Redis进阶 - 高可拓展:分片技术(Redis Cluster)详解
前面两篇文章,主从复制和哨兵机制保障了高可用,就读写分离而言虽然slave节点扩展了主从的读并发能力,但是写能力和存储能力是无法进行扩展,就只能是master节点能够承载的上限。如果面对海量数据那么必然需要构建master(主节点分片)之间的集群,同时必然需要吸收高可用(主从复制和哨兵机制)能力,即每个master分片节点还需要有slave节点,这是分布式系统中典型的纵向扩展(集群的分片技术)的体现;所以在Redis 3.0版本中对应的设计就是Redis Cluster。@pdai
- Redis进阶 - 高可拓展:分片技术(Redis Cluster)详解
Redis 集群的设计目标
Redis-cluster是一种服务器Sharding技术,Redis3.0以后版本正式提供支持。Redis Cluster在设计时考虑了什么?我们不妨看下官网的介绍 Redis Cluster Specification
Redis Cluster goals
高性能可线性扩展至最多1000节点。集群中没有代理,(集群节点间)使用异步复制,没有归并操作(merge operations on values)
可接受的写入安全:系统尝试(采用best-effort方式)保留所有连接到master节点的client发起的写操作。通常会有一个小的时间窗,时间窗内的已确认写操作可能丢失(即,在发生failover之前的小段时间窗内的写操作可能在failover中丢失)。而在(网络)分区故障下,对少数派master的写入,发生写丢失的时间窗会很大。
可用性:Redis Cluster在以下场景下集群总是可用:大部分master节点可用,并且对少部分不可用的master,每一个master至少有一个当前可用的slave。更进一步,通过使用 replicas migration 技术,当前没有slave的master会从当前拥有多个slave的master接受到一个新slave来确保可用性。
Clients and Servers roles in the Redis Cluster protocol
Redis Cluster的节点负责维护数据,和获取集群状态,这包括将keys映射到正确的节点。集群节点同样可以自动发现其他节点、检测不工作节点、以及在发现故障发生时晋升slave节点到master
所有集群节点通过由TCP和二进制协议组成的称为 Redis Cluster Bus 的方式来实现集群的节点自动发现、故障节点探测、slave升级为master等任务。每个节点通过cluster bus连接所有其他节点。节点间使用gossip协议进行集群信息传播,以此来实现新节点发现,发送ping包以确认对端工作正常,以及发送cluster消息用来标记特定状态。cluster bus还被用来在集群中创博Pub/Sub消息,以及在接收到用户请求后编排手动failover。
Write safety
Redis Cluster在节点间采用了异步复制,以及 last failover wins 隐含合并功能(implicit merge function)(【译注】不存在合并功能,而是总是认为最近一次failover的节点是最新的)。这意味着最后被选举出的master所包含的数据最终会替代(同一前master下)所有其他备份(replicas/slaves)节点(包含的数据)。当发生分区问题时,总是会有一个时间窗内会发生写入丢失。然而,对连接到多数派master(majority of masters)的client,以及连接到少数派master(mimority of masters)的client,这个时间窗是不同的。
相比较连接到少数master(minority of masters)的client,对连接到多数master(majority of masters)的client发起的写入,Redis cluster会更努力地尝试将其保存。 下面的场景将会导致在主分区的master上,已经确认的写入在故障期间发生丢失:
写入请求达到master,但是当master执行完并回复client时,写操作可能还没有通过异步复制传播到它的slave。如果master在写操作抵达slave之前挂了,并且master无法触达(unreachable)的时间足够长而导致了slave节点晋升,那么这个写操作就永远地丢失了。通常很难直接观察到,因为master尝试回复client(写入确认)和传播写操作到slave通常几乎是同时发生。然而,这却是真实世界中的故障方式。(【译注】不考虑返回后宕机的场景,因为宕机导致的写入丢失,在单机版redis上同样存在,这不是redis cluster引入的目的及要解决的问题)
另一种理论上可能发生写入丢失的模式是:
- master因为分区原因不可用(unreachable)
- 该master被某个slave替换(failover)
- 一段时间后,该master重新可用
- 在该old master变为slave之前,一个client通过过期的路由表对该节点进行写入。
上述第二种失败场景通常难以发生,因为:
- 少数派master(minority master)无法与多数派master(majority master)通信达到一定的时间后,它将拒绝写入,并且当分区恢复后,该master在重新与多数派master建立连接后,还将保持拒绝写入状态一小段时间来感知集群配置变化。留给client可写入的时间窗很小。
- 发生这种错误还有一个前提是,client一直都在使用过期的路由表(而实际上集群因为发生了failover,已有slave发生了晋升)。
写入少数派master(minority side of a partition)会有一个更长的时间窗会导致数据丢失。因为如果最终导致了failover,则写入少数派master的数据将会被多数派一侧(majority side)覆盖(在少数派master作为slave重新接入集群后)。
特别地,如果要发生failover,master必须至少在NODE_TIMEOUT时间内无法被多数masters(majority of maters)连接,因此如果分区在这一时间内被修复,则不会发生写入丢失。当分区持续时间超过NODE_TIMEOUT时,所有在这段时间内对少数派master(minority side)的写入将会丢失。然而少数派一侧(minority side)将会在NODE_TIMEOUT时间之后如果还没有连上多数派一侧,则它会立即开始拒绝写入,因此对少数派master而言,存在一个进入不可用状态的最大时间窗。在这一时间窗之外,不会再有写入被接受或丢失。
可用性(Availability)
Redis Cluster在少数派分区侧不可用。在多数派分区侧,假设由多数派masters存在并且不可达的master有一个slave,cluster将会在NODE_TIMEOUT外加重新选举所需的一小段时间(通常1~2秒)后恢复可用。
这意味着,Redis Cluster被设计为可以忍受一小部分节点的故障,但是如果需要在大网络分裂(network splits)事件中(【译注】比如发生多分区故障导致网络被分割成多块,且不存在多数派master分区)保持可用性,它不是一个合适的方案(【译注】比如,不要尝试在多机房间部署redis cluster,这不是redis cluster该做的事)。
假设一个cluster由N个master节点组成并且每个节点仅拥有一个slave,在多数侧只有一个节点出现分区问题时,cluster的多数侧(majority side)可以保持可用,而当有两个节点出现分区故障时,只有 1-(1/(N2-1)) 的可能性保持集群可用。 也就是说,如果有一个由5个master和5个slave组成的cluster,那么当两个节点出现分区故障时,它有 1/(52-1)=11.11%的可能性发生集群不可用。
Redis cluster提供了一种成为 Replicas Migration 的有用特性特性,它通过自动转移备份节点到孤master节点,在真实世界的常见场景中提升了cluster的可用性。在每次成功的failover之后,cluster会自动重新配置slave分布以尽可能保证在下一次failure中拥有更好的抵御力。
性能(Performance)
Redis Cluster不会将命令路由到其中的key所在的节点,而是向client发一个重定向命令 (- MOVED) 引导client到正确的节点。 最终client会获得一个最新的cluster(hash slots分布)展示,以及哪个节点服务于命令中的keys,因此clients就可以获得正确的节点并用来继续执行命令。
因为master和slave之间使用异步复制,节点不需要等待其他节点对写入的确认(除非使用了WAIT命令)就可以回复client。 同样,因为multi-key命令被限制在了临近的key(near keys)(【译注】即同一hash slot内的key,或者从实际使用场景来说,更多的是通过hash tag定义为具备相同hash字段的有相近业务含义的一组keys),所以除非触发resharding,数据永远不会在节点间移动。
普通的命令(normal operations)会像在单个redis实例那样被执行。这意味着一个拥有N个master节点的Redis Cluster,你可以认为它拥有N倍的单个Redis性能。同时,query通常都在一个round trip中执行,因为client通常会保留与所有节点的持久化连接(连接池),因此延迟也与客户端操作单台redis实例没有区别。
在对数据安全性、可用性方面提供了合理的弱保证的前提下,提供极高的性能和可扩展性,这是Redis Cluster的主要目标。
避免合并(merge)操作
Redis Cluster设计上避免了在多个拥有相同key-value对的节点上的版本冲突(及合并/merge),因为在redis数据模型下这是不需要的。Redis的值同时都非常大;一个拥有数百万元素的list或sorted set是很常见的。同样,数据类型的语义也很复杂。传输和合并这类值将会产生明显的瓶颈,并可能需要对应用侧的逻辑做明显的修改,比如需要更多的内存来保存meta-data等。
这里(【译注】刻意避免了merge)并没有严格的技术限制。CRDTs或同步复制状态机可以塑造与redis类似的复杂的数据类型。然而,这类系统运行时的行为与Redis Cluster其实是不一样的。Redis Cluster被设计用来支持非集群redis版本无法支持的一些额外的场景。
主要模块介绍
Redis Cluster Specification同时还介绍了Redis Cluster中主要模块,这里面包含了很多基础和概念,我们需要先了解下。
哈希槽(Hash Slot)
Redis-cluster没有使用一致性hash,而是引入了哈希槽的概念。Redis-cluster中有16384(即2的14次方)个哈希槽,每个key通过CRC16校验后对16383取模来决定放置哪个槽。Cluster中的每个节点负责一部分hash槽(hash slot)。
比如集群中存在三个节点,则可能存在的一种分配如下:
- 节点A包含0到5500号哈希槽;
- 节点B包含5501到11000号哈希槽;
- 节点C包含11001 到 16384号哈希槽。
Keys hash tags
Hash tags提供了一种途径,用来将多个(相关的)key分配到相同的hash slot中。这时Redis Cluster中实现multi-key操作的基础。
hash tag规则如下,如果满足如下规则,{和}之间的字符将用来计算HASH_SLOT,以保证这样的key保存在同一个slot中。
- key包含一个{字符
- 并且 如果在这个{的右面有一个}字符
- 并且 如果在{和}之间存在至少一个字符
例如:
- {user1000}.following和{user1000}.followers这两个key会被hash到相同的hash slot中,因为只有user1000会被用来计算hash slot值。
- foo{}{bar}这个key不会启用hash tag因为第一个{和}之间没有字符。
- foozap这个key中的{bar部分会被用来计算hash slot
- foo{bar}{zap}这个key中的bar会被用来计算计算hash slot,而zap不会
Cluster nodes属性
每个节点在cluster中有一个唯一的名字。这个名字由160bit随机十六进制数字表示,并在节点启动时第一次获得(通常通过/dev/urandom)。节点在配置文件中保留它的ID,并永远地使用这个ID,直到被管理员使用CLUSTER RESET HARD命令hard reset这个节点。
节点ID被用来在整个cluster中标识每个节点。一个节点可以修改自己的IP地址而不需要修改自己的ID。Cluster可以检测到IP /port的改动并通过运行在cluster bus上的gossip协议重新配置该节点。
节点ID不是唯一与节点绑定的信息,但是他是唯一的一个总是保持全局一致的字段。每个节点都拥有一系列相关的信息。一些信息时关于本节点在集群中配置细节,并最终在cluster内部保持一致的。而其他信息,比如节点最后被ping的时间,是节点的本地信息。
每个节点维护着集群内其他节点的以下信息:node id, 节点的IP和port,节点标签,master node id(如果这是一个slave节点),最后被挂起的ping的发送时间(如果没有挂起的ping则为0),最后一次收到pong的时间,当前的节点configuration epoch ,链接状态,以及最后是该节点服务的hash slots。
对节点字段更详细的描述,可以参考对命令 CLUSTER NODES的描述。
CLUSTER NODES命令可以被发送到集群内的任意节点,他会提供基于该节点视角(view)下的集群状态以及每个节点的信息。
下面是一个发送到一个拥有3个节点的小集群的master节点的CLUSTER NODES输出的例子。
$ redis-cli cluster nodes
d1861060fe6a534d42d8a19aeb36600e18785e04 127.0.0.1:6379 myself - 0 1318428930 1 connected 0-1364
3886e65cc906bfd9b1f7e7bde468726a052d1dae 127.0.0.1:6380 master - 1318428930 1318428931 2 connected 1365-2729
d289c575dcbc4bdd2931585fd4339089e461a27d 127.0.0.1:6381 master - 1318428931 1318428931 3 connected 2730-4095
在上面的例子中,按顺序列出了不同的字段:
node id, address:port, flags, last ping sent, last pong received, configuration epoch, link state, slots.
Cluster总线
每个Redis Cluster节点有一个额外的TCP端口用来接受其他节点的连接。这个端口与用来接收client命令的普通TCP端口有一个固定的offset。该端口等于普通命令端口加上10000.例如,一个Redis街道口在端口6379坚挺客户端连接,那么它的集群总线端口16379也会被打开。
节点到节点的通讯只使用集群总线,同时使用集群总线协议:有不同的类型和大小的帧组成的二进制协议。集群总线的二进制协议没有被公开文档话,因为他不希望被外部软件设备用来预计群姐点进行对话。
集群拓扑
Redis Cluster是一张全网拓扑,节点与其他每个节点之间都保持着TCP连接。 在一个拥有N个节点的集群中,每个节点由N-1个TCP传出连接,和N-1个TCP传入连接。 这些TCP连接总是保持活性(be kept alive)。当一个节点在集群总线上发送了ping请求并期待对方回复pong,(如果没有得到回复)在等待足够成时间以便将对方标记为不可达之前,它将先尝试重新连接对方以刷新与对方的连接。 而在全网拓扑中的Redis Cluster节点,节点使用gossip协议和配置更新机制来避免在正常情况下节点之间交换过多的消息,因此集群内交换的消息数目(相对节点数目)不是指数级的。
节点握手
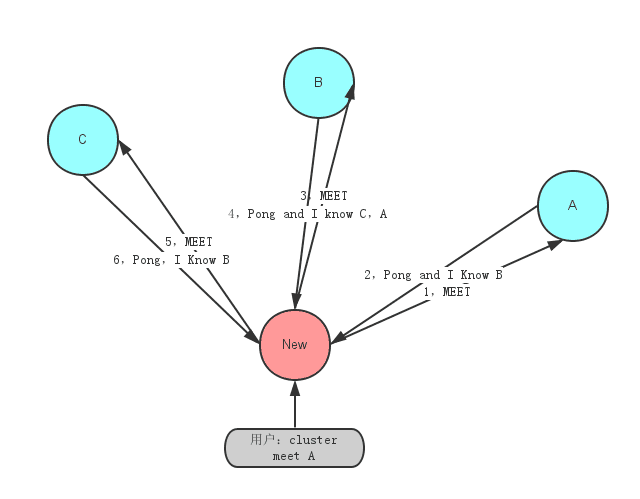
节点总是接受集群总线端口的链接,并且总是会回复ping请求,即使ping来自一个不可信节点。然而,如果发送节点被认为不是当前集群的一部分,所有其他包将被抛弃。
节点认定其他节点是当前集群的一部分有两种方式:
- 如果一个节点出现在了一条MEET消息中。一条meet消息非常像一个PING消息,但是它会强制接收者接受一个节点作为集群的一部分。节点只有在接收到系统管理员的如下命令后,才会向其他节点发送MEET消息:
CLUSTER MEET ip port
- 如果一个被信任的节点gossip了某个节点,那么接收到gossip消息的节点也会那个节点标记为集群的一部分。也就是说,如果在集群中,A知道B,而B知道C,最终B会发送gossip消息到A,告诉A节点C是集群的一部分。这时,A会把C注册未网络的一部分,并尝试与C建立连接。
这意味着,一旦我们把某个节点加入了连接图(connected graph),它们最终会自动形成一张全连接图(fully connected graph)。这意味着只要系统管理员强制加入了一条信任关系(在某个节点上通过meet命令加入了一个新节点),集群可以自动发现其他节点。
请求重定向
Redis cluster采用去中心化的架构,集群的主节点各自负责一部分槽,客户端如何确定key到底会映射到哪个节点上呢?这就是我们要讲的请求重定向。
在cluster模式下,节点对请求的处理过程如下:
- 检查当前key是否存在当前NODE?
- 通过crc16(key)/16384计算出slot
- 查询负责该slot负责的节点,得到节点指针
- 该指针与自身节点比较
- 若slot不是由自身负责,则返回MOVED重定向
- 若slot由自身负责,且key在slot中,则返回该key对应结果
- 若key不存在此slot中,检查该slot是否正在迁出(MIGRATING)?
- 若key正在迁出,返回ASK错误重定向客户端到迁移的目的服务器上
- 若Slot未迁出,检查Slot是否导入中?
- 若Slot导入中且有ASKING标记,则直接操作
- 否则返回MOVED重定向
这个过程中有两点需要具体理解下: MOVED重定向 和 ASK重定向。
Moved 重定向
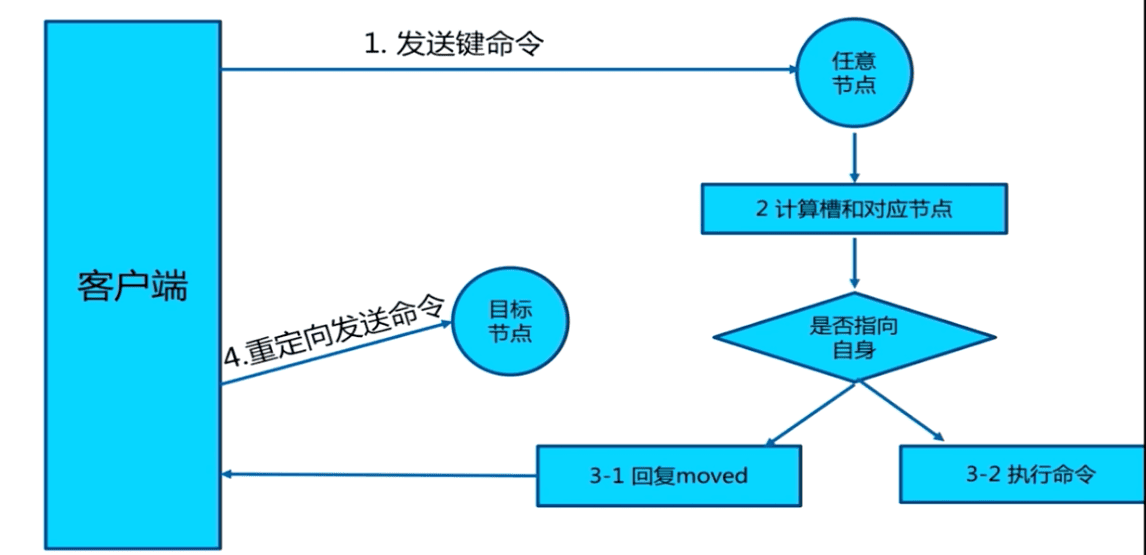
- 槽命中:直接返回结果
- 槽不命中:即当前键命令所请求的键不在当前请求的节点中,则当前节点会向客户端发送一个Moved 重定向,客户端根据Moved 重定向所包含的内容找到目标节点,再一次发送命令。
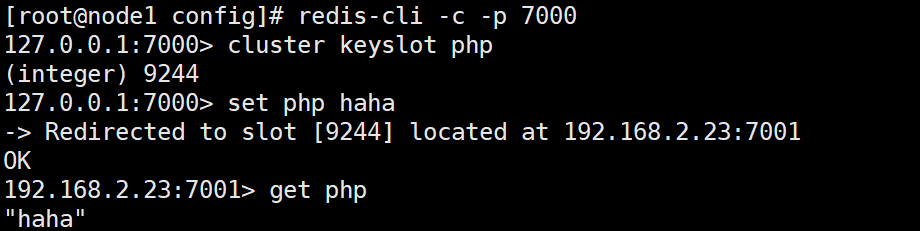
从下面可以看出 php 的槽位9244不在当前节点中,所以会重定向到节点 192.168.2.23:7001中。redis-cli会帮你自动重定向(如果没有集群方式启动,即没加参数 -c,redis-cli不会自动重定向),并且编写程序时,寻找目标节点的逻辑需要交予程序员手动完成。
cluster keyslot keyName # 得到keyName的槽
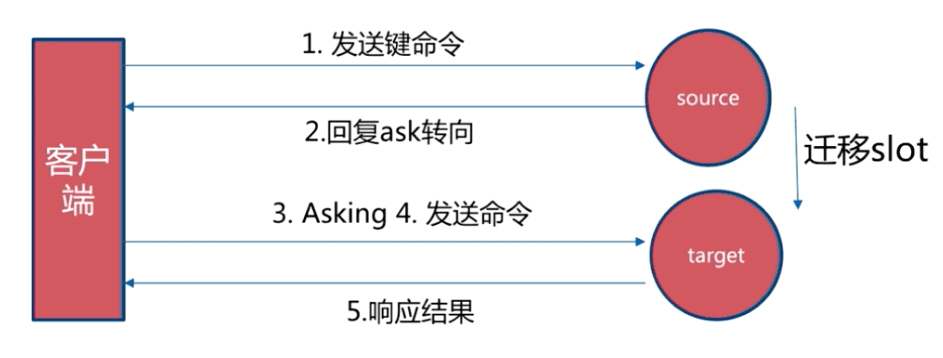
ASK 重定向
Ask重定向发生于集群伸缩时,集群伸缩会导致槽迁移,当我们去源节点访问时,此时数据已经可能已经迁移到了目标节点,使用Ask重定向来解决此种情况。
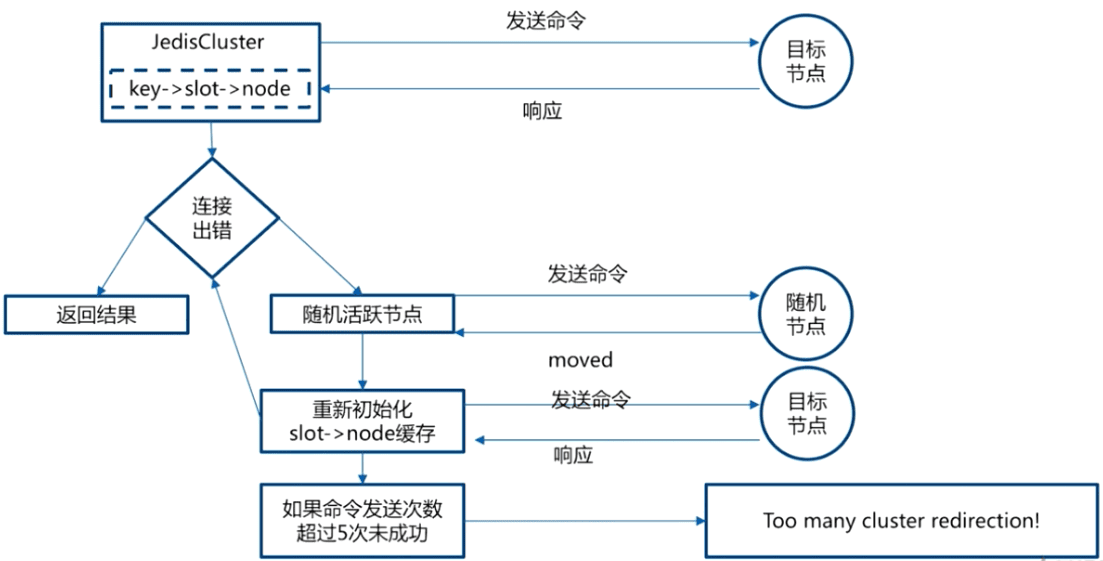
smart客户端
上述两种重定向的机制使得客户端的实现更加复杂,提供了smart客户端(JedisCluster)来减低复杂性,追求更好的性能。客户端内部负责计算/维护键-> 槽 -> 节点映射,用于快速定位目标节点。
实现原理:
- 从集群中选取一个可运行节点,使用 cluster slots得到槽和节点的映射关系
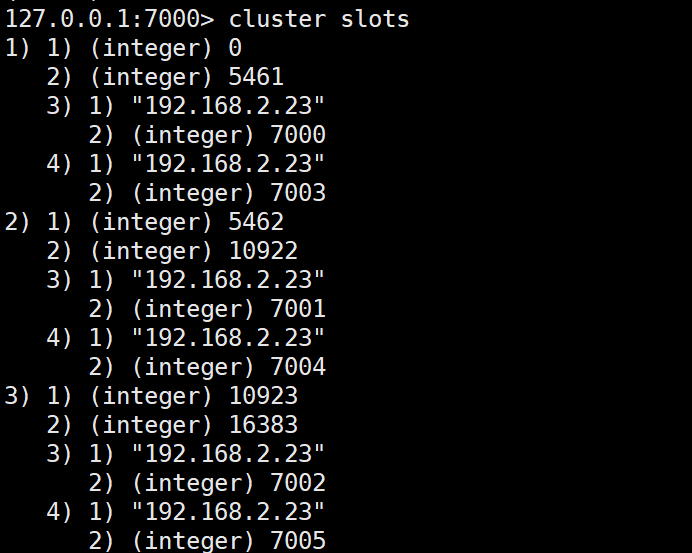
将上述映射关系存到本地,通过映射关系就可以直接对目标节点进行操作(CRC16(key) -> slot -> node),很好地避免了Moved重定向,并为每个节点创建JedisPool
至此就可以用来进行命令操作
状态检测及维护
Redis Cluster中节点状态如何维护呢?这里便涉及 有哪些状态,底层协议Gossip,及具体的通讯(心跳)机制。@pdai
Cluster中的每个节点都维护一份在自己看来当前整个集群的状态,主要包括:
- 当前集群状态
- 集群中各节点所负责的slots信息,及其migrate状态
- 集群中各节点的master-slave状态
- 集群中各节点的存活状态及不可达投票
当集群状态变化时,如新节点加入、slot迁移、节点宕机、slave提升为新Master,我们希望这些变化尽快的被发现,传播到整个集群的所有节点并达成一致。节点之间相互的心跳(PING,PONG,MEET)及其携带的数据是集群状态传播最主要的途径。
Gossip协议
Redis Cluster 通讯底层是Gossip协议,所以需要对Gossip协议有一定的了解。
gossip 协议(gossip protocol)又称 epidemic 协议(epidemic protocol),是基于流行病传播方式的节点或者进程之间信息交换的协议。 在分布式系统中被广泛使用,比如我们可以使用 gossip 协议来确保网络中所有节点的数据一样。
Gossip协议已经是P2P网络中比较成熟的协议了。Gossip协议的最大的好处是,即使集群节点的数量增加,每个节点的负载也不会增加很多,几乎是恒定的。这就允许Consul管理的集群规模能横向扩展到数千个节点。
Gossip算法又被称为反熵(Anti-Entropy),熵是物理学上的一个概念,代表杂乱无章,而反熵就是在杂乱无章中寻求一致,这充分说明了Gossip的特点:在一个有界网络中,每个节点都随机地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。每个节点可能知道所有其他节点,也可能仅知道几个邻居节点,只要这些节可以通过网络连通,最终他们的状态都是一致的,当然这也是疫情传播的特点。https://www.backendcloud.cn/2017/11/12/raft-gossip/
上面的描述都比较学术,其实Gossip协议对于我们吃瓜群众来说一点也不陌生,Gossip协议也成为流言协议,说白了就是八卦协议,这种传播规模和传播速度都是非常快的,你可以体会一下。所以计算机中的很多算法都是源自生活,而又高于生活的。
Gossip协议的使用
Redis 集群是去中心化的,彼此之间状态同步靠 gossip 协议通信,集群的消息有以下几种类型:
Meet通过「cluster meet ip port」命令,已有集群的节点会向新的节点发送邀请,加入现有集群。Ping节点每秒会向集群中其他节点发送 ping 消息,消息中带有自己已知的两个节点的地址、槽、状态信息、最后一次通信时间等。Pong节点收到 ping 消息后会回复 pong 消息,消息中同样带有自己已知的两个节点信息。Fail节点 ping 不通某节点后,会向集群所有节点广播该节点挂掉的消息。其他节点收到消息后标记已下线。
基于Gossip协议的故障检测
集群中的每个节点都会定期地向集群中的其他节点发送PING消息,以此交换各个节点状态信息,检测各个节点状态:在线状态、疑似下线状态PFAIL、已下线状态FAIL。
自己保存信息:当主节点A通过消息得知主节点B认为主节点D进入了疑似下线(PFAIL)状态时,主节点A会在自己的clusterState.nodes字典中找到主节点D所对应的clusterNode结构,并将主节点B的下线报告添加到clusterNode结构的fail_reports链表中,并后续关于结点D疑似下线的状态通过Gossip协议通知其他节点。
一起裁定:如果集群里面,半数以上的主节点都将主节点D报告为疑似下线,那么主节点D将被标记为已下线(FAIL)状态,将主节点D标记为已下线的节点会向集群广播主节点D的FAIL消息,所有收到FAIL消息的节点都会立即更新nodes里面主节点D状态标记为已下线。
最终裁定:将 node 标记为 FAIL 需要满足以下两个条件:
- 有半数以上的主节点将 node 标记为 PFAIL 状态。
- 当前节点也将 node 标记为 PFAIL 状态。
通讯状态和维护
我们理解了Gossip协议基础后,就可以进一步理解Redis节点之间相互的通讯心跳(PING,PONG,MEET)实现和维护了。我们通过几个问题来具体理解。
什么时候进行心跳?
Redis节点会记录其向每一个节点上一次发出ping和收到pong的时间,心跳发送时机与这两个值有关。通过下面的方式既能保证及时更新集群状态,又不至于使心跳数过多:
- 每次Cron向所有未建立链接的节点发送ping或meet
- 每1秒从所有已知节点中随机选取5个,向其中上次收到pong最久远的一个发送ping
- 每次Cron向收到pong超过timeout/2的节点发送ping
- 收到ping或meet,立即回复pong
发送哪些心跳数据?
- Header,发送者自己的信息
- 所负责slots的信息
- 主从信息
- ip port信息
- 状态信息
- Gossip,发送者所了解的部分其他节点的信息
- ping_sent, pong_received
- ip, port信息
- 状态信息,比如发送者认为该节点已经不可达,会在状态信息中标记其为PFAIL或FAIL
如何处理心跳?
1,新节点加入
- 发送meet包加入集群
- 从pong包中的gossip得到未知的其他节点
- 循环上述过程,直到最终加入集群
2,Slots信息
- 判断发送者声明的slots信息,跟本地记录的是否有不同
- 如果不同,且发送者epoch较大,更新本地记录
- 如果不同,且发送者epoch小,发送Update信息通知发送者
3,Master slave信息
发现发送者的master、slave信息变化,更新本地状态
4,节点Fail探测(故障发现)
- 超过超时时间仍然没有收到pong包的节点会被当前节点标记为PFAIL
- PFAIL标记会随着gossip传播
- 每次收到心跳包会检测其中对其他节点的PFAIL标记,当做对该节点FAIL的投票维护在本机
- 对某个节点的PFAIL标记达到大多数时,将其变为FAIL标记并广播FAIL消息
注:Gossip的存在使得集群状态的改变可以更快的达到整个集群。每个心跳包中会包含多个Gossip包,那么多少个才是合适的呢,redis的选择是N/10,其中N是节点数,这样可以保证在PFAIL投票的过期时间内,节点可以收到80%机器关于失败节点的gossip,从而使其顺利进入FAIL状态。
将信息广播给其它节点?
当需要发布一些非常重要需要立即送达的信息时,上述心跳加Gossip的方式就显得捉襟见肘了,这时就需要向所有集群内机器的广播信息,使用广播发的场景:
- 节点的Fail信息:当发现某一节点不可达时,探测节点会将其标记为PFAIL状态,并通过心跳传播出去。当某一节点发现这个节点的PFAIL超过半数时修改其为FAIL并发起广播。
- Failover Request信息:slave尝试发起FailOver时广播其要求投票的信息
- 新Master信息:Failover成功的节点向整个集群广播自己的信息
故障恢复(Failover)
master节点挂了之后,如何进行故障恢复呢?
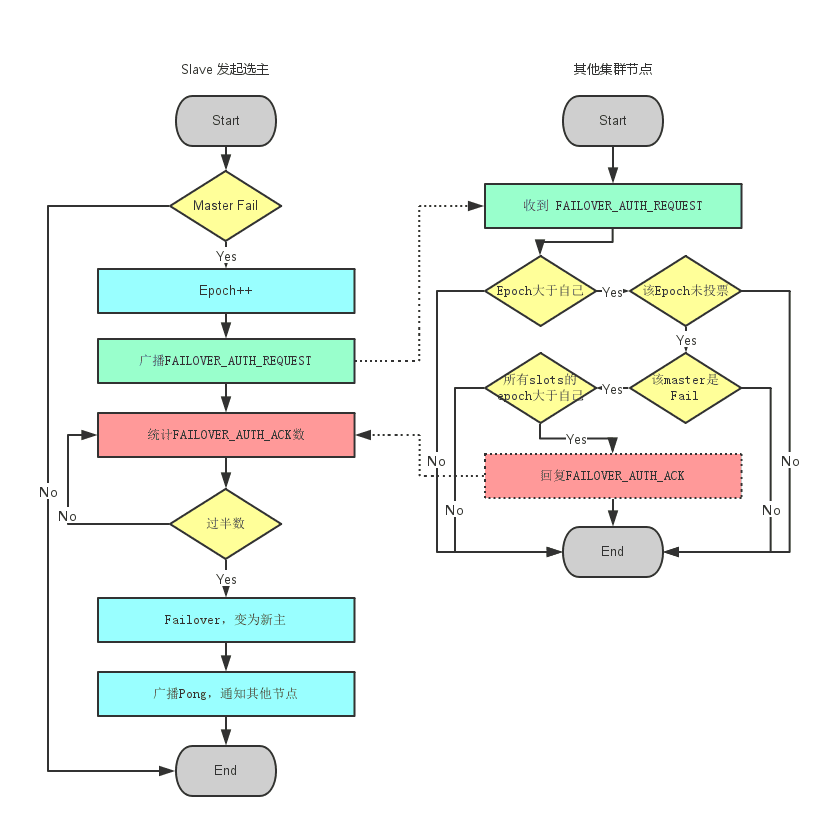
当slave发现自己的master变为FAIL状态时,便尝试进行Failover,以期成为新的master。由于挂掉的master可能会有多个slave。Failover的过程需要经过类Raft协议的过程在整个集群内达到一致, 其过程如下:
- slave发现自己的master变为FAIL
- 将自己记录的集群currentEpoch加1,并广播Failover Request信息
- 其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack
- 尝试failover的slave收集FAILOVER_AUTH_ACK
- 超过半数后变成新Master
- 广播Pong通知其他集群节点
扩容&缩容
Redis Cluster是如何进行扩容和缩容的呢?
扩容
当集群出现容量限制或者其他一些原因需要扩容时,redis cluster提供了比较优雅的集群扩容方案。
首先将新节点加入到集群中,可以通过在集群中任何一个客户端执行cluster meet 新节点ip:端口,或者通过redis-trib add node添加,新添加的节点默认在集群中都是主节点。
迁移数据 迁移数据的大致流程是,首先需要确定哪些槽需要被迁移到目标节点,然后获取槽中key,将槽中的key全部迁移到目标节点,然后向集群所有主节点广播槽(数据)全部迁移到了目标节点。直接通过redis-trib工具做数据迁移很方便。 现在假设将节点A的槽10迁移到B节点,过程如下:
B:cluster setslot 10 importing A.nodeId
A:cluster setslot 10 migrating B.nodeId
循环获取槽中key,将key迁移到B节点
A:cluster getkeysinslot 10 100
A:migrate B.ip B.port "" 0 5000 keys key1[ key2....]
向集群广播槽已经迁移到B节点
cluster setslot 10 node B.nodeId
缩容
缩容的大致过程与扩容一致,需要判断下线的节点是否是主节点,以及主节点上是否有槽,若主节点上有槽,需要将槽迁移到集群中其他主节点,槽迁移完成之后,需要向其他节点广播该节点准备下线(cluster forget nodeId)。最后需要将该下线主节点的从节点指向其他主节点,当然最好是先将从节点下线。
更深入理解
通过几个例子,再深入理解Redis Cluster
为什么Redis Cluster的Hash Slot 是16384?
我们知道一致性hash算法是2的16次方,为什么hash slot是2的14次方呢?作者原始回答
在redis节点发送心跳包时需要把所有的槽放到这个心跳包里,以便让节点知道当前集群信息,16384=16k,在发送心跳包时使用char进行bitmap压缩后是2k(2 * 8 (8 bit) * 1024(1k) = 16K),也就是说使用2k的空间创建了16k的槽数。
虽然使用CRC16算法最多可以分配65535(2^16-1)个槽位,65535=65k,压缩后就是8k(8 * 8 (8 bit) * 1024(1k) =65K),也就是说需要需要8k的心跳包,作者认为这样做不太值得;并且一般情况下一个redis集群不会有超过1000个master节点,所以16k的槽位是个比较合适的选择。
为什么Redis Cluster中不建议使用发布订阅呢?
在集群模式下,所有的publish命令都会向所有节点(包括从节点)进行广播,造成每条publish数据都会在集群内所有节点传播一次,加重了带宽负担,对于在有大量节点的集群中频繁使用pub,会严重消耗带宽,不建议使用。(虽然官网上讲有时候可以使用Bloom过滤器或其他算法进行优化的)
其它常见方案
还有一些方案出现在历史舞台上,我挑了几个经典的。简单了解下,增强下关联的知识体系。@pdai
Redis Sentinel 集群 + Keepalived/Haproxy
底层是 Redis Sentinel 集群,代理着 Redis 主从,Web 端通过 VIP 提供服务。当主节点发生故障,比如机器故障、Redis 节点故障或者网络不可达,Redis 之间的切换通过 Redis Sentinel 内部机制保障,VIP 切换通过 Keepalived 保障。
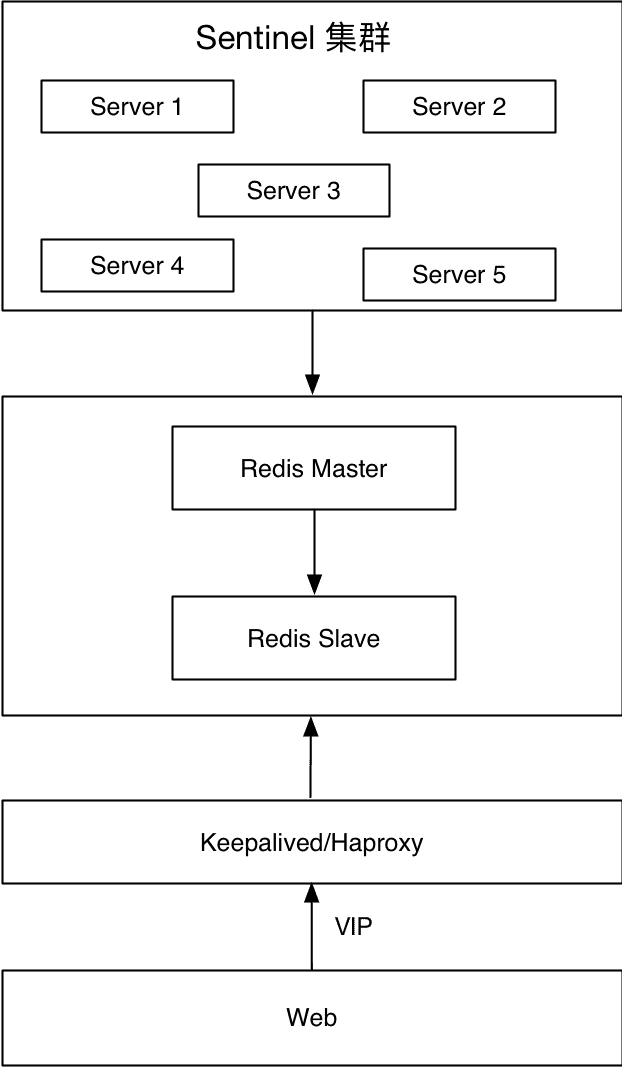
优点:
- 秒级切换
- 对应用透明
缺点:
- 维护成本高
- 存在脑裂
- Sentinel 模式存在短时间的服务不可用
Twemproxy
多个同构 Twemproxy(配置相同)同时工作,接受客户端的请求,根据 hash 算法,转发给对应的 Redis。
Twemproxy 方案比较成熟了,但是效果并不是很理想。一方面是定位问题比较困难,另一方面是它对自动剔除节点的支持不是很友好。

优点:
- 开发简单,对应用几乎透明
- 历史悠久,方案成熟
缺点:
- 代理影响性能
- LVS 和 Twemproxy 会有节点性能瓶颈
- Redis 扩容非常麻烦
- Twitter 内部已放弃使用该方案,新使用的架构未开源
Codis
Codis 是由豌豆荚开源的产品,涉及组件众多,其中 ZooKeeper 存放路由表和代理节点元数据、分发 Codis-Config 的命令;Codis-Config 是集成管理工具,有 Web 界面供使用;Codis-Proxy 是一个兼容 Redis 协议的无状态代理;Codis-Redis 基于 Redis 2.8 版本二次开发,加入 slot 支持,方便迁移数据。
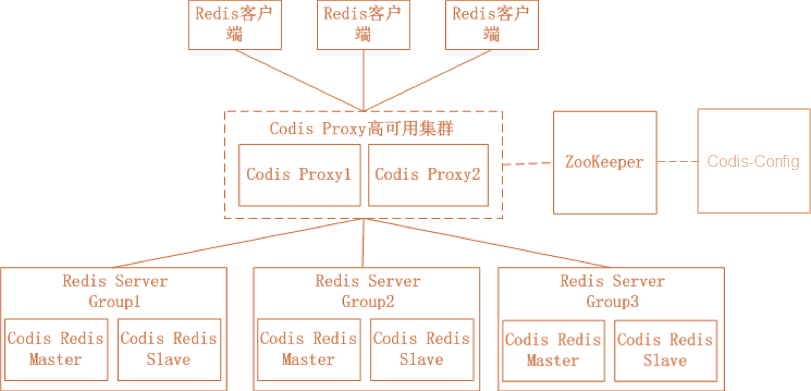
优点:
- 开发简单,对应用几乎透明
- 性能比 Twemproxy 好
- 有图形化界面,扩容容易,运维方便
缺点:
- 代理依旧影响性能
- 组件过多,需要很多机器资源
- 修改了 Redis 代码,导致和官方无法同步,新特性跟进缓慢
- 开发团队准备主推基于 Redis 改造的 reborndb
参考文章
- https://redis.io/topics/cluster-tutorial
- https://www.linuxprobe.com/redis-high-availability.html
部分章节参考了
- https://www.jianshu.com/p/2b5c9efdfea6
- https://www.jianshu.com/p/87e06d81b597
- https://www.jianshu.com/p/bb857f883ccb
- https://zhuanlan.zhihu.com/p/92937061
一些具体的实践可以参考
https://www.cnblogs.com/kismetv/p/9853040.html