策略(maxmemory_policy)的,达到maxmemory限制不能写入数据。
- redis进程使用内存大小(used_memory_rss): 进程实际使用的物理内存大小,包含内存碎片;如果rss过大导致内部碎片大,内存资源浪费,和fork的耗时和cow内存都会增大。
- redis内存碎片率 (mem_fragmentation_ratio): 表示(used_memory_rss/used_memory),碎片率过大,导致内存资源浪费;
Redis综合性能监控
- Redis Keyspace: redis键空间的状态监控
- 键个数 (keys): redis实例包含的键个数。建议控制在1kw内;单实例键个数过大,可能导致过期键的回收不及时。
- 设置有生存时间的键个数 (keys_expires): 是纯缓存或业务的过期长,都建议对键设置TTL; 避免业务的死键问题. (expires字段)
- 估算设置生存时间键的平均寿命 (avg_ttl): redis会抽样估算实例中设置TTL键的平均时长,单位毫秒。如果无TTL键或在Slave则avg_ttl一直为0
- LRU淘汰的键个数 (evicted_keys): 因used_memory达到maxmemory限制,并设置有淘汰策略的实例;(对排查问题重要,可不设置告警)
- 过期淘汰的键个数 (expired_keys): 删除生存时间为0的键个数;包含主动删除和定期删除的个数。
- Redis qps
- redis处理的命令数 (total_commands_processed): 监控采集周期内的平均qps,
- redis单实例处理达数万,如果请求数过多,redis过载导致请求堆积。
- redis当前的qps (instantaneous_ops_per_sec): redis内部较实时的每秒执行的命令数;可和total_commands_processed监控互补。
- Redis cmdstat_xxx
- 通过info all的Commandstats节采集数据.
- 每类命令执行的次数 (cmdstat_xxx): 这个值用于分析redis抖动变化比较有用
- 以下表示:每个命令执行次数,总共消耗的CPU时长(单个微秒),平均每次消耗的CPU时长(单位微秒)
# Commandstats
cmdstat_set:calls=6,usec=37,usec_per_call=6.17
cmdstat_lpush:calls=4,usec=32,usec_per_call=8.00
cmdstat_lpop:calls=4,usec=33,usec_per_call=8.25
- Redis Keysapce hit ratio
redis键空间请求命中率监控,通过此监控来度量redis缓存的质量,如果未命中率或次数较高,可能因热点数据已大于redis的内存限制,导致请求落到后端存储组件,可能需要扩容redis缓存集群的内存容量。当然也有可能是业务特性导致。
请求键被命中次数 (keyspace_hits): redis请求键被命中的次数
请求键未被命中次数 (keyspace_misses): redis请求键未被命中的次数;当命中率较高如95%,如果请求量大,未命中次数也会很多。
请求键的命中率 (keyspace_hit_ratio):使用keyspace_hits/(keyspace_hits+keyspace_misses)计算所得,是度量Redis缓存服务质量的标准
Redis fork
redis在执行BGSAVE,BGREWRITEAOF命令时,redis进程有 fork 操作。而fork会对redis进程有个短暂的卡顿,这个卡顿redis不能响应任务请求。所以监控fork阻塞时长,是相当重要。
如果你的系统不能接受redis有500ms的阻塞,那么就要监控fork阻塞时长的变化,做好容量规划。
最近一次fork阻塞的微秒数 (latest_fork_usec): 最近一次Fork操作阻塞redis进程的耗时数,单位微秒。 redis network traffic redis一般单机多实例部署,当服务器网络流量增长很大,需快速定位是网络流量被哪个redis实例所消耗了; 另外redis如果写流量过大,可能导致slave线程“客户端输出缓冲区”堆积,达到限制后被Maser强制断开连接,出现复制中断故障。所以我们需监控每个redis实例网络进出口流量,设置合适的告警值。
说明:网络监控指标 ,需较高的版本才有,应该是2.8.2x以后
- redis网络入口流量字节数 (total_net_input_bytes)
- redis网络出口流量字节数 (total_net_output_bytes)
- redis网络入口kps (instantaneous_input_kbps)
- redis网络出口kps (instantaneous_output_kbps)
前两者是累计值,根据监控平台1个采集周期(如1分钟)内平均每秒的流量字节数。
Redis慢查询监控
redis慢查询 是排查性能问题关键监控指标。因redis是单线程模型(single-threaded server),即一次只能执行一个命令,如果命令耗时较长,其他命令就会被阻塞,进入队列排队等待;这样对程序性能会较大。
redis慢查询保存在内存中,最多保存slowlog-max-len(默认128)个慢查询命令,当慢查询命令日志达到128个时,新慢查询被加入前,会删除最旧的慢查询命令。因慢查询不能持久化保存,且不能实时监控每秒产生的慢查询个数。
我们建议的慢查询监控方法:
- 设置合理慢查询日志阀值,slowlog-log-slower-than, 建议1ms(如果平均1ms, redis qps也就只有1000) 设+ 置全理慢查询日志队列长度,slowlog-max-len建议大于1024个,因监控采集周期1分钟,建议,避免慢查询日志被删除;另外慢查询的参数过多时,会被省略,对内存消耗很小
- 每次采集使用slowlog len获取慢查询日志个数
- 每次彩集使用slowlog get 1024 获取所慢查询,并转存储到其他地方,如MongoDB或MySQL等,方便排查问题;并分析当前慢查询日志最长耗时微秒数。
- 然后使用slowlog reset把慢查询日志清空,下个采集周期的日志长度就是最新产生的。
redis慢查询的监控项:
- redis慢查询日志个数 (slowlog_len):每个采集周期出现慢查询个数,如1分钟出现10次大于1ms的慢查询
- redis慢查询日志最长耗时值 (slowlog_max_time):获取慢查询耗时最长值,因有的达10秒以下的慢查询,可能导致复制中断,甚至出来主从切换等故障。
Redis持久化监控
redis存储场景的集群,就得 redis持久化 保障数据落地,减少故障时数据丢失。这里分析redis rdb数据持久化的几个监控指标。
- 最近一次rdb持久化是否成功 (rdb_last_bgsave_status):如果持久化未成功,建议告警,说明备份或主从复制同步不正常。或redis设置有”stop-writes-on-bgsave-error”为yes,当save失败后,会导致redis不能写入操作
- 最近一次成功生成rdb文件耗时秒数 (rdb_last_bgsave_time_sec):rdb生成耗时反应同步时数据是否增长; 如果远程备份使用redis-cli –rdb方式远程备份rdb文件,时间长短可能影响备份线程客户端输出缓冲内存使用大小。
- 离最近一次成功生成rdb文件,写入命令的个数 (rdb_changes_since_last_save):即有多少个写入命令没有持久化,最坏情况下会丢失的写入命令数。建议设置监控告警
- 离最近一次成功rdb持久化的秒数 (rdb_last_save_time): 最坏情况丢失多少秒的数据写入。使用当前时间戳 - 采集的rdb_last_save_time(最近一次rdb成功持久化的时间戳),计算出多少秒未成功生成rdb文件
Redis复制监控
不论使用何种redis集群方案, redis复制 都会被使用。
复制相关的监控告警项:
- redis角色 (redis_role):实例的角色,是master or slave
- 复制连接状态 (master_link_status): slave端可查看它与master之间同步状态;当复制断开后表示down,影响当前集群的可用性。需设置监控告警。
- 复制连接断开时间长度 (master_link_down_since_seconds):主从服务器同步断开的秒数,建议设置时长告警。
- 主库多少秒未发送数据到从库 (master_last_io_seconds):如果主库超过repl-timeout秒未向从库发送命令和数据,会导致复制断开重连。 在slave端可监控,建议设置大于10秒告警
- 从库多少秒未向主库发送REPLCONF命令 (slave_lag): 正常情况从库每秒都向主库,发送REPLCONF ACK命令;如果从库因某种原因,未向主库上报命令,主从复制有中断的风险。通过在master端监控每个slave的lag值。
- 从库是否设置只读 (slave_read_only):从库默认只读禁止写入操作,监控从库只读状态;如果关闭从库只读,有写入数据风险。
- 主库挂载的从库个数 (connected_slaves):主库至少保证一个从库,不建议设置超过2个从库。
- 复制积压缓冲区是否开启 (repl_backlog_active):主库默认开启复制积压缓冲区,用于应对短时间复制中断时,使用 部分同步 方式。
- 复制积压缓冲大小 (repl_backlog_size):主库复制积压缓冲大小默认1MB,因为是redis server共享一个缓冲区,建议设置100MB.
说明: 关于根据实际情况,设置合适大小的复制缓冲区。可以通过master_repl_offset指标计算每秒写入字节数,同时乘以希望多少秒内闪断使用“部分同步”方式。
Redis集群监控
这里所写 redis官方集群方案 的监控指标
数据基本通过cluster info和info命令采集。
- 实例是否启用集群模式 (cluster_enabled): 通过info的cluster_enabled监控是否启用集群模式。
- 集群健康状态 (clusster_state):如果当前redis发现有failed的slots,默认为把自己cluster_state从ok个性为fail, 写入命令会失败。如果设置cluster-require-full-coverage为NO,则无此限制。
- 集群数据槽slots分配情况 (cluster_slots_assigned):集群正常运行时,默认16384个slots
- 检测下线的数据槽slots个数 (cluster_slots_fail):集群正常运行时,应该为0. 如果大于0说明集群有slot存在故障。
- 集群的分片数 (cluster_size):集群中设置的分片个数
- 集群的节点数 (cluster_known_nodes):集群中redis节点的个数
Redis响应时间监控
响应时间 是衡量一个服务组件性能和质量的重要指标。使用redis的服务通常对响应时间都十分敏感,比如要求99%的响应时间达10ms以内。
因redis的慢查询日志只计算命令的cpu占用时间,不会考虑排队或其他耗时。
- 最长响应时间 (respond_time_max):最长响应时间的毫秒数
- 99%的响应时间长度 (respond_time_99_max):
- 99%的平均响应时间长度 (respond_time_99_avg):
- 95%的响应时间长度 (respond_time_95_max):
- 95%的平均响应时间长度 (respond_time_95_avg):
常用哪些成熟方案呢?
无论哪种,要体系化,必然要考虑如下几点。@pdai
- 指标采集,即采集redis提供的metric指标,所以方案中有时候会出现Agent,比如metricBeat;
- 监控的数据持久化,只有将监控数据放到数据库,才能对比和长期监控;
- 时序化,因为很多场景都会按照时间序列去展示 - 所以通常是用时序库或者针对时间列优化;
- 可视化,比如常见的kibana,grafana等
- 按条件报警,因为运维不可能盯着看,只有引入报警配置,触发报警条件时即发出报警,比如短息提醒等;基于不同报警方式,平台可以提供插件支持等;
ELK Stack
经典的ELK
- 采集agent: metricBeat
- 收集管道:logstash
- DB: elasticSearch
- view和告警: kibana及插件
fluent + Prometheus + Grafana
推荐使用这种
- 采集指标来源: redis-export
- 收集管道:fluentd
- DB: Prometheus
- view和告警: Grafana及插件
参考文章
- https://blog.csdn.net/dc_726/article/details/47699739
- https://www.jianshu.com/p/831bf6c8af4f
- https://my.oschina.net/guol/blog/182265
- https://blog.csdn.net/qq_27623337/article/details/53206685