Mongo进阶 - WT引擎:checkpoint原理
Checkpoint主要有两个目的: 一是将内存里面发生修改的数据写到数据文件进行持久化保存,确保数据一致性;二是实现数据库在某个时刻意外发生故障,再次启动时,缩短数据库的恢复时间,WiredTiger存储引擎中的Checkpoint模块就是来实现这个功能的。@pdai
为什么要理解Checkpoint
总的来说,Checkpoint主要有两个目的:
- 一是将内存里面发生修改的数据写到数据文件进行持久化保存,确保数据一致性;
- 二是实现数据库在某个时刻意外发生故障,再次启动时,缩短数据库的恢复时间,WiredTiger存储引擎中的Checkpoint模块就是来实现这个功能的。
Checkpoint包含的关键信息
本质上来说,Checkpoint相当于一个日志,记录了上次Checkpoint后相关数据文件的变化。
一个Checkpoint包含关键信息如下图所示:
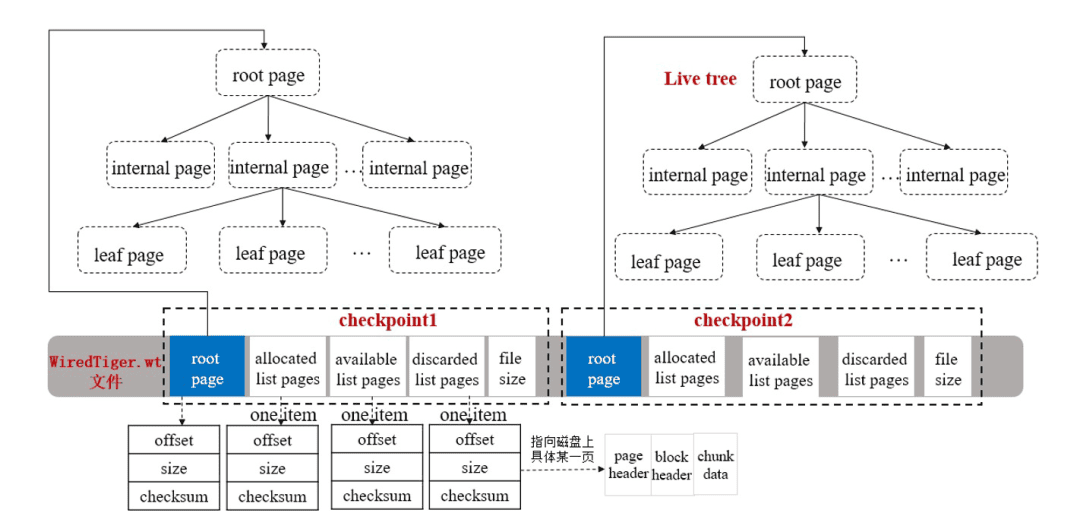
每个checkpoint包含一个root page、三个指向磁盘具体位置上pages的列表以及磁盘上文件的大小。
我们可以通过WiredTiger提供的wt命令工具(工具需要单独编译,下一篇会讲解如何编译安装wt工具)查看每个checkpoints具体信息。
例如,在dbPath指定的data目录下执行如下命令:
wt list -c
输出集合对应数据文件和索引文件的checkpoints信息:
如数据文件file:collection-7-16963667508695721.wt的checkpoint信息:
WiredTigerCheckpoint.1:Sat Apr 11 08:35:59 2020 (size 8 KB)
file-size: 16 KB, checkpoint-size: 4 KB
offset, size, checksum
root : 8192, 4096, 3824871989 (0xe3faea35)
alloc : 12288, 4096, 4074814944 (0xf2e0bde0)
discard : 0, 0, 0 (0)
avail : 0, 0, 0 (0)
如索引文件file:index-8-16963667508695721.wt的checkpoint信息:
WiredTigerCheckpoint.1:Sat Apr 11 08:35:59 2020 (size 8 KB)
file-size: 16 KB, checkpoint-size: 4 KB
offset, size, checksum
root : 8192, 4096, 997122142 (0x3b6ee05e)
alloc : 12288, 4096, 4074814944 (0xf2e0bde0)
discard : 0, 0, 0 (0)
avail : 0, 0, 0 (0)
详细字段信息描述如下:
- root page:
包含rootpage的大小(size),在文件中的位置(offset),校验和(checksum),创建一个checkpoint时,会生成一个新root page。
- allocated list pages:
用于记录最后一次checkpoint之后,在这次checkpoint执行时,由WiredTiger块管理器新分配的pages,会记录每个新分配page的size,offset和checksum。
- discarded list pages:
用于记录最后一次checkpoint之后,在这次checkpoint执行时,丢弃的不在使用的pages,会记录每个丢弃page的size,offset和checksum。
- available list pages:
在这次checkpoint执行时,所有由WiredTiger块管理器分配但还没有被使用的pages;当删除一个之前创建的checkpoint时,它所附带的可用pages将合并到最新的这个checkpoint的可用列表上,也会记录每个可用page的size,offset和checksum。
- file size: 在这次checkpoint执行后,磁盘上数据文件的大小。
Checkpoint执行的完整流程
Checkpoint是数据库中一个比较耗资源的操作,何时触发执行以及以什么样的流程执行是本节要研究的内容,如下所述:
执行流程:
一个checkpoint典型执行流程如下图所述:
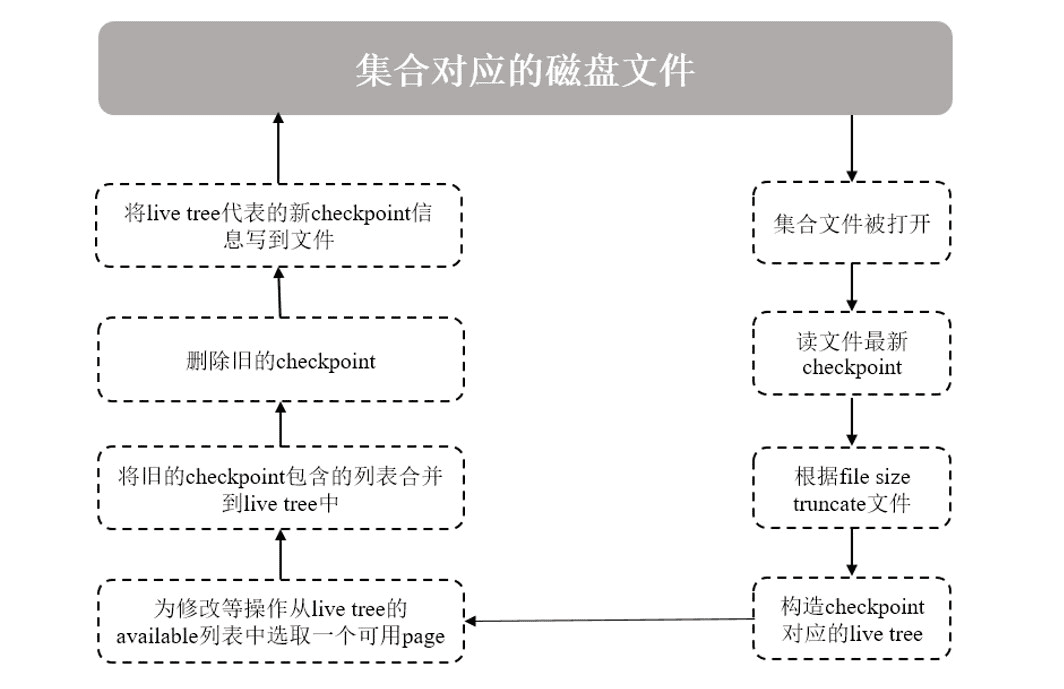
流程描述如下:
查询集合数据时,会打开集合对应的数据文件并读取其最新checkpoint数据;
集合文件会按checkponit信息指定的大小(file size)被truncate掉,所以系统发生意外故障,恢复时可能会丢失checkponit之后的数据(如果没有开启Journal);
在内存构造一棵包含root page的live tree,表示这是当前可以修改的checkpoint结构,用来跟踪后面写操作引起的文件变化;其它历史的checkpoint信息只能读,可以被删除;
内存里面的page随着增删改查被修改后,写入并需分配新的磁盘page时,将会从livetree中的available列表中选取可用的page供其使用。随后,这个新的page被加入到checkpoint的allocated列表中;
如果一个checkpoint被删除时,它所包含的allocated和discarded两个列表信息将被合并到最新checkpoint的对应列表上;任何不再需要的磁盘pages,也会将其引用添加到live tree的available列表中;
当新的checkpoint生成时,会重新刷新其allocated、available、discard三个列表中的信息,并计算此时集合文件的大小以及rootpage的位置、大小、checksum等信息,将这些信息作checkpoint元信息写入文件;
生成的checkpoint默认名称为WiredTigerCheckpoint,如果不明确指定其它名称,则新check point将自动取代上一次生成的checkpoint。
Checkpoint执行的触发时机
触发checkpoint执行,通常有如下几种情况:
- 按一定时间周期:默认60s,执行一次checkpoint;
- 按一定日志文件大小:当Journal日志文件大小达到2GB(如果已开启),执行一次checkpoint;
- 任何打开的数据文件被修改,关闭时将自动执行一次checkpoint。
注意:checkpoint是一个相当重量级的操作,当对集合文件执行checkpoint时,会在文件上获得一个排它锁,其它需要等待此锁的操作,可能会出现EBUSY的错误。
参考文章
- 文章来源
- 作者:郭远威
- MongoDB中文社区委员,长沙分会主席;《大数据存储MongoDB实战指南》作者资深大数据架构师,通信行业业务架构与数据迁移专家