大数据处理 - 外(磁盘文件)排序
在编程珠玑中,描述了三种外部磁盘文件排序的解决方法,分别是
- 位图排序法 - 在待排序文件中不含重复数的情况下,位图排序法是最高效的
- 外排多路归并法 - 在更一般的情况下,外排多路归并法具有通用性
- 多通道排序法 所以本文主要介绍前两种。@pdai
外排序介绍
外排序, 即借助外部存储进行排序.
适用范围: 大数据的排序,去重基本原理及要点: 外排序的归并方法,置换选择败者树原理,最优归并树
相关问题引入和方案
问题描述如下:
- 输入:一个最多含有n个不重复的正整数(也就是说可能含有少于n个不重复正整数)的文件,其中每个数都小于等于n,且n=10^7(1000万个)。
- 输出:得到按从小到大升序排列的包含所有输入的整数的列表。
- 条件:最多有大约1MB的内存空间可用,但磁盘空间足够。且要求运行时间在5分钟以下,10秒为最佳结果。
在编程珠玑中,描述了三种解决方法,分别是
- 位图排序法 - 在待排序文件中不含重复数的情况下,位图排序法是最高效的
- 外排多路归并法 - 在更一般的情况下,外排多路归并法具有通用性
- 多通道排序法
所以本文主要介绍前两种。
位图排序法
熟悉位图的朋友可能会想到用位图来表示这个文件集合。例如正如编程珠玑一书上所述,用一个20位长的字符串来表示一个所有元素都小于20的简单的非负整数集合,边框用如下字符串来表示集合{1,2,3,5,8,13}:0 1 1 1 0 1 0 0 1 0 0 0 0 1 0 0 0 0 0 0;上述集合中各数对应的位置则置1,没有对应的数的位置则置0。
参考编程珠玑一书上的位图方案,针对我们的10^7个数据量的磁盘文件排序问题,我们可以这么考虑,由于每个7位十进制整数表示一个小于1000万的整数。我们可以使用一个具有1000万个位的字符串来表示这个文件,其中,当且仅当整数i在文件中存在时,第i位为1。采取这个位图的方案是因为我们面对的这个问题的特殊性:
- 1、输入数据限制在相对较小的范围内
- 2、数据没有重复,
- 3、其中的每条记录都是单一的整数,没有任何其它与之关联的数据。
所以,此问题用位图的方案分为以下三步进行解决:
- 第一步,将所有的位都置为0,从而将集合初始化为空。
- 第二步,通过读入文件中的每个整数来建立集合,将每个对应的位都置为1。
- 第三步,检验每一位,如果该位为1,就输出对应的整数。
经过以上三步后,产生有序的输出文件。令n为位图向量中的位数(本例中为1000 0000),程序可以用伪代码表示如下:
//磁盘文件排序位图方案的伪代码
//copyright@ Jon Bentley
//July、updated,2011.05.29。
//第一步,将所有的位都初始化为0
for i ={0,....n}
bit[i]=0;
//第二步,通过读入文件中的每个整数来建立集合,将每个对应的位都置为1。
for each i in the input file
bit[i]=1;
//第三步,检验每一位,如果该位为1,就输出对应的整数。
for i={0...n}
if bit[i]==1
write i on the output file
上述的位图方案,共需要扫描输入数据两次,具体执行步骤如下:
- 第一次,只处理1—4999999之间的数据,这些数都是小于5000000的,对这些数进行位图排序,只需要约5000000/8=625000Byte,也就是0.625M,排序后输出。
- 第二次,扫描输入文件时,只处理4999999-10000000的数据项,也只需要0.625M(可以使用第一次处理申请的内存)。
因此,总共也只需要0.625M
位图的的方法有必要强调一下,就是位图的适用范围为针对不重复的数据进行排序,若数据有重复,位图方案就不适用了。
多路归并排序
首先我们需要回顾下,什么是归并排序,请参考:排序 - 归并排序(Merge Sort)
相对于多路归并排序,归并排序的本质是二路归并排序;我们已经知道,当数据量大到不适合在内存中排序时,可以利用多路归并算法对磁盘文件进行排序。
我们以一个包含很多个整数的大文件为例,来说明多路归并的外排序算法基本思想。假设文件中整数个数为N(N是亿级的),整数之间用空格分开。首先分多次从该文件中读取M(十万级)个整数,每次将M个整数在内存中使用内部排序之后存入临时文件,这样就得到多个外部文件,对应于多个外部文件,我们可以利用多路归并将各个临时文件中的数据一边读入内存,一边进行归并输出到输出文件。显然,该排序算法需要对每个整数做2次磁盘读和2次磁盘写。(如果根据初始外部文件的个数设置归并的路数,则会对每个整数做多次读/写,具体次数可参考严蔚敏书籍)
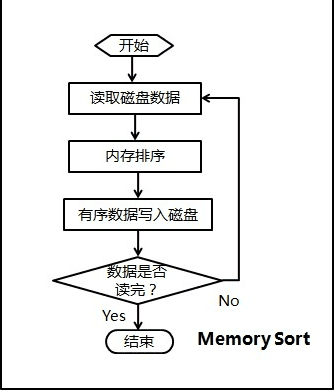
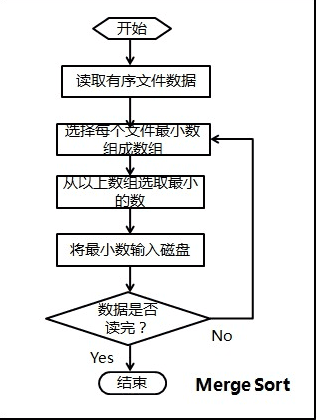
我们来编程实现上述磁盘文件排序的问题,代码思路对应上面图由两部分构成:
内存排序
- 由于要求的可用内存为1MB,那么每次可以在内存中对250K的数据进行排序,然后将有序的数写入硬盘。
- 那么10M的数据需要循环40次,最终产生40个有序的文件。
归并排序
- 将每个文件最开始的数读入(由于有序,所以为该文件最小数),存放在一个大小为40的first_data数组中;
- 选择first_data数组中最小的数min_data,及其对应的文件索引index;
- 将first_data数组中最小的数写入文件result,然后更新数组first_data(根据index读取该文件下一个数代替min_data);
- 判断是否所有数据都读取完毕,否则返回2。
参考文章
其中涉及的算法和具体的实现,请参看如下文章:
- https://blog.csdn.net/v_JULY_v/article/details/7382693
- https://www.cnblogs.com/harryshayne/archive/2011/07/02/2096196.html
再次推荐下CSDN博主July,博客专注面试、算法、机器学习。