Mongo进阶 - MongoDB体系结构
上面章节已经对MongoDB生态中工具以及使用有了基础,后续文章我们将开始理解MongoDB是如何支撑这些功能的。我们将从最基本的MongoDB的体系结构开始介绍,主要包括
MongoDB的包结构,MongoDB的数据逻辑结构,MongoDB的数据文件结构。其中围绕着MongoDB的数据文件结构,将为我们后续介绍MongoDB的存储引擎详解打下基础。@pdai
MongoDB包组件结构
主要是MongoDB数据库服务以及一些工具。
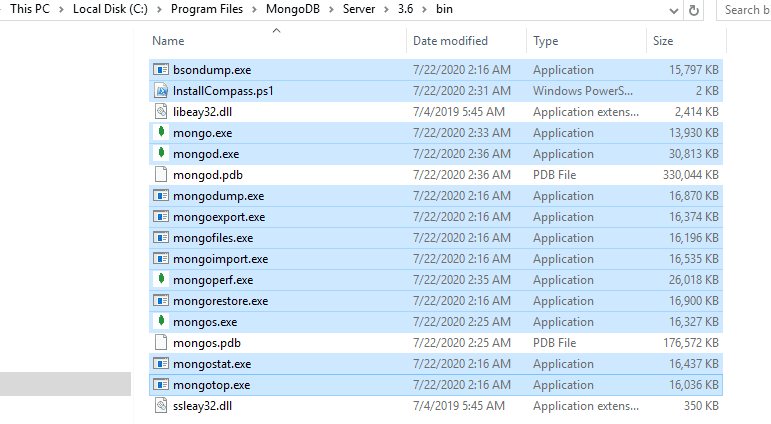
回顾下我们在MongoDB生态中展示的MongoDB Database Tools
- 二进制导入导出
mongodumpCreates a binary export of the contents of a mongod database.mongorestoreRestores data from a mongodump database dump into a mongod or mongosbsondumpConverts BSON dump files into JSON.
- 数据导入导出
mongoimportImports content from an Extended JSON, CSV, or TSV export file.mongoexportProduces a JSON or CSV export of data stored in a mongod instance.
- 诊断工具
mongostatProvides a quick overview of the status of a currently running mongod or mongos instance.mongotopProvides an overview of the time a mongod instance spends reading and writing data.
- GridFS 工具
mongofilesSupports manipulating files stored in your MongoDB instance in GridFS objects.
除了上述没有列举到,还有:
mongoperf: mongoDB自带工具,用于评估磁盘随机IO性能。
包组件可以在官网MongoDB Package Components找到详细的用法。
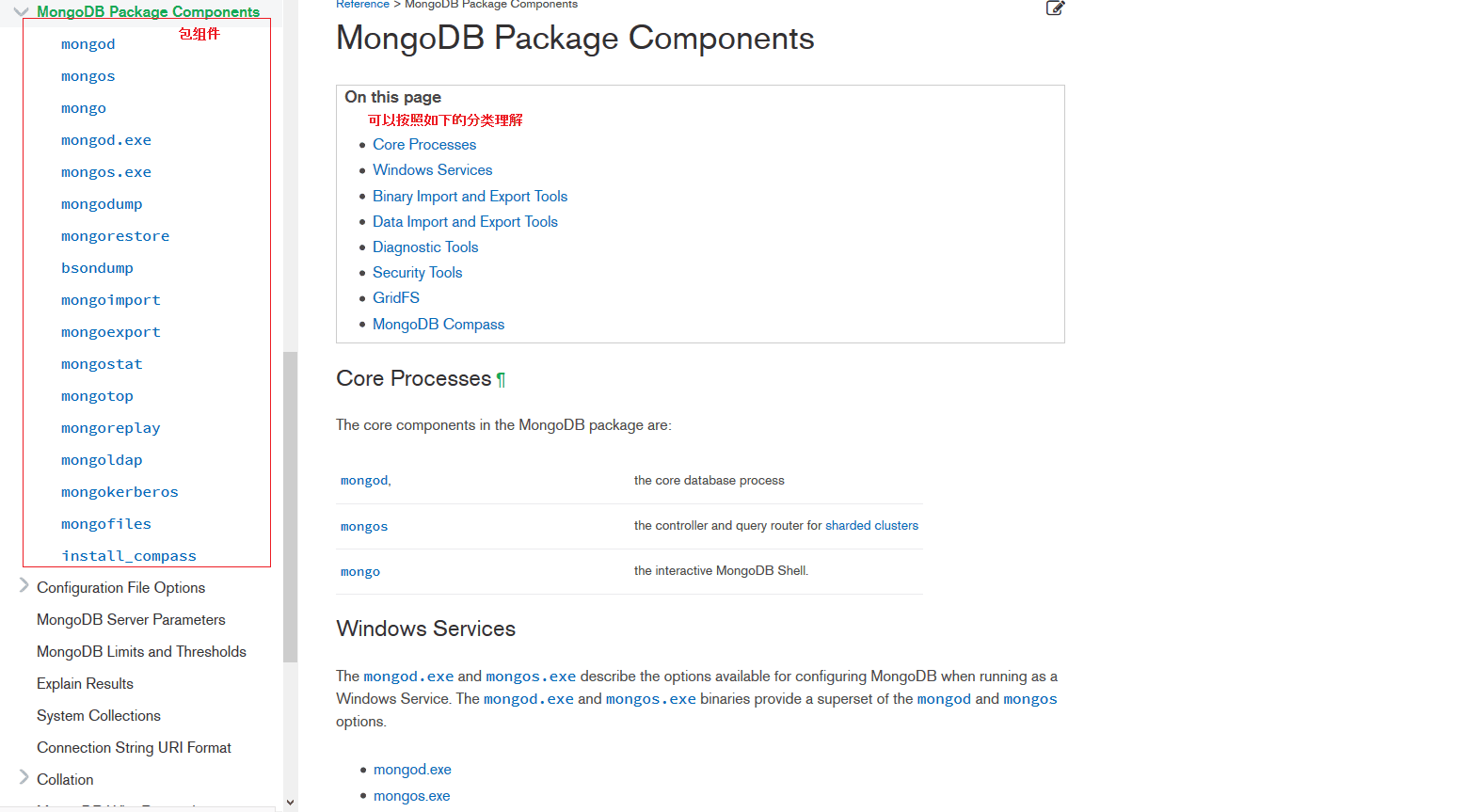
其中最主要的程序当然是mongod(数据库服务),mongod在不同的部署方案中(单机部署,副本集部署,分片集群部署),通过不同的配置,可以扮演多种不同的角色:
- 在单机部署中扮演 数据库服务器(提供所有读写功能)
- 在副本集部署中,通过配置,可以部署为 primary节点(主服务器,负责写数据,也可以提供查询)、secondary节点(从服务器,它从主节点复制数据,也可以提供查询)、以及arbiter节点(仲裁节点,不保存数据,主要用于参与选举投票)
- 在分片集群中,除了在每个分片中扮演上述角色外,还扮演着配置服务器的角色(存储有分片集群的所有元数据信息,mongos的数据路由分发等都要依赖于它)
在一台服务器上,可以启动多个mongod服务。但在实际生产部署中,通常还是建议一台服务器部署一个mongod实例,这样不仅减少资源竞争,而且服务器故障也不会同时影响到多个服务。
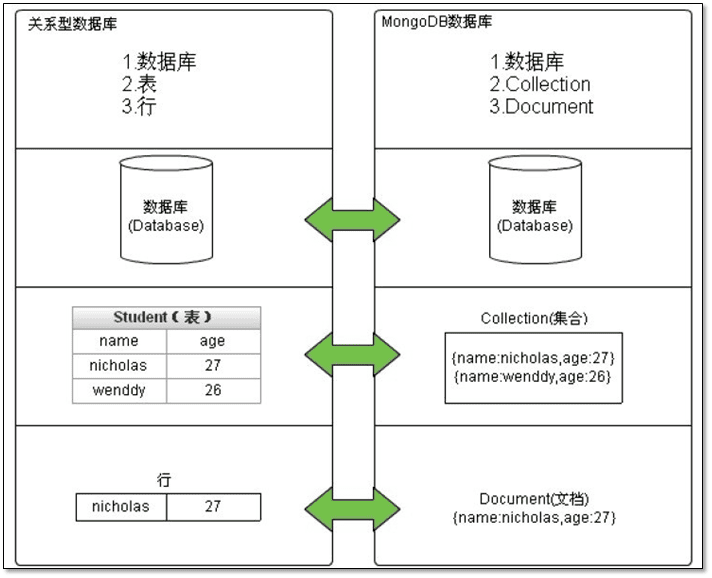
MongoDB数据逻辑结构
MongoDB 数据逻辑结构分为数据库(database)、集合(collection)、文档(document)三层 :
- 一个mongod实例中允许创建多个数据库。
- 一个数据库中允许创建多个集合(集合相当于关系型数据库的表)。
- 一个集合则是由若干个文档构成(文档相当于关系型数据库的行,是MongoDB中数据的基本单元)。
数据库
一个数据库中可以创建多个集合,原则上我们通常把逻辑相近的集合都放在一个数据库中,当然出于性能或者数据量的关系,也可能进行拆分。
在MongoDB中有几个内建的数据库:
- admin admin库主要存放有数据库帐号相关信息。
- local local数据库永远不会被复制到从节点,可以用来存储限于本地单台服务器的任意集合副本集的配置信息、oplog就存储在local库中。
- 重要的数据不要存储在local库,因为没有冗余副本,如果这个节点故障,存储在local库的数据就无法正常使用了。
- config config数据库用于分片集群环境,存放了分片相关的元数据信息。
- test MongoDB默认创建的一个测试库,连接mongod服务时,如果不指定连接的具体数据库,默认就会连接到test库。

集合
集合由若干条文档记录构成。
- 前面介绍MongoDB的时候提到过,集合是schema-less的(无模式或动态模式),这意味着集合不需要在读写数据前创建模式就可以使用,集合中的文档也可以拥有不同的字段,随时可以任意增减某个文档的字段。
- 在集合上可以对文档进行增删改查以及进行聚合操作。
- 在集合上还可以对文档中的字段创建索引。
- 除了一般的集合外,还可以创建一种叫做**定容集合(capped collection)**类型的集合,这种集合与一般集合主要的区别是,它可以限制集合的容量大小,在数据写满的时候,又可以从头开始覆盖最开始的文档进行循环写入。
- 副本集就是利用这种类型的集合作为oplog,记录primary节点上的写操作,并且同步到从节点重放,以实现主副节点数据复制的功能。
文档
文档是MongoDB中数据的基本存储单元,它以一种叫做BSON文档的结构表示。BSON,即Binary JSON,多个键及其关联的值有序地存放在其中,类似映射,散列或字典。
- 文档中的键/值对是有序的,不同序则是不同文档。并且键是区分大小写的,否则也为不同文档。
- 文档的键是字符串,而值除了字符串,还可以是int, long, double,boolean,子文档,数组等多种类型。
- 文档中不能有重复的键。
- 每个文档都有一个默认的_id键,它相当于关系型数据库中的主键,这个键的值在同一个集合中必须是唯一的,_id键值默认是ObjectId类型,在插入文档的时候,如果用户不设置文档的_id值得话,MongoDB会自动生成生成一个唯一的ObjectId值进行填充。
MongoDB数据库文件
注意
MongoDB数据库文件和MongoDB存储的引擎有直接关系,MongoDB一共提供了三种存储引擎:WiredTiger,MMAPV1和In Memory;在MongoDB3.2之前采用的是MMAPV1; 后续版本v3.2开始默认采用WiredTiger; 且在v4.2版本中移除了MMAPV1的引擎。
在后续文章中,还将对MongoDB存储引擎进行详解。
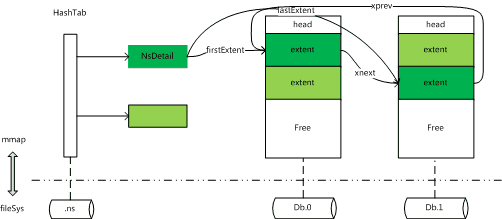
MongoDB - MMAPv1引擎下的数据库文件
由于v3.0后续版本已经弃用了,所以这里不会详细介绍。
- journal 日志文件
- namespace 表名文件
- data 数据及索引文件
db
|------journal
|----_j.0
|----_j.1
|----lsn
|------local
|----local.ns
|----local.0
|----local.1
|------mydb
|----mydb.ns
|----mydb.0
|----mydb.1
如果感兴趣可以参看 官方文档 - MMAPv1 Storage Engine
如果你希望详解了解MongoDB MMAP的引擎(源码级别),你可以参考这篇MongoDB Mmap 引擎分析
MongoDB - WiredTiger
MongoDB v3.2已经将WiredTiger设置为了默认的存储引擎

collection-*.wt存储collection的数据index-*.wt存储索引的数据WiredTiger存储基本配置信息WiredTiger.wt存储所有其它collection的元数据信息WiredTiger.lock存储进程ID,用于防止多个进程连接同一个Wiredtiger数据库WiredTiger.turtle存储WiredTiger.wt的元数据信息journal存储Write ahead log
后续的文章将对WiredTiger存储引擎进行详解。
参考文章
- https://blog.csdn.net/eagle89/article/details/80606372
- https://blog.csdn.net/iteye_19607/article/details/82643225
- https://blog.csdn.net/zhaowen25/article/details/41871383
- https://zhuanlan.zhihu.com/p/34248254